Семантика в яндекс.директе: этапы, инструменты, чек-лист по оптимизации
Содержание:
- Принцип работы онлайн-сервисов
- Удаляем слова с нулевой частотностью
- Расширения для браузера Яндекс Wordstat
- Упущенные ключевые фразы
- Что можно делать с помощью SQL запросов
- Для чего нужно семантическое ядро
- Что такое конкурентность запроса?
- SpyWords
- Анализ ключевых фраз
- Брендовая семантика
- Онлайн-сервисы
- Как собирать ключи для СЯ
- Яндекс Wordstat
- Особенности сбора семантики по видам проектов
- Способы восстановления данных с поврежденного HDD
- Простое мобильное приложение, информирующее об остатках на складах и ценах по штрихкоду, для 1С: УНФ, Розница, УТ 11
- СловоЁБ
- Букварикс
- А может, лучше заказать составление семантического ядра сайта?
Принцип работы онлайн-сервисов
Если вы думаете, что онлайн-сервисы имеют доступ к прямой статистике сайтов, то спешу вас огорчить. Алгоритм работы у них, ровно как и у программ для составления семантики, совершенно другой. Он заключается в периодическом сборе информации с поисковых систем. После этого она заносится в базу, которая и выдается пользователям таких инструментов.
Стоит отметить, что если сервис для анализа конкурентов очень редко обновляет свои базы, то, вероятнее всего, вы получите устаревшую информацию, от которой будет мало пользы. Исключением могут являться сайты, у которых вся статистика находится в открытом доступе.
Удаляем слова с нулевой частотностью
Для целей контекстной рекламы слова с околонулевой частотностью не представляют интереса, поскольку по ним не будет показов. Такие слова лучше сразу удалить.
Для проверки частотности большого массива ключей в Click.ru есть парсер Wordstat. Он собирает частотности из левой колонки Wordstat. Он парсит частотность в любом регионе Яндекса и учитывает тип соответствия ключевых слов.
Как пользоваться инструментом
Перейдите на страницу инструмента. Добавьте запросы.
Выберите регион, по которому инструмент будет парсить частотности.
Укажите параметры сбора частотности. Инструмент собирает частотности по запросам в широком соответствии, фиксирует количество слов и морфологию, фиксирует порядок слов.
Для запуска задачи нажмите кнопку «Запустить проверку». Время сбора зависит от количества запросов, регионов и типов соответствия.
Отчет доступен в списке задач в формате XLSX.
В отчете указывается частотность запросов в разных типах соответствия. Удалите слова с нулевой и околонулевой частотностью.
Важно! Будьте внимательны с ключевыми словами, связанными с сезонными товарами/услугами. В Вордстате статистика собирается за последний месяц, поэтому если сейчас в вашей нише спад, частотность будет низкой
Детально об анализе частотности в Вордстате мы писали здесь. Также вам может помочь сервис Google Trends. Как с ним работать, тоже рассказывали.
После удаления «нулевок» можно приступать к группировке слов.
Расширения для браузера Яндекс Wordstat
Использовать Яндекс Wordstat по старинке, то есть копипастить подходящие запросы – вчерашний день. Использование бесплатных расширений для браузера дает гораздо больше возможностей.
Рассмотрим основные из них на примере плагина Wordstat Assistant. После установки его панель управления находится в левой области страницы Яндекс Wordstat.
Итак, плагины Вордстата позволяют:
1) Формировать собственный список ключей, отбирая из выдачи Вордстата нужные в пару кликов.
Знаком «+» около каждого результата вы добавляете фразу в свой список. Кликом по кнопке «Добавить все» – все фразы со страницы выдачи, на которой сейчас вы находитесь:
Удалить фразы можно из результатов поиска Яндекс Wordstat (1) или прямо из панели управления (2). Либо крестиком вверху панели управления (3), если нужно очистить весь список:
2) Видеть автоматически рассчитанное количество фраз и частотность по списку благодаря встроенным счетчикам;
3) Добавлять собственные ключи:
Правда, частотность для них не подтягивается из данных Вордстата, а обозначается знаком вопроса.
4) Сортировать список ключей по частотности, алфавиту и порядку добавления.
5) Сохранять список в аккаунте Яндекса и редактировать при повторном открытии.
Более сложный плагин – WordStater. Он поддерживает все базовые функции, плюс свои уникальные вещи.
