Как парсить сайт: 20+ инструментов на все случаи жизни
Содержание:
- Version 3.0.3 (2017-02-03)
- Private Tunnel
- Парсинг постраничной навигации и получение ссылки на следующую страницу
- Motorola Moto G8 Plus
- License
- Version 2.0.0-alpha1 (2015-07-14)
- Делаем запросы
- Работа с DOM документа
- Enable result caching
- Licensing
- Скрипт Human Emulator парсинга HTML-страницы с использованием XPath
- Шаг 2 – Основы HTML парсинга
- Получение в cURL страниц со сжатием
- Шаг 3 – Реальный пример PHP парсинга HTML документа
- Присвоение уже назначенной буквы раздела
- Google Фото – лучшее бесплатное хранилище для фото и видео
- Tips
- Разбор файла в PHP — выводы
Version 3.0.3 (2017-02-03)
Fixed
- In the is now parsed as an rather than . (#325)
- Ensure integers and floats are always pretty printed preserving semantics, even if the particular
value can only be manually constructed. - Throw a when trying to pretty-print an node. Previously this resulted in
an undefined method exception or fatal error.
Added
- Added support for negative interpolated offsets:
- Added option to . If this option is enabled, an
attribute, containing the unresolved name, will be added to each resolved name. - Added option, which dumps nodes with position information.
Deprecated
The XML serializer has been deprecated. In particular, the classes Serializer\XML,
Unserializer\XML, as well as the interfaces Serializer and Unserializer are deprecated.
Private Tunnel
Парсинг постраничной навигации и получение ссылки на следующую страницу
Напишем новую функцию и по традиции разберём её позже
function getNextLink($link){
$url="https://www.bing.com/search";
$content= file_get_contents($url.$link);
libxml_use_internal_errors(true);
$mydom = new DOMDocument();
$mydom->preserveWhiteSpace = false;
$mydom->resolveExternals = false;
$mydom->validateOnParse = false;
$mydom->loadHTML($content);
$xpath = new DOMXpath($mydom);
$page = $xpath->query("//*/../following::li/a");
foreach ($page as $p){
$nextlink=$p->getAttribute('href');
}
return $nextlink;
}
Почти идентичная функция, изменился только xpath запрос. получаем элемент с классом ( это класс активной
кнопки постраничной навигации), поднимаемся на элемент вверх по dom дереву, получаем первый соседний элемент и получаем в нём ссылку. Эта и есть ссылка на
следующую страницу.
Motorola Moto G8 Plus

-
Дисплей: 6,3 дюйма, FHD+, IPS
-
Процессор: Snapdragon 665
-
Память: 4/64 Гб
-
ЦАП: отсутствует
-
Батарея: 4000 мАч
Цена: от 16 000 руб.
Бюджетные смартфоны довольно редко оснащаются стереодинамиками, но модель от Motorola в этом плане стала приятным исключением. Аппарат имеет действительно качественное звучание. Смотреть на нем фильмы или слушать музыку без наушников вполне комфортно. На этом фишки модели не закончились – есть защита от брызг P2i, NFC, разъем 3,5 и тройная камера 48+5+16 Мп. Фронтальная камера – 25 Мп.
Достоинства:
-
Быстрая зарядка.
-
Качественная фотокамера и интересные режимы для съемки.
-
Есть NFC.
-
Приятное звучание.
-
Защита от брызг.
-
Неплохая производительность.
Недостатки:
-
Смартфоны Motorola всегда внешне отличались от конкурентов, G8 Plus – это типичный девайс с Андроид без ярко-выраженных особенностей.
-
Комбинированный слот.
-
Маркий корпус.
License
PHP-CSS-Parser is freely distributable under the terms of an MIT-style license.
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the «Software»), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED «AS IS», WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Version 2.0.0-alpha1 (2015-07-14)
A more detailed description of backwards incompatible changes can be found in the
upgrading guide.
