Примеры sql-запросов в mariadb (mysql)
Содержание:
- Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
- Команда HOST
- Запрос для удаления данных (delete)
- Оператор insert into: добавление записи в таблицу
- Оператор join: объединение записей из двух таблиц
- Что такое язык запросов SQL?
- Команды для создания запросов
- Допустим, что вы дошли до этого момента
- SQL Учебник
- DML и обработка исключений
- Назовите четыре основных типа соединения в SQL
- Выражение CASE – условный оператор языка SQL
- Основные моменты при изучении Sql
- Команда SQLPROMPT
- Послесловие
- Команда PAUSE
- Вас заинтересует / Intresting for you:
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Примеры портфелей по стратегии Asset Allocation
- Типы данных и выражения sql
- Команды языка управления транзакциями
- Вывод статистики с накоплением по дате
Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
Команда HOST
Команда позволяет выполнять в SQL*Plus команды операционной системы.Например, может возникнуть необходимость посмотреть, существует ли некий файл в определенном каталоге, или выдать команды или на уровне , а затем вернуться в сеанс SQL*Plus и возобновить взаимодействие с базой данных Oracle.
Ниже приведен пример применения команды :
SQL> HOST cp /u01/app/oracle/new.sql /tmp
В этом примере команда помогает скопировать файл из указанного каталога в каталог .
С помощью команды можно выполнять практически все те же команды, которые доступны на уровне операционной системы. Слово можно заменять восклицательным знаком (!):
SQL> ! cp /u01/app/oracle/new.sql /tmp
На заметку! В случае ввода команды HOST без параметров вы попадаете в каталог операционной системы, из которого изначально запускали сеанс SQL*Plus.
По завершении работы с операционной системой достаточно ввести в командной строке и на экране снова появится приглашение покинутого ранее сеанса SQL*Plus.
Например:
SQL> HOST $ exit SQL>
Запрос для удаления данных (delete)
SQL-запрос для удаления данных строится следующим образом:
delete from table where clause;
где delete from — это начало запроса, table — это конкретное название таблицы, where — указывает, что далее будут указаны фильтры строк, которые необходимо удалить, clause — это сами фильтры для выборки строк. После sql-запроса ставится точка с запятой.
Важно отметить, что фильтр может быть весьма сложным и состоять из большого количества условий. Для его составления используются три операнда — and (И), or (ИЛИ) и скобки (для отделения сложных выражений)
Логика здесь аналогична самой простой математики.
Примечание: Важно отметить, что часть where с clause являются необязательными. То есть, если фильтр не требуется, то их можно не писать
Однако, если фильтр нужен, то обе составляющих необходимо использовать в запросе.
К примеру, представим, что вам необходимо удалить все строки, где возраст больше 1 и меньше 5, или же строки, в которых указывается имя Масяня. Тогда запрос выглядел бы так:
delete from somedata where (Age > 1 and Age < 5) or Name = 'Масяня';
Если разбирать логику, то этот запрос говорит базе данных, чтобы она проверила каждую строчку таблицы somedate и если строка удовлетворяет условиям, то ее необходимо удалить.
Оператор insert into: добавление записи в таблицу
Начнём с добавления новых данных в таблицу. Для добавления записи используется следующий синтаксис:
В начале добавим город в таблицу городов:
При добавлении записи не обязательно указывать значения для всех полей. Многие из полей имеют значения по умолчанию, которые сами заполняются при сохранении.
Теперь создадим запись о погоде за сегодняшний день.
При определении таблицы weather_log мы решили ссылаться на город, путём записи в поле city_id идентификатора города из таблицы cities. Так как мы только что добавили новый город, ничего не мешает использовать его идентификатор в записи о погоде.
Идентификатором города будет первичный ключ, который также был определён в качестве первого поля таблицы. Нумерация этого поля начинается с единицы, значит первая добавленная запись имеет идентификатор . Зная это, запрос на добавление записи о погоде в Санкт-Петербурге за третье сентября 2017 года выглядит так:
Оператор join: объединение записей из двух таблиц
В нашей таблице для хранения погодного дневника город сохраняется как идентификатор, поэтому при обычном чтении данных из этой таблицы вместо названия города стоит непонятное число. Чтобы подставить на место числа действительное значение, а конкретнее — название города, в SQL существуют операторы объединения — .