WordStater включает три вкладки:
1) Общий список из результатов Wordstat;
2) Список минус-слов;
3) Без минусов и дублей – список фраз, отфильтрованный от минус-слов.
В верхней строке плагина вы видите общее количество собранных фраз (1) и можете найти конкретную фразу в списке (2):
Теперь – об уникальных возможностях WordStater, связанных со сбором семантики.
1) Полуавтоматический сбор – с помощью специальных горячих клавиш:
- Ctrl+Shift+A – для добавления ключей с текущей страницы;
- Ctrl+Shift+(стрелка вправо) – со следующей, и т.д.
Так вы быстрее соберете много фраз, однако есть риск «схватить» за это капчу.
2) Исключение из выдачи Вордстата ранее минус-слов, заданных вручную или собранных из выдачи.
Активируйте минусацию, откройте вкладку «Сбор минус-слов»:
Или исключите слова прямо в выдаче Вордстата:
3) Генерация ключевых фраз в «Комбинаторе слов»:
Работает она по принципу перемножения:
Подробнее об этих и других возможностях расширений Яндекс Вордстат смотрите здесь.
Упущенные ключевые фразы
Напоследок я расскажу еще об одной возможности Serpstat – упущенные ключевые фразы. Принцип таков: вы выбираете страницу вашего сайта, которую хотите продвинуть в выдаче, и анализируете ее через seo-платформу. Можно начать с главной страницы сервиса.
На странице с суммарным отчетом найдите раздел Упущенные ключевые фразы.
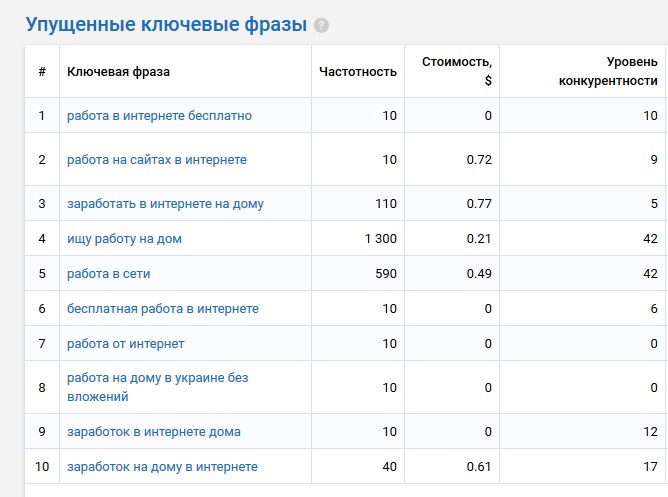
Это те фразы, которые есть у ваших конкурентов, но нет у вас. Добавьте их в свое семантическое ядро. За счет дополнительных ключевиков ваш сайт продвинется в поиске.
Итак, друзья, сегодня мы разобрали один из инструментов платформы Serpstat – анализ ключевых фраз. Я точно могу сказать, что с этим сервисом будет удобно работать даже новичкам – ведь он не требует никаких дополнительных настроек. В помощь вам эта статья.
Кроме того, на начальном этапе анализ ключевых фраз поможет составить правильное семантическое ядро для вашего ресурса, что будет причиной эффективного продвижения сайта в интернете.
Обязательно пользуйтесь другими инструментами Serpstat: анализ сайта, анализ обратных ссылок, мониторинг позиций и т.д. От этого будет расти качество вашего ресурса – и это точно понравится и пользователям и поисковым системам.
Больше подробностей в моем видеообзоре:
Автор статьи Ольга Абрамова, Денежные ручейки
Что можно делать с помощью SQL запросов
Для чего нужно семантическое ядро
На этом этапе логично перейти к вопросу составления семантического ядра. Однако давайте сначала посмотрим, зачем нужно семантическое ядро. Понимание, что делать с собранной семантикой позволит понять смысл проводимых работ и избежать целого ряда ошибок.
Итак, в процессе разработки семантического ядра у нас формируется список ключевых слов и фраз. Чем больше синонимов, профессионализмов, вариантов написания терминов, сокращений, аббревиатур мы учтем, тем лучше мы сможем:
- продумать, сформировать и доработать структуру сайта;
- сформировать удачный контент для пользователя;
- использовать ключевые слова для настройки мета-тегов, текстовых корректировок, рерайта и написания текстов с нуля, анкоров внутренних и внешних ссылок.