Removed
- Removed support for running on PHP 5.3. It is however still possible to parse PHP 5.2 and PHP 5.3
code while running on a newer version. - Removed legacy class name aliases. This includes the old non-namespaced class names and the old
names for classes that were renamed for PHP 7 compatibility. - Removed support for legacy node format. All nodes must have a method now.
Added
- Added support for remaining PHP 7 features that were not present in 1.x:
- Group use declarations. These are represented using nodes. Furthermore a
attribute was added to to handle mixed group use declarations. - Uniform variable syntax.
- Generalized yield operator.
- Scalar type declarations. These are presented using , , and
as the type. The PHP 5 parser also accepts these, however they’ll be instances there. - Unicode escape sequences.
- Group use declarations. These are represented using nodes. Furthermore a
- Added class, which should be used to create parser instances.
- Added which concatenates two names.
- Added which takes a subslice of a name.
Changed
-
is now an interface, implemented by , and
. The parser will try multiple parsers, until one succeeds. - Token constants are now defined on rather than .
- The , , and methods are
deprecated in favor of and . - The no longer clones nodes by default. The old behavior can be restored by
passing to the constructor. - The constructor for nodes no longer has a default value. E.g. should now
be written as .
This changelog only includes changes from the 2.0 series. For older changes see the
1.x series changelog and the
0.9 series changelog.
Делаем запросы
Интерфейс класса достаточно простой и прямолинейный. Имена методов соответствуют HTTP-методам, которые он выполняет: GET-метод соответствует методу get(), GET-post(), PUT-put() и т.д. И каждый из этих методов возвращает Promise (если вы знакомы с JavaScript, или ранее работали с ReactPHP, то это не должно вызвать у вас вопросов). Если вы не знаете, что это, то на даном этапе объяснения не имеют большого смысла, дальше будет пример, после которого всё станет понятно.
Для текущей задачи нам будет достаточно одного метода :
В коде выше будет описана анонимная функция, которая после успешного запроса выведет HTML-разметку на экран. Эта функция принимает ответ экземпляра . В этой функции мы можем описать обработчик ответа, который вернёт из этого промиса (Promise) распарсенную информацию, без лишнего HTML-кода.
Как вы можете заметить, алгоритм парсинга достаточно прост:
- Делаем запрос и получаем промис.
- Пишем обработчик этого промиса.
- Парсим нужную информацию внутри этого обработчика.
- Если нужно, повторяем первый шаг.
Работа с DOM документа
Страница фильма, которую мы парсим не требует никакой авторизации. Если посмотреть на исходный код этой страницы, то можно увидеть, что все данные, за которыми мы охотимся, доступны внутри HTML. Иногда бывают случаи, когда анализ сайта, его противопарсинговые защиты, обход алгоритмов защиты и т.д. занимают на порядок больше времени, чем написание самого кода парсера.
Теперь, когда мы научились получать ответ (содержимое WEB-страницы), можем начать работу с DOM-ом этого документа. Для этого, как я и ранее писал, я буду использовать Didom, подробнее о котором вы можете почитать здесь.
Для начала работы, нужно создать экземпляр класса , конструктор которого принимает HTML-разметку.
Внутри обработчика мы создали экземпляр класса , передав ему HTML-ответ, приведённый к строке. Теперь, нужно выбрать нужные данные, используя соответствующие CSS-селекторы.
Заголовки (Title, Alternative Title)
Заголовок может быть получен с тега h1 (который единственнный на всей странице).
Метод ищет первый элемент, соответствующий указанному селектору. После чего, к найденного элемента вызывается метод , который возвращает текст, содержащийся в этом элементе. Навигация и парсинг DOM-дерева выглядит очень похожим с jQuery:

Таблица параметров
Такие параметры фильма, как , , и т.д. находятся в таблице с классом .