Поддержка операторов объединения и позволяет базе данных называться реляционной.
Поменяем запрос на показ погодных записей, чтобы он объединял две таблицы, а в поле города показывалось его название, а не идентификатор:
Важно усвоить три самых главных момента:
- При чтении из объединённых таблиц, в перечислении полей после SELECT нужно явно указывать в поле имени также имя таблицы, с которой производится объединение.
- Всегда есть основная таблица (тб1), из которой читается большинство полей и присоединяемая (тб2), имя которой определяется после оператора JOIN.
- Помимо указания имени второй таблицы, обязательно следует указать условие, по которому будет происходить объединение. В этом примере таким условием будет соответствие идентификатора города из тб1 (weather_log.city_id) первичному ключу города из тб2 (cities.id).
Что такое язык запросов SQL?
Язык запросов sql используется программистами наиболее широко. Причиной тому является повсеместное распространение динамических веб сайтов. Как правило, такие ресурсы имеют гибкую оболочку. Но основной костяк такого сайта составляют базы данных. Если вы начинающий программист, вы просто обязаны освоить структурированный язык запросов SQL.
Зачем нужно знать язык запросов SQL?
Освоив язык запросов sql, вы с легкостью сможете писать приложения для WordPress. Это один из самых популярных блоговых движков в мире. Вы сможете писать sql запросы любой сложности, ведь писать sql запросы — это основное при изучении sql. На сайте запросы sql примеры найти не сложно, sql примеры Вы найдете в разделе SQL SELECT (запросы sql примеры).
Недавно появившийся веб ресурс sql-language.ru содержит массу информации касающейся языка запроса sql. По сути дела данный веб-сайт составляет огромный sql справочник. На сайте грамотно и в доступной форме рассмотрены запросы в sql.
Ресурс имеет раздел язык запросов sql для начинающих. Здесь вы можете получить начальные сведения о языке. Приведены основные возможности, которые будут доступны программистам на sql. В общих чертах это хранение и получение данных, их обработка и система команд. В данном разделе приведены типы команд, которые включает язык запросов sql и рассмотрено их назначение. Раздел описывающий данные входящие в язык запросов sql описывает строковые, числовые и прочие типы данных. На каждый тип приведено подробное описание и определена допустимая величина строки. Структурированный язык запросов sql предполагает аккуратное использование типов данных. Также в данном разделе содержится подробная информация по типам совместимым с Access и Oracle. Раздел привилегий языка запроса sql, расписывает как распределить или частично ограничить доступ к данным. Особенно это востребовано для веб сайтов с динамичным содержимым. Примером таких сайтов являются форумы или корпоративные сайты. Возможность редактирования отдельных данных допускается не для всех. Вот здесь то и пригодятся привилегии, которые допускает язык запросов sql. Вы сможете создать систему паролей и отсечь часть пользователей от активных действий. Раздел индексы, языка запроса sql, объясняет, как добиться максимальной производительности системы. Использование индексации позволит серверу легко и быстро находить данные. Структурированный язык запросов sql фактически создавался для этой цели. Простота и удобство в поиске данных, послужило быстрому признанию и распространению языка запроса sql. В восьмидесятых годах язык был признан стандартом для работы с базами данных. С тех пор язык запросов sql используется на большинстве серверов.
Еще один наиболее масштабный раздел сайта это команды. Пожалуй этот сектор рассмотрен на сайте sql-language.ru наиболее подробно. Как обычно, для начинающих приведена общая описательная часть о типах команд языка запроса sql. Рассмотрены такие общие типы как команды определения данных, команды языка управления, управление транзакциями и манипулирование данными. В дальнейшем, каждая из команд рассмотрена в деталях. Детально описан синтаксис команды, назначение, и конечный результат ее действия. Еще один серьезный раздел сайта посвящен условиям языка запроса sql. Здесь подробно описано как организовать обработку данных определенным образом. Возможны гибкие варианты, ограничения или исключения данных из процесса обработки.