Формирование семантического ядра представляет собой процесс не просто сбора списка слов. Каждому из этих слов соответствуют определенные параметры, которые нужно учитывать для разных задач продвижения:
- Частотность запроса (по Яндекс.Вордстат)
- Позиции в поиске (обычно смотрят не дальше ТОП100, если запроса нет в первой сотне, то всем остальным присваивается значение 101)
- Продвигаемая страница (URL)
- Ранжируемая страница (та, которую находит поисковик; по факту может отличаться от продвигаемой, что может указывать на проблемы ранжирования сайта по данному запросу)
Такое представление данных позволяет сразу увидеть следующие проблемы:
- нет подходящей страницы под запрос, нужно создать новую
- есть только общие страницы, нужна новая под данный запрос
- какова динамика продвижения как по конкретным запросам, так и по продвигаемым страницам в целом
- какова динамика продвижения высоко-, средне- и низкочастотных запросов
- соответствуют ли продвигаемые и ранжируемые станицы, является ли это причиной плохих позиций по запросу
Что такое конкурентность запроса?
Если попробовать охарактеризовать это понятие простыми словами, то получается, что уровень конкуренции запроса отображает количество конкурирующих с вами сайтов, которые уже использовали данный запрос на страницах своего сайта, и уже занимают свои места в поиске по данному ключу.
Соответственно, чем выше показатель конкуренции, тем сложнее вам будет пробиться в топ поисковой выдачи по данному запросу.
В действительности, показатель конкурентности рассчитывается по множеству показателей, и практически у каждого специалиста по SEO-продвижению есть своя точная формула, которая позволяет ему сделать анализ семантического ядра онлайн по конкуренции запросов.
Но так как мы с вами не ставим перед собой задачу освоить все тонкости SEO-продвижения, и нам нужен результат с наименьшими затратами времени, то я вам предлагаю воспользоваться онлайн-сервисом Мутаген, который позволит нам повести полный анализ семантического ядра онлайн по конкуренции.
SpyWords
Сервис SpyWords позволяет определить нишу своего сайта, подобрать нужные ключевые слова, а также отслеживать показатели конкурентов.
Возможности SpyWords:
- Определение перспективных продуктов и ниш для запуска рекламы;
- Определение перечня конкурентов по конкретному запросу;
- Анализ конкурентов по контексту и поиску;
- Определение списка ключевых слов конкурентов;
- Просмотр преимуществ, которые конкуренты указывают в рекламе;
- Получение семантического ядра по заданному ключевому слову;
- Получение семантического ядра конкурентов.
Тарифы:
|
Период |
Business |
PRO |
Unlim |
|
12 месяцев (3 бесплатных месяца) |
312 долларов |
387 долларов |
780 долларов |
|
6 месяцев (1 бесплатный месяц) |
173 доллара |
215 долларов |
434 доллара |
|
1 месяц |
35 долларов |
43 доллара |
87 долларов |
|
1 сутки |
7 долларов |
9 долларов |
18 долларов |
Анализ ключевых фраз
Сервис Serpstat позволяет по каждой ключевой фразе конкурента провести SEO–анализ.
Для примера я возьму фразу «заработок в интернете».
Начать анализировать мы можем ее так же с главной страницы сайты, выбрав нужную поисковую систему.

Или добавить фразу в верхней панели внутреннего кабинета.

Как и в первом случае перед нами открывается страница Суммарный отчет.

Здесь вы видите частотность фразы, конкурентность, стоимость за клик и сложность фразы. Сложность фразы отражает оценку уровня конкуренции по ключевой фразе для продвижения в ТОП-10. Градация сложности рассчитывается от 0 до 100, где:
- 0-20 – легко,
- 21-40 – средне,
- 41-60 – сложно,
- 61-100 – очень сложно.
Например, для анализируемой фразы “заработок в интернете” уровень конкуренции высокий, а значит по этой фразе сложно (показатель 41-60) пробиться в ТОП-10.
Показатель Ключевые фразы отражает все вариации, по которой домены ранжируются в Google ТОП-100 (если при анализе выбрана ПС Google).