А ещё из разметки можно увидеть, что нужные нам параметры находятся во втором столбце (td) каждой из строк таблицы (tr). Но, нам не нужно сильно запариваться по поводу парсинга информации, так как можно увидеть, что в каждой строке таблицы есть только по одной ссылке, которые, как раз таки, и содержат внутри себя текст параметров.
Для этого, напишем код, получая сначала все строки таблицы, а потом обращаясь к ним по индексу:
Время и рейтинг (time, rating)
Информация о времени находится в той же таблице, которую парсили в прошлом шаге. Для получение данных, можно, как и в прошлом коде, обратиться по индексу:
Однако, изучив детальнее, можно увидеть, что у блока «время» есть уникальный идентификатор runtime, которым мы и воспользуемся.
И в этом случае, код будет выглядеть:
И, аналогично поступим с рейтингом. Он, правда, не имеет тега id, однако, класс блога рейтинга уникальный, и не повторяется на странице, потому будем обращаться по нему:
Итого, код парсера будет выглядеть так:
Enable result caching
WhichBrowser supports PSR-6 compatible cache adapters for caching results between requests. Using a cache is especially useful if you use WhichBrowser on every page of your website and a user visits multiple pages. During the first visit the headers will be parsed and the result will be cached. Upon further visits, the cached results will be used, which is much faster than having to parse the headers again and again.
For example, if you want to enable a memcached based cache you need to install an extra composer package:
And change the call to WhichBrowser/Parser as follows:
$client = new \Memcached();
$client->addServer('localhost', 11211);
$pool = new \Cache\Adapter\Memcached\MemcachedCachePool($client);
$result = new WhichBrowser\Parser(getallheaders(), );
or
$client = new \Memcached();
$client->addServer('localhost', 11211);
$pool = new \Cache\Adapter\Memcached\MemcachedCachePool($client);
$result = new WhichBrowser\Parser();
$result->setCache($pool);
$result->analyse(getallheaders());
You can also specify after how many seconds a cached result should be discarded. The default value is 900 seconds or 15 minutes. If you think WhichBrowser uses too much memory for caching, you should lower this value. You can do this by setting the option or passing it as a second parameter to the function.
Licensing
Скрипт Human Emulator парсинга HTML-страницы с использованием XPath
В этой статье мы рассмотрим один из примеров написания скрипта для парсингаHTML-страниц с использованием XPath на примере сайта bing.com.
Сперва определимся с тем, что такое XPath и зачем оно нужно, если есть регулярные выражения?
XPath (XML Path Language) — это язык запросов к элементам XML-подобного документа (далее для краткости просто XML). XPath призван реализовать навигацию по DOM в XML.
Regexp — формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов. По сути это строка-образец (шаблон), состоящая из символов и метасимволов и задающая правило поиска.
Итак, главная разница в том, что XPath специализируется на XML, а Regexp — на любом виде текста.
В: Зачем использовать XPath, если есть regexp, в котором можно сделать тоже самое?О: Простота поддержки.
Синтаксис у regexp такой, что уже через неделю может быть проще всё переписать, чем вносить изменения, а с XPath можно спокойно работать. И синтаксис у xpath довольно компактный,xml’ё-фобы могут быть спокойны.
Простой пример для вдохновления — получим значение аттрибута «href» у, например, тега «a».
Yohoho! Regexp:
Быстро (несколько небольших страниц) пробежаться по основам XPath можно в туториале от .
Как использовать XPath в PHP можно почитать в документации на . И в небольшом тутораильчике от .
Теперь определимся с необходимым функционалом скрипта:
* Возможность указывать произвольный поисковый запрос
* Парсим только первую страницу поисковой выдачи
* Из поисковой выдачи нам нужно:
* заголовок
* ссылка
* номер в выдаче
Исходя из нашего ТЗ составляем примерный алгоритм работы скрипта:
1) Заходим на bing.com
2) Вводим поисковую фразу
3) Получаем со страницы необходимый результат
Приступим к написанию парсера поисковой выдачи http://bing.com. Для начала, создадим базовый каркас скрипта.