Вся информация на сайте является абсолютно бесплатной. Сайт обладает достаточно простой навигацией. В структуре данных довольно легко ориентироваться даже неподготовленному человеку. Для новичков впервые осваивающих язык запросов sql веб сайт будет хорошим подспорьем. Оставьте закладку на sql-language.ru и вы всегда сможете найти необходимую информацию, касающуюся языка запроса sql. Для тех, кто уже сталкивался с программированием с использованием языка запроса sql, ресурс не будет лишним. Наверняка не всякий держит все тонкости языка в голове. Периодически возникают вопросы, требующие припоминания основ и деталей. Для зарегистрированных пользователей, на сайте предусмотрена возможность оставлять комментарии. Вы сможете задать вопрос, и прочитать, что по этому поводу думают другие. Удачи вам на поприще программирования.
Команды для создания запросов
13. SELECT
используется для получения данных из определённой таблицы:
Следующей командой можно вывести все данные из таблицы:
14. SELECT DISTINCT
В столбцах таблицы могут содержаться повторяющиеся данные. Используйте для получения только неповторяющихся данных.
15. WHERE
Можно использовать ключевое слово в для указания условий в запросе:
В запросе можно задавать следующие условия:
- сравнение текста;
- сравнение численных значений;
- логические операции AND (и), OR (или) и NOT (отрицание).
Попробуйте выполнить следующие команды
Обратите внимание на условия, заданные в :
16. GROUP BY
Оператор часто используется с агрегатными функциями, такими как , , , и , для группировки выходных значений.
Выведем количество курсов для каждого факультета:
17. HAVING
Ключевое слово было добавлено в SQL потому, что не может быть использовано для работы с агрегатными функциями.
Выведем список факультетов, у которых более одного курса:
18. ORDER BY
используется для сортировки результатов запроса по убыванию или возрастанию. отсортирует по возрастанию, если не будет указан способ сортировки или .
Выведем список курсов по возрастанию и убыванию количества кредитов:
19. BETWEEN
используется для выбора значений данных из определённого промежутка. Могут быть использованы числовые и текстовые значения, а также даты.
Выведем список инструкторов, чья зарплата больше 50 000, но меньше 100 000:
20. LIKE
Оператор используется в , чтобы задать шаблон поиска похожего значения.
Senior Java Developer
Orion Innovation (Ранее MERA), Удалённо, По итогам собеседования
tproger.ru
Вакансии на tproger.ru
Есть два свободных оператора, которые используются в :
- (ни одного, один или несколько символов);
- (один символ).
Выведем список курсов, в имени которых содержится , и список курсов, название которых начинается с :
21. IN
С помощью можно указать несколько значений для оператора :
Выведем список студентов с направлений Comp. Sci., Physics и Elec. Eng.:
22. JOIN
используется для связи двух или более таблиц с помощью общих атрибутов внутри них. На изображении ниже показаны различные способы объединения в SQL
Обратите внимание на разницу между левым внешним объединением и правым внешним объединением:
Выведем список всех курсов вне зависимости от того, обязательны они или нет:
23. View
— это виртуальная таблица SQL, созданная в результате выполнения выражения. Она содержит строки и столбцы и очень похожа на обычную SQL-таблицу. всегда показывает самую свежую информацию из базы данных.
Создадим , состоящую из курсов с 3 кредитами:
24. Агрегатные функции
Эти функции используются для получения совокупного результата, относящегося к рассматриваемым данным. Ниже приведены общеупотребительные агрегированные функции:
- — возвращает количество строк;
- — возвращает сумму значений в данном столбце;
- — возвращает среднее значение данного столбца;
- — возвращает наименьшее значение данного столбца;
- — возвращает наибольшее значение данного столбца.