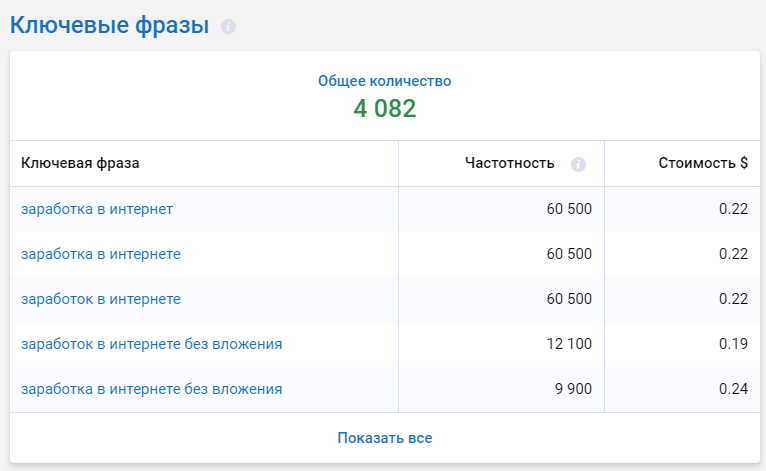
Ключевые фразы в контекстной рекламе дают такую же информацию, но уже по контексту.

График Тренды ключевого слова показывает изменение частотности фразы за последний год.

Сложность фразы – все тот же уровень конкуренции, но у же с детализацией по доменам и страницам.
Обратите внимание, что над таблицей есть три показателя:
- количество главных страниц в выдаче, которые находятся в ТОП-10. Для запроса “заработок в интернете” такая страница всего одна, и это даже не сайт, а группа во ВКонтакте.
- доменов с ключевой фразой в тайтл – количество доменов, в которых ключевая фраза встречается в title.
- страниц с ключевой фразой в тайтл – количество страниц, в которых ключевая фраза встречается в title.

Конкуренты в поисковой выдаче отражают сервисы и сайты, которые по данной ключевой фразе входят в выдачу ТОП-20 Google.

Ниже вы можете ознакомиться с конкурентами в контексте.
Брендовая семантика
В идеале процесс работает так:
1) Вы ждете заявок из контекстной рекламы;
2) Собираете семантику по маркерным запросам откуда угодно: от Wordstat до поисковых подсказок.
Неважно, что вы используете при сборе. У всех сервисов разное качество, но принцип один: на входе вы вводите маркерный запрос, а программа выдает расширения, которые содержат фразу.
Задача, которую приходится решать вручную – определить те самые маркеры (базисы)
Каждый из них отражает собственный спрос, ключевые фразы, расширения и охват. Для этого необходимо хотя бы минимальное знакомство с ассортиментом.
Когда речь идет о брендовой семантике, понятно, как искать маркеры. У бренда есть, как правило, русское или английское написание, названия серий, моделей. При этом важно учесть все ошибочные и синонимичные написания. О других случаях с примерами будет далее в статье.
3) Получаете десятки-сотни тысяч запросов, чистите их от «мусора» и получаете две группы: нужные запросы и минус-слова.
Подробнее как работать с базисами – в статье Прогноз трафика, бюджета и заявок в Яндекс.Директ

У магазина около 70-80 брендов, один из них – Stanley. Это и инструменты, и мебель, и посуда, и много другого. Нет смысла собирать все расширения от слова stanley, иначе будет очень много «мусора». Поэтому оставляем запросы из 2-3 слов:

Чаще всего лучше брать трехсловники или двухсловники, в некоторых специфических случаях допустимы однословники.
Термосы – самый популярный товар, у него 3 написания названия бренда – станлей, стенли, stanley, – и есть маркеры по сериям: stanley mountain, стенли классик.
Чем больше базисов, тем шире охват. У нас получается 70 видов товаров, по каждому – 20-50 базисов. Общий объем «хвоста» – несколько сотен тысяч расширенных запросов. Они могут пересекаться, но частично: как правило, процент пересечения невысокий.
В итоге вы получаете 100% охват, но тратите очень много времени на обработку данных. Чтобы ускорить процесс, часто используют способ перемножения запросов в скрипте-перемножалке.
Для брендового семантического ядра такой метод ускоряет работу. Но что делать, когда вы предлагаете услуги на высококонкурентном рынке?
Онлайн-сервисы
В остальном все работает просто: оплачиваете работу, вам выдают файлик с семантикой, который вы можете скачать и использовать.