// coding: windows-1251 // Настройка HumanEmulator // ———————————————— // Где запущен XHE $xhe_host = «127.0.0.1:7010»; // HumanEmulator lib require «../../Templates/xweb_human_emulator.php»; // Our tools require «tools/functions.php»; // Настройки скрипта // ———————————————— // Скрипт // ———————————————— // Quit $app->quit();
В настройки добавим переменную для хранения поискового запроса.
// Поисковый запрос $text = «ХуманЭмулятор»;
Заходим на сайт.
// Базовый URL $base_url = «https://www.bing.com/?setlang=en»; $browser->navigate($base_url);
Вводим поисковую фразу.
$input->set_value_by_attribute(«name», «q», true, $text); sleep(1); $element->click_by_attribute(«type», «submit»); sleep(5);
Сохраним в переменную содержимое страницы.
// Получаем содержимое страницы $content = $webpage->get_body();
Настроим xpath-объект:
$dom = new DOMDocument; @$dom->loadHTML($content); $xpath = new DOMXpath($dom);
Теперь у объекта $xpath есть метод «query» в который мы будемпередавать наше xpath-выражение. Давайте начнём создавать xpath-выражение.Открыв исходный код страницы с результатами поисковой выдачи увидим, что сами результаты находятся внутри тега «li».
Т.о. наше xpath-выражение выберет со страницы все поисковые результаты.
$results = $xpath->query(«//li»);
На одной странице у нас должно быть 1 или больше результатов, проверим себя:
if($results === false) { echo «С нашим xpath-выражением что-то не так.» . PHP_EOL; $app->quit(); } elseif($results->length === 0) { echo «Поисковый запрос ‘{$text}’ не принёс результатов.» . PHP_EOL: $app->quit(); } echo «Нашли {$results->length} совпадений.» . PHP_EOL;
Здесь стоит обратить внимание на ветку if, где мы сравниваем кол-во результатов xpath-поиска с нулём. Если наше xpath-выражение ничего не нашло, то это может означать две вещи:* Bing действительно ничего не нашёл
* Bing что-то нашёл, но поменял вёрстку на странице, и наше xpath-выражение необходимо исправлять.
2-й пункт достаточно коварный, в таких случаях, когда xpath-выражение ничего не находит необходимо дополнительно сверятся, чтобы удостоверится, что xpath-выражение не устарело (хотя и это не даст 100% гарантий). В нашем случае будем сверяться с тем, что Bing пишет кол-во найденных результатов.
14 results
А если результатов по поисковому запросу нет, то:
Шаг 2 – Основы HTML парсинга
Эта библиотека, очень проста в использовании, но все же,
необходимо разобрать некоторые основы, перед тем как ее использовать.
Загрузка HTML
$html = new simple_html_dom();
// Load from a string
$html->load('<html><body><p>Hello World!</p><p>We're here</p></body></html>');
// Load a file
$html->load_file('http://sitear.ru/');
Все просто, вы можете создать объект, загружая HTML из
строки. Или, загрузить HTML код из файла. Загрузить файл вы можете по URL адресу, или
с вашей локальной файловой системы (сервера).
Важно помнить: Метод
load_file(), работает на использовании PHP функции file_get_contents. Если в
вашем файле php.ini, параметр allow_url_fopen
не установлен как true,
вы не сможете получать HTML файлы по удаленному адресу
Но, вы сможете загрузить эти
файлы, используя библиотеку CURL. Далее, прочитать содержимое, используя метод load().
Получение доступа к HTML DOM объектам
Предположим у нас уже есть DOM объект,
структурой, как на картинке выше. Вы можете начать работать с ним, используя
метод find(), и создавая коллекции. Коллекции – это группы объектов, найденные
с помощью селекторов – синтаксис в чем-то схож с jQuery.