Допустим, что вы дошли до этого момента
- Выбирать детальные данные по условию WHERE из одной таблицы
- Умеете пользоваться агрегатными функциями и группировкой из одной таблицы
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
| DepartmentName | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 1 | 2000 | 2000 | |
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666.66666666667 |
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1000 | Иванов И.И. | 5000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1002 | Сидоров С.С. | 2500 |
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
DML и обработка исключений
Если в блоке PL/SQL инициируется исключение, Oracle не выполняет откат изменений, внесенных командами DML этого блока. Логическими транзакциями приложения должен управлять программист, который и определяет, какие действия следует выполнять в этом случае. Рассмотрим следующую процедуру:
Обратите внимание: перед инициированием исключения задается значение параметра OUT. Давайте запустим анонимный блок, вызывающий эту процедуру, и проанализируем результаты :. Код выводит следующие значения:
Код выводит следующие значения:
Как видите, исключение было инициировано, но строки из таблицы книг при этом остались удаленными; дело в том, что Oracle не выполняет автоматического отката изменений. С другой стороны, переменная table_count сохранила исходное значение. Таким образом, в программах, выполняющих операции DML, вы сами отвечаете за откат транзакции — а вернее, решаете, хотите ли вы выполнить откат
Принимая решение, примите во внимание следующие соображения:
- Если для блока выполняется автономная транзакция, в обработчике исключения необходимо произвести ее откат или закрепление (чаще откат).
- Для определения области отката используются точки сохранения. Можно произвести откат транзакции до конкретной точки сохранения, тем самым оставив часть изменений, внесенных в течение сеанса.
Если исключение передается за пределы «самого внешнего» блока (то есть остается необработанным), то в среде выполнения PL/SQL, и в частности в SQL*Plus, автоматически осуществляется откат транзакции, и все изменения отменяются.
Назовите четыре основных типа соединения в SQL
Чтобы объединить две таблицы в одну, следует использовать оператор . Соединение таблиц может быть внутренним () или внешним (), причём внешнее соединение может быть левым (), правым () или полным ().
- — получение записей с одинаковыми значениями в обеих таблицах, т.е. получение пересечения таблиц.
- — объединяет записи из обеих таблиц (если условие объединения равно true) и дополняет их всеми записями из обеих таблиц, которые не имеют совпадений. Для записей, которые не имеют совпадений из другой таблицы, недостающее поле будет иметь значение .
- — возвращает все записи, удовлетворяющие условию объединения, плюс все оставшиеся записи из внешней (левой) таблицы, которые не удовлетворяют условию объединения.
- — работает точно так же, как и левое объединение, только в качестве внешней таблицы будет использоваться правая.
Рассмотрим пример соединения SQL таблиц с использованием . Следующий запрос выбирает все заказы с информацией о клиенте:
9
Выражение CASE – условный оператор языка SQL
| Первая форма: | Вторая форма: |
|---|---|
| CASE WHEN условие_1 THEN возвращаемое_значение_1 … WHEN условие_N THEN возвращаемое_значение_N END |
CASE проверяемое_значение WHEN сравниваемое_значение_1 THEN возвращаемое_значение_1 … WHEN сравниваемое_значение_N THEN возвращаемое_значение_N END |
Разберем на примере первую форму CASE:
| ID | Name | Salary | SalaryTypeWithELSE | SalaryTypeWithoutELSE |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | ЗП >= 3000 | ЗП >= 3000 |
| 1001 | Петров П.П. | 1500 | ЗП < 2000 | NULL |
| 1002 | Сидоров С.С. | 2500 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1003 | Андреев А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1004 | Николаев Н.Н. | 1500 | ЗП < 2000 | NULL |
| 1005 | Александров А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
Разберем на примере вторую форму CASE:
- Сотрудникам ИТ-отдела выдать по 15% от ЗП;
- Сотрудникам Бухгалтерии по 10% от ЗП;
- Всем остальным по 5% от ЗП.
| ID | Name | Salary | DepartmentID | NewYearBonusPercent | BonusAmount |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 250 |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 225 |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 250 |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 300 |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 225 |
| 1005 | Александров А.А. | 2000 | NULL | 5% | 100 |
- Первым делом ЗП должны получить сотрудники у кого оклад меньше 2500
- Те сотрудники у кого оклад больше или равен 2500, получают ЗП во вторую очередь
- Внутри этих двух групп нужно упорядочить строки по ФИО (поле Name)
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1000 | Иванов И.И. | 5000 |
| 1002 | Сидоров С.С. | 2500 |
| ID | Name | Salary | DepartmentID | NewYearBonusPercent1 | NewYearBonusPercent2 |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 5% |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 15% |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 10% |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 15% |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 15% |
| 1005 | Александров А.А. | 2000 | NULL | — | 5% |
Основные моменты при изучении Sql
Как уже отмечалось выше, запросы применяются для обработки и ввода новой информации в БД, состоящую из таблиц. Каждая ее строка — это отдельная запись. Итак, создадим БД. Для этого напишите команду:
Create database ‘bazaname’
В кавычках пишем имя БД на латинице. Старайтесь придумать для нее понятное имя. Не создавайте базу типа «111», «www» и тому подобное.