Список онлайн-сервисов, которые занимаются сбором семантического ядра на заказ:
Семантика.Онлайн – одна из топовых контор, которая может сделать вам семантическое ядро. Многие известные компании работают с этим сервисом. Семантика.Онлайн давно зарекомендовала себя как профессионал своего дела. Тарифы, кстати говоря, там весьма доступные. Любой простой пользователь сможет позволить себе заказ семантического ядра у этой конторы.

На данный момент цена за одно ключевое слово составляет 2,5 рубля. Здесь же есть возможность заказать более тщательную ручную обработку и кластеризацию. В отличие от стандартной автоматической, ручная будет составляться опытными SEO-специалистами с полным погружением в тематику. В таком случае цена за ключ будет около 4,5 рублей. Дороже, но качественнее.
Сервис имеет большое количество положительных отзывов от разных вебмастеров. В основном это люди, для которых информационные сайты – бизнес, на котором они зарабатывают сотни тысяч рублей. Это не безликие комментарии, составленные самими администраторами сервиса. Все отзывы реальные, вы легко сможете проверить их авторов по социальным сетям.
Semantix.pro – еще один известный сервис, который занимается составлением семантического ядра на заказ. Можно рассматривать в качестве прямого конкурента или альтернативы Семантики.Онлайн. В среднем цены на услуги здесь выше. За один ключевой запрос вы должны будете заплатить 5 рублей по базовому тарифу и 10 – по более продвинутому.
Семантикс также имеет большое количество отзывов и рекомендаций. На сайте есть разделы с кейсами, где вы сможете видеть примерный процесс работы и результата.
В обоих случаях вы получите файл со сгруппированными ключевыми словами и заголовками статей (title).
Таких сервисов гораздо больше, но я решил вам показать самые популярные. Если они вам не нравятся, вы можете попробовать поискать другие. Но, должен предупредить, что при заказе услуг у непроверенных сервисов, вы рискуете нарваться на мошенников или дилетантов.
Как собирать ключи для СЯ
Как пользоваться Яндекс Вордстат: операторы, расширения и секреты
Кратко о важном: какими операторами пользоваться в Вордстате, чтобы смотреть нужные запросы, и как облегчить себе работу в сервисе.
Вордстат не дает абсолютно точной информации, в нем нет всех запросов, в данные могут быть искажены, потому что Яндексом пользуются не все потребители.Тем не менее, из этих данных можно сделать выводы о популярности темы или товара, приблизительно спрогнозировать спрос, собрать ключи и найти идеи для нового контента.
Можно искать данные, просто вбивая запрос в поиск по сервису, но для конкретизации запросов есть операторы — добавочные символы с уточнениями. Они работают на вкладках поиска по словам и по регионам, на вкладке с историей запросов можно использовать только оператор «+запрос».
В статье:
- Зачем нужен Вордстат
- Работа с операторами Вордстата
- Как читать данные Wordstat
- Расширения для Яндекс Вордстата
Продвижение сайта по низкочастотным запросам
Компании и веб-мастера стараются продвинуться под популярные запросы, чтобы получить больше трафика. И многие новички совершают ошибку, когда пишут исключительно под ВЧ, попадая при этом в условия огромной конкуренции за 10 мест в поисковой выдаче с тысячами и десятками тысяч сайтов. Исследование на сайте Chitika.com показывает, что сайты за пределами топ-10 не приносят особого трафика.
В статье:
- LT-запросы
- Суть продвижения по низкочастотным запросам
- Преимущества продвижения по низкочастотным запросам
- Как найти и собрать НЧ-запросы
- Способ первый: изучение семантики
- Способ второй: сервисы для анализа ключевых слов
- Как оптимизировать сайт и отдельную страницу под низкочастотные запросы
Подборка инструментов для SEO и LSI-копирайтинга: как собрать и проверить ключи
Делимся подборкой инструментов для сбора LSI-фраз и ключей. Для тех, кто еще не разобрался, рассказываем, в чем все-таки различие между SEO и LSI-копирайтингом, что должно быть в оптимизированных текстах в 2018 году.
В копирайтинге обычно выделяют два вида оптимизированных текстов: по SEO и LSI. Многие не соглашаются с таким делением, потому что эти два способа очень похожи.