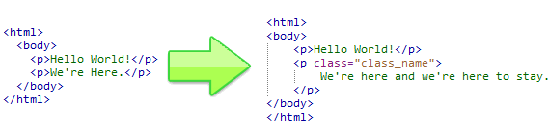
<html>
<body>
<p>Hello World!</p>
<p>We're Here.</p>
</body>
</html>
Используя этот пример HTML кода, мы узнаем, как получить доступ
к информации заключенной во втором параграфе (p). Также, мы изменим полученную
информацию и выведем результат на дисплей.
// создание объекта парсера и получение HTML
include('simple_html_dom.php');
$html = new simple_html_dom();
$html->load("<html><body><p>Hello World!</p><p>We're here</p></body></html>");
// получение массивов параграфов
$element = $html->find("p");
// изменение информации внутри параграфа
$element->innertext .= " and we're here to stay.";
// вывод
echo $html->save();
Как видите реализовать PHP парсинг документа HTML, очень даже просто, используя simple HTML DOM библиотеку.
В принципе, в этом куске PHP кода, все можно понять интуитивно, но если вы в чем-то
сомневаетесь, мы рассмотрим код.
Линия 2-4:
подключаем библиотеку, создаем объект класса и загружаем HTML код из
строки.
Линия 7: С
помощью данной строки, находим все <p> теги в HTML коде,
и сохраняем в переменной в виде массива. Первый параграф будет иметь индекс 0,
остальные параграфы будут индексированы соответственно 1,2,3…
Линия 10:
Получаем содержимое второго параграфа в нашей коллекции. Его индекс будет 1.
Также мы вносим изменения в текст с помощью атрибута innertext. Атрибут innertext, меняет все содержимое внутри
указанного тега. Также мы сможем
изменить сам тег с помощью атрибута outertext.
Давайте добавим еще одну строку PHP кода, с помощью которой мы назначим
класс стиля нашему параграфу.
$element->class = "class_name"; echo $html->save();
Результатом выполнения нашего кода будет следующий HTML документ:
<html>
<body>
<p>Hello World!</p>
<p class="class_name">We're here and we're here to stay.</p>
</body>
</html>
Другие селекторы
Ниже приведены другие примеры селекторов. Если вы
использовали jQuery, то
в библиотеке simple html dom синтаксис немножко схожий.
// получить первый элемент с id="foo"
$single = $html->find('#foo', 0);
// получает при парсинге все элементы с классом class="foo"
$collection = $html->find('.foo');
// получает все теги <a> при парсинге htmlдокумента
$collection = $html->find('a');
// получает все теги <a>, которые помещены в тег <h1>
$collection = $html->find('h1 a');
// получает все изображения с title='himom'
$collection = $html->find('img');
Использование первого селектора при php парсинге html документа,
очень простое и понятное. Его уникальность в том что он возвращает только один html элемент,
в отличии от других, которые возвращают массив (коллекцию). Вторым параметром (0),
мы указываем, что нам необходим только первый элемент нашей коллекции. Надеюсь,
вам понятны все варианты селекторов библиотеки simple HTML DOM, если вы чего-то не
поняли, попробуйте метод научного эксперимента. Если даже он не помог,
обратитесь в комментарии к статье.
Документация библиотеки
simple HTML DOM
Полнейшую документацию по использованию библиотеки simple HTML DOM вы
сможете найти по этому адресу:
http://simplehtmldom.sourceforge.net/manual.htm
Просто предоставлю вам иллюстрацию, которая показывает
возможные свойства выбранного HTML DOM элемента.

Получение в cURL страниц со сжатием
Иногда при использовании cURL появляется предупреждение:
Warning: Binary output can mess up your terminal. Use "--output -" to tell Warning: curl to output it to your terminal anyway, or consider "--output Warning: <FILE>" to save to a file.