После создания БД устанавливаем кодировку windows-1251:
SET NAMES ‘utf-8’
Это нужно чтобы контент на сайте правильно отображаться.
Теперь создаем таблицу:
CREATE TABLE ‘bazaname’ . ‘table’ (
id INT(8) NOT NULL AUTO_INCREMENT PRIMARY KEY,
log VARCHAR(10),
pass VARCHAR(10),
date DATE
);

Во второй строке мы прописали три атрибута. Посмотрим, что они означают:
- Атрибут NOT NULL означает, что ячейка не будет пустой (поле обязательное для заполнения);
- Значение AUTO_INCREMENT — автозаполнение;
- PRIMARY KEY — первичный ключ.
Команда SQLPROMPT
Администратору баз данных обычно приходится иметь дело с несколькими базами данных. Из-за этого при выполнении множества задач на протяжении дня очень легко забыть, к какой базе данных подключен тот или иной сеанс SQL*Plus. Поэтому во избежание допущения грубых ошибок (вроде удаления производственных таблиц вместо разрабатываемых или тестируемых), следует всегда настраивать среду так, чтобы имя экземпляра базы данных постоянно отображалось в приглашении, напоминая о том, с какой базой данных происходит взаимодействие.
Для настройки приглашения SQL*Plus так, чтобы в нем отображалось имя базы данных, служит приведенная ниже команда, в которой используется специальная предопределенная переменная (предопределенные переменные подробно рассматриваются в разделе “Предопределенные переменные SQL*Plus” далее в главе):
SQL> SET SQLPROMPT '_CONNECT_IDENTIFIER > ' nick >
Обратите внимание, что команда приводит к немедленному изменению приглашения в интерфейсе SQL*Plus. После выдачи этой команды приглашение приобретает более значимый вид, ясно указывающий на то, с какой базой данных происходит взаимодействие, и избавляет от необходимости делать по этому поводу какие-либо предположения
В данном примере оно указывает на то, что в текущий момент подключение установлено с базой данных .
Для настройки приглашения SQL*Plus можно также использовать и другие специальные предопределенные переменные. Например, с помощью переменной в приглашении отображается имя пользователя:
SQL> SET SQLPROMPT "_USER > " APPOWNER >
Применив одновременно переменные и , можно сделать так, чтобы в приглашении отображалось и имя базы данных, и имя текущего пользователя:
SQL> SET SQLPROMPT "_USER'@'_CONNECT_IDENTIFIER > " APPOWNER@nick >
Используя переменные и , в приглашении можно отображать не только имя текущего пользователя, но и привилегии, которыми он обладает:
SQL> SET SQLPROMPT "_USER _PRIVILEGE> " SYS AS SYSDBA>
С помощью переменных , и в приглашении можно отобразить имя пользователя, текущую дату и имя базы данных:
SQL> SET SQLPROMPT "_USER 'on' _DATE 'at' _CONNECT_IDENTIFIER > " SYS on 20-JUN-09 at nick>
При желании строку, вроде показанной выше, легко добавить в файл ,чтобы желаемые значения устанавливались автоматически при каждом входе в систему, и их не приходилось настраивать вручную.
Послесловие
Стоит знать, что каждая из баз данных позволяет использовать рассмотренные sql-запросы с расширенными возможностями. К примеру, одновременное удаление из нескольких таблиц или же вставка строк с использованием запросов выборки. Поэтому, если у вас возникает необходимость в чем-то специфическом, то стоит более подробно изучать возможности каждой базы данных.
Как видите, основы баз данных не так уж сложны и их может освоить каждый. Тем не менее, пользы от их понимания много, так как все остальные сложные технические термины основываются или применяются для них. К примеру, ключи и индексы это не заумные вещи (хотя и могут быть непростыми), а лишь механизмы, которые позволяют быстрее осуществлять фильтрацию и поиск строк (например, из все той же простой таблички somedata). И это существенно легче понять и использовать, если знаешь как строится фундамент баз данных.