SEO больше сосредоточено на работе с поисковыми ботами, а LSI на выдаче пользователям самой полной и полезной информации, повышении качества контента, к чему и стремятся поисковики. Подбирать такие фразы вручную довольно долго. Мы попробовали несколько сервисов, которые предлагают подобрать SEO и LSI-ключевики, чтобы дело шло быстрее.
В статье:
- Что такое LSI-ключи
- SEO и LSI — в чем разница
- Как искать LSI-фразы
- Инструменты и сервисы для LSI-копирайтинга
4 тактики подбора ключевых слов, которыми не все пользуются
Перевели и адаптировали статью «Advanced Keyword Research: Four Tactics You’re (Probably) Not Using» с нестандартными способами сбора ключей, основанными на практическом опыте.
Около года назад автору статьи пришли несколько идей, как еще можно собирать ключевые слова для продвижения. Он протестировал способы с бесплатными инструментами и получил интересные результаты. Тогда он расширил масштабы тестирования и по итогу вывел четыре способа, которые помогут собрать дополнительные ключи и продвинуть свои статьи в топ.
В статье:
- Подбор ключевиков по молодым сайтам из топа
- Сбор ключей с помощью пользовательского поиска Google (Google Custom Search Engine)
- Тактика моделирования запросов, по которым другие сайты попали в топ за несколько недель
- Реверс-инжиниринг «слабых» сайтов не из топа
Анализируем топ выдачи, чтобы пробиться в лидеры
Стремимся в лидеры выдачи: как анализ статей из топа поможет в работе над контентом, по каким критериям проводить анализ и как сделать это быстрее и эффективнее.
Сложно отслеживать результаты ведения блога и публикации других текстов на сайте без детальной аналитики. Как понять, почему статьи конкурентов в топе, а ваши нет, хотя вы пишете лучше и талантливее?
В статье:
- Что обычно советуют
- Как проводить анализ
- Минусы подхода
- Преимущества анализа контента
- Инструменты

Яндекс Wordstat
Сервис Яндекс Wordstat предназначен для определения отношения пользователей к тематике сайтов, выявления рекламодателями ключевых слов и формирования ежемесячной статистики ключевых слов Яндекса. Сервис позволяет проводить анализ по частоте и качеству показов рекламных объявлений в Яндекс Директ, а также формировать семантическое ядро.
Возможности Яндекс Wordstat:
- Формирование статистики запросов по заданным ключевым словам или словосочетаниям за месяц или за неделю;
- Формирование статистики запросов на карте;
- Формирование статистики по похожим на заданные слова или словосочетания запросам;
- Формирование статистики запросов по заданным ключевым словам или словосочетаниям в выбранном регионе анализа (продвижения) сайта.
Яндекс Wordstat является бесплатным сервисом.
Особенности сбора семантики по видам проектов
В зависимости от размера сайта, количества оказываемых услуг или продаваемых товаров мы собираем семантику различного размера и затрачиваем на это разное количество времени.
Средний сайт с категориями/подкатегориями, но без товаров
Если категорий на сайте много, то для начала узнаем список наиболее интересных клиенту. Если предпочтений нет, выбираем на своё усмотрение. По ним собираем слова из Яндекс Вордстата и чаще всего сразу поисковые подсказки. Если запросов набирается мало, то расширяем список с помощью дополнительных сервисов.
Работаем с получившимся списком, оптимизируем страницы под подобранные для продвижения ключевые слова.
Затем поэтапно собираем запросы для следующих категорий и т.д.
Если в процессе сбора коммерческой семантики находятся информационные запросы и позволяет время, оставляем их в отдельном списке. Такие ключевые слова часто используются в будущем при написании статей для блогов на сайтах.
Процесс отличается от предыдущего вида проекта тем, что на основе собранной семантики мы смотрим, каких срезов не хватает на сайте, но их спрашивают люди.
Срез — это страница с товарами категории или подкатегории каталога отфильтрованными по определенному параметру. Например по цвету, бренду, размеру и т.д.
Вспомним пример, который был выше, про категорию красные платья. Найденные в списке запросов для этой категории «короткие красные платья» и подскажут нам, что следует создать соответствующий срез.
Нельзя забывать, что популярными могут быть не только категории продукции, но и конкретные модели товаров. Находя такие запросы в собранном списке, мы обязательно проверяем их наличие в каталоге сайте.