Его можно увидеть, например при попытке получить страницу с kali.org,
curl https://www.kali.org/
Суть сообщения в том, что команда curl выведет бинарные данные, которые могут навести бардак в терминале
Нам предлагают использовать опцию «—output -» (обратите внимание на дефис после слова output – он означает стандартный вывод, т.е. показ бинарных данных в терминале), либо сохранить вывод в файл следующим образом: «—output «.
Причина в том, что веб-страница передаётся с использованием компрессии (сжатия), чтобы увидеть данные достаточно использовать опцию —compressed:
curl --compressed https://www.kali.org/
В результате будет выведен обычный HTML код запрашиваемой страницы.
Шаг 3 – Реальный пример PHP парсинга HTML документа
Для примера парсинга, и приведения HTML DOM библиотеки
в действие, мы напишем грабер материалов на сайте sitear.ru. Далее мы выведем все статьи в виде
списка, в котором будут указаны названия статей. При написании граберов,
помните, кража контента преследуется законом! Но не в случае, когда на странице
стоит активная ссылка на исходный документ.
include('simple_html_dom.php');
$articles = array();
getArticles('http://sitear.ru/');
Начинаем с подключения библиотеки, и вызова функции getArticles, которая будет парсить HTML документы
соответственно адресу страницы, которая передается в качестве параметра
функции.
Также мы указываем глобальный массив, в котором будет,
хранится вся информация о статьях. Перед тем как начать парсинг HTML документа,
давайте посмотрим, как он выглядит.
<div class="title_material"> <div class="name_material"><a href="…">Название материала</a></div> <div class="views_material">Просмотров: <b>35</b></div> </div> <div class="description"> Описание статьи…</div>
Это базовый шаблон данной страницы. При написании парсера html, нужно тщательно исследовать
документ, так как и комментарии, типа <!—comment—>, это тоже потомки. Другими словами, в глазах
библиотеки simple HTML DOM,
это элементы, которые равноценны другим тегам страницы.
Присвоение уже назначенной буквы раздела
Такого типа проблема встречается довольно часто. Это происходит при подключении SD карты к компьютеру, система присваивает ей туже букву, что и существующему разделу, из-за этого происходит конфликт и мы не видим нашу флешку в перечне дисков компьютера.
Для того чтобы устранить такого типа проблему открыть раздел «Управления компьютером» выше описан способ открытия этого раздела.
После попадания в раздел «Управления дисками» нам необходимо найти нашу флешку, ориентируйтесь на её объем, выбираем диск, совпадающий с объёмом нашей Micro SD карты. Нажимаем по нему правой кнопкой мыши и в выпавшем меню выбираем пункт «Изменить букву диска или путь к диску …».
Откроется окно, в котором нам необходимо нажать кнопку «Добавить».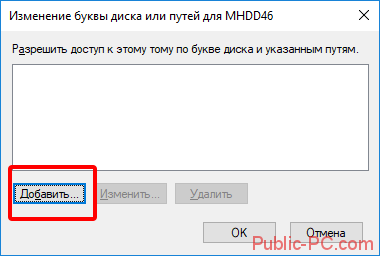
В открывшемся окне выбираем букву этому разделу и нажимаем «ОК».
Готово, мы задали букву нашему разделу, теперь проверяем его наличие в проводнике.
Google Фото – лучшее бесплатное хранилище для фото и видео
Tips
Provide clean input strings
If your input string consists of more than just the name and
directly related bits like salutations, suffixes etc.,
any additional parts can easily confuse the parser.
It is therefore recommended to pre-process any non-clean input
to isolate the name before passing it to the parser.
Multi-pass parsing
We have not played with this, but you may be able to improve results
by chaining several parses in sequence. E.g.
$parser = new Parser(); $name = $parser->parse($input); $name = $parser->parse((string) $name); ...
You can even compose your new input string from individual parts of
a previous pass.
Dealing with names in different languages
The parser is primarily built around the patterns of english names
but tries to be compatible with names in other languages. Problems
occur with different salutations, last name prefixes, suffixes etc.
or in some cases even with the parsing order.