Примечание. При формировании итогового списка запросов обязательно учитываем геозависимость, коммерциализацию и максимальную достижимую позицию. Почитать об этих факторах можно в нашей статье.
Способы восстановления данных с поврежденного HDD
Для восстановления данных можно использовать аварийную загрузочную флешку либо подключить неисправный HDD к другому компьютеру. В целом способы не отличаются по своей эффективности, но подходят для использования в разных ситуациях. Далее мы рассмотрим, как восстановить данные с поврежденного жесткого диска.
Способ 1: Zero Assumption Recovery
Профессиональный софт для восстановления информации с поврежденных HDD. Программа может быть установлена на операционные системы Windows и поддерживает работу с длинными именами файлов, кириллицей. Инструкция по восстановлению:
- Скачайте и установите ZAR на компьютер. Желательно, чтобы софт загружался не на поврежденный диск (на котором планируется сканирование).
- Отключите антивирусные программы и закройте другие приложения. Это поможет снизить нагрузку на систему и увеличить скорость сканирования.
- В главном окне нажмите на кнопку «Data Recovery for Windows and Linux», чтобы программа нашла все подключенные к компьютеру диски, съемные носители информации.
Выберите HDD или USB-флешку из списка (к которой планируется получить доступ) и нажмите «Next».
Начнется процесс сканирования. Как только утилита закончит работу, на экране отобразятся доступные для восстановления каталоги и отдельные файлы.
Отметьте нужные папки галочкой и нажмите «Next», чтобы перезаписать информацию.
Откроется дополнительное окно, где можно настроить параметры записи файлов.
В поле «Destination» укажите путь к папке, в которую будет записана информация.
После этого нажмите «Start copying the selected files», чтобы начать перенос данных.
Как только программа закончит работу, файлы можно будет свободно использовать, перезаписывать на USB-носители. В отличие от другого подобного софта, ZAR восстанавливает все данные, сохраняя при этом прежнюю структуру каталогов.
Способ 2: EaseUS Data Recovery Wizard
Триал-версия программы EaseUS Data Recovery Wizard доступна для бесплатной загрузки с официального сайта. Продукт подходит для восстановления данных с поврежденных HDD и их последующей перезаписи на другие носители или Flash-накопители. Порядок действий:
- Установите программу на компьютер, с которого планируется осуществлять восстановление файлов. Во избежание потери данных не загружайте EaseUS Data Recovery Wizard на поврежденный диск.
- Выберите место для поиска файлов на неисправном HDD. Если нужно восстановить информацию со стационарного диска, то выберите его из списка в верхней части программы.
По желанию можно ввести конкретный путь к каталогу. Для этого кликните на блок «Specify a location» и с помощью кнопки «Browse» выберите нужную папку. После этого нажмите «ОК».
Кликните на кнопку «Scan», чтобы начать поиск файлов на поврежденном носителе.
Результаты отобразятся на главной странице программы. Поставьте галочку напротив папок, которые хотите вернуть и нажмите «Recover».
Укажите место на компьютере, в котором планируется создать папку для найденной информации, и кликните «ОК».
Сохранить восстановленные файлы можно не только на компьютер, но и на подключенный съемный носитель. После этого получить к ним доступ можно будет в любое время.
Способ 3: R-Studio
R-Studio подходит для восстановления информации с любых поврежденных носителей (флешек, SD-карт, жестких дисков). Программа относится к типу профессиональных и может использоваться на компьютерах с операционной системой Windows. Инструкция по работе:
- Скачайте и установите на компьютер R-Studio. Подключите неработающий HDD или другой носитель информации и запустите программу.
- В главном окне R-Studio выберите нужное устройство и на панели инструментов нажмите «Сканировать».
Появится дополнительное окно. Выберите область сканирования, если хотите проверить определенный участок диска. Дополнительно укажите желаемый вид сканирования (простой, подробный, быстрый). После этого нажмите на кнопку «Сканирование».
В правой части программы будет отображаться информация об операции. Здесь же можно следить за прогрессом и примерно оставшимся временем.
Когда сканирование будет завершено, то в левой части R-Studio, рядом с диском, который анализировался, появятся дополнительные разделы. Надпись «Распознанный» означает, что программе удалось найти файлы.
Кликните по разделу, чтобы просмотреть содержимое найденных документов.
Отметьте галочкой нужные файлы и в меню «Файл» выберите «Восстановить помеченные».
Укажите путь к папке, в которую планируете сделать копию найденных файлов и нажмите «Да», чтобы начать копирование.
После этого файлы можно будет свободно открывать, переносить на другие логические диски и съемные носители. Если планируется сканирование HDD большого объема, то процесс может занять более часа.
Если жесткий диск вышел из строя, то восстановить с него информацию все еще можно. Для этого воспользуйтесь специальным софтом и проведите полное сканирование системы. Во избежание потери данных старайтесь не сохранять найденные файлы на неисправный HDD, а использовать для этой цели другие устройства.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Простое мобильное приложение, информирующее об остатках на складах и ценах по штрихкоду, для 1С: УНФ, Розница, УТ 11
Для различных торговых предприятий(магазинов, супермаркетов, торговых баз и т.п.) крайне необходимо персоналу, быстро уточнять наличие на складе или цену продаваемой номенклатуры. Что может быть проще взять свой смартфон навести камеру, и все выяснить.
Но не тут то было, в стандартном функционале 1С Розницы, УНФ, Торговли и т.п., ничего для быстрой обработки штрихкодов нет. На инфостарте ничего нужного, я также не нашел. В итоге пришлось разработать данное решение.
2 стартмани
СловоЁБ
Если по каким-то причинам вы не хотите покупать платный софт, то вот вам его бесплатная, сильно урезанная версия от тех же авторов. Обновлений не было уже около двух лет, но это не мешает программе отлично работать и по сей день.
Многие пользователи отдают предпочтение именно ей, полагая, что лучше уж урезанный функционал бесплатно, чем 2 тысячи рублей и куча ненужных для них функций. В чем-то они правы, большая часть всех инструментов Кей Коллектора не будет вами использована, если вы не занимаетесь поисковым продвижением на профессиональном уровне.
Для разового составления семантики вполне хватит и СловоЁБа. Именно его я использовал, когда описывал, как правильно составить семантическое ядро. Все перечисленные шаги применимы в обоих приложениях, т. к. интерфейс в них сильно схожий.
В СловоЁБе, действительно, есть множество полезных функций. Например, вы можете парсить данные из все того же Вордстата и далее выгрузить их в файл Excel для дальнейшей работы. Там же есть возможность более чистой проверки частотности, благодаря которой вы получите более правильные данные о популярности запроса. Что позволит лучше выстроить план продвижения в поисковиках.
Возможности программы:
- парсинг запросов с левой и правой колонки Вордстата,
- получение данных с “чистой” частотой запросов,
- выгрузка информации в формат Excel,
- возможность подключения антикапчи и др.
Скачать актуальную версию приложения СловоЁБ можно с блога разработчика.
Букварикс
Сервис Букварикс предоставляет набор инструментов для работы с ключевыми словами и доменами, а также для работы со списками.
Возможности Букварикс:
- Поиск по ключевым словам (по одному слову или по списку);
- Поиск по заданному домену;
- Сравнение доменов (двух, нескольких).
- Приведение слов в списке к одному виду;
- Анализ слов в списке по частоте встречаемости (в порядке снижения частоты);
- Сравнение двух списков и формирование одного общего списка оригинальных ключевых слов;
- Комбинирование и формирование словосочетаний из ключевых слов двух списков;
- Поиск и удаление дубликатов слов из списка.
Тарифы:
- Без регистрации – бесплатно (с ограниченными возможностями);
- Бесплатный аккаунт – бесплатно (с ограниченными возможностями);
- Бизнес-аккаунт – 695 рублей за 1 месяц.
А может, лучше заказать составление семантического ядра сайта?
Вы можете попытаться самостоятельно составить семантическое ядро с помощью бесплатных сервисов, о которых мы рассказали. Например, «Планировщик ключевых слов от Google» может дать вам неплохой результат. Но если вы заинтересованы в создании большого качественного семантического ядра, запланируйте эту статью расходов в вашем бюджете.
В среднем разработка семантического ядра сайта будет стоить от 30 до 70 тысяч рублей. Как вы помните, итоговая цена зависит от тематики бизнеса и оптимального количества поисковых запросов.
Про инструменты аналитики читайте здесь: Этапы разработки сайта — от идеи до продвижения