To solve problems with salutations, last name prefixes and suffixes
you can create a separate language definition file and inject it when
instantiating the parser, see ‘Setting Languages’ above and compare
the existing language files as examples.
To deal with parsing order you may want to reformat the input string,
e.g. by simply splitting it into words and reversing their order.
You can even let the parser run over the original string and then over
the reversed string and then pick the best results from either of the
two resulting name objects. E.g. the salutation from the one and the
lastname from the other.
The name parser has no in-built language detection. However, you may
already ask the user for their nationality in the same form. If you
do that you may want to narrow the language definition files passed
into the parser to the given language and maybe a fallback like english.
You can also use this information to prepare the input string as outlined
above.
Alternatively, Patrick Schur as a PHP language detection library
that seems to deliver astonishing results. It won’t give you much luck if
you run it over the the name input string only, but if you have any more
text from the person in their actual language, you could use this to detect
the language and then proceed as above.
Gender detection
Gender detection is outside the scope of this project.
Detecting the gender from a name often requires large lists of first
name to gender mappings.
However, you can use this parser to extract salutation, first name and
nick names from the input string and then use these to implement gender
detection using another package (e.g. this one) or service.
Having fun with normalisation
Writing different language files can not only be useful for parsing,
but you can remap the normalised versions of salutations, prefixes and suffixes
to transform them into something totally different.
E.g. you could map to and then output
the parts in appropriate order to build a pipeline that automatically transforms
e.g. into .
Of course, this is a silly and rather contrived example, but you get the
gist.
Of course this can also be used in more useful ways, e.g. to spell out
abbreviated titles, like as etc. .
Разбор файла в PHP — выводы
Как я уже и говорил в начале, мои опыты не являются безупречными и опираться исключительно на полученные в их ходе результаты не стоит, т.к., несмотря на быстродействие file_get_contents() в моей ситуации, бывают случаи, когда намного удобнее и эффективнее использовать другие приведённые мною PHP парсеры файлов.
Кроме того, не стоит забывать, что PHP сам по себе является синхронным языком программирования, т.е. все серверные операции происходят последовательно без возможности настройки их параллельного выполнения, в том числе, и на разных ядрах серверного процессора.
Следовательно, на время выполнения операций, прописанных в PHP коде, может влиять целый ряд факторов, среди которых основным является нагруженность ядра в момент работы PHP приложения.
Я это особенно ощутил во время проведения опытов, когда один и тот же PHP парсер файла отработал за 9, затем за 12, а потом снова за 9 секунд на трёх последовательных итерациях из-за банального запуска проводника Windows во время второго случая, который, естественно, тоже требует серверных ресурсов.
Учитывая данные особенности, я проводил эксперименты практически одновременно, друг за другом, при одинаковом комплекте запущенных программ, чтобы не распылять ресурсы серверного железа.
Поэтому в дальнейшем, при проведении подобных экспериментов с PHP конструкциями действуйте аналогичным образом, т.к. это, по сути, единственный способ привести эксперименты к равным условиям.
Если же вы будете работать с асинхронными серверными языками (C#, Java) или технологиями (Node.js, например), то, по возможности, для экспериментов создавайте отдельный поток, который будет работать на выделенном ядре процессора.
Ну, а если найти полностью незадействованное ядро не получится (что при уровне современного ПО не удивительно), то вы хотя бы сможете найти самое слабонагруженное или, хотя бы, со статической нагрузкой, которая не меняется во времени.
Надеюсь, что мои наблюдения и рекомендации будут вам полезны, равно как и мои сегодняшние эксперименты с PHP парсерами файлов.
Подытоживая, хочу сказать, что приведённые в статье фрагменты кода могут использоваться не только для парсинга текстовых файлов в PHP, но и отлично подойдут для других форматов, например, для разбора CSV файлов дампа базы данных MySQL.
До новых встреч!