- PHP редирект — перенаправление на другую страницу
- Модульный принцип: несколько моментов
Команда PAUSE
Часто бывает так, что сценарии при выполнении генерируют вывод, который не умещается на экране. Этот вывод быстро пролетает перед глазами на экране и исчезает до того, как его удается прочитать. Разумеется, можно воспользоваться командой для перехвата всего вывода целиком, но делать так постоянно не выгодно, поскольку тогда придется тратить на создание и прочтение файлов с выводом сценариев целый день. Поэтому лучше использовать другую предлагаемую в SQL*Plus команду, а именно — , которая позволяет приостанавливаться после отображения каждого целого экрана вывода. Переход к следующему экрану вывода осуществляется просто нажатием клавиши <Enter>.
Приведенный ниже пример демонстрирует использование команды для замедления отображения вывода на экране терминала:
SQL> SHOW PAUSE PAUSE is OFF SQL> SET PAUSE ON SQL> SHOW PAUSE PAUSE is ON and set to ""
После настройки команды вывод больше не будет быстро проскакивать на экране при каждом выполнении SQL-команды. Вместо этого SQL*Plus будет отображать один экран вывода, и ожидать нажатия клавиши <Enter>. При запуске запросов с командой для просмотра первого экрана вывода тоже необходимо нажимать клавишу <Enter>.
Вас заинтересует / Intresting for you:
Использование SQL*Plus и Oracl… 4627 просмотров aleksandr Tue, 21 Nov 2017, 13:19:25
Административные команды в SQL… 2078 просмотров Antoniy Tue, 21 Nov 2017, 13:18:46
Фиксация изменений DML-команд … 1081 просмотров Дэйзи ак-Макарова Tue, 21 Nov 2017, 13:18:46
Команды SQL*Plus и SQL 1093 просмотров Дэн Tue, 21 Nov 2017, 13:19:25
Author: Antoniy
Другие статьи автора:
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Примеры портфелей по стратегии Asset Allocation
Бенджамин Грэм, автор известной любому инвестору книги “Разумный инвестор” и учитель Уоррена Баффета, предложил очень простой портфель, который на 50 % состоит из акций и на 50 % из облигаций. Это динамичный вариант. Если произошел кризис, то уменьшаем долю облигаций до 20 – 25 % и наращиваем долю акций. И, наоборот, при перегреве рынка, росте котировок акций продаем их и увеличиваем долю облигаций.
Fidelity – одна из крупнейших компаний по управлению активами в мире разработала следующие варианты инвестпортфелей:
Консервативный
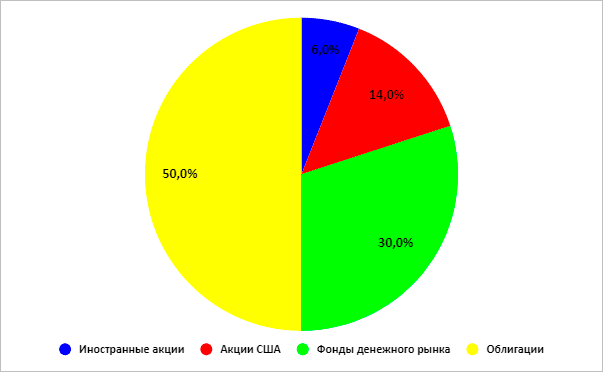
Сбалансированный
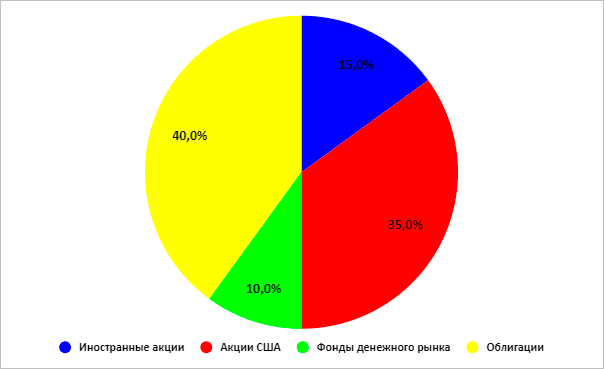
Портфель роста
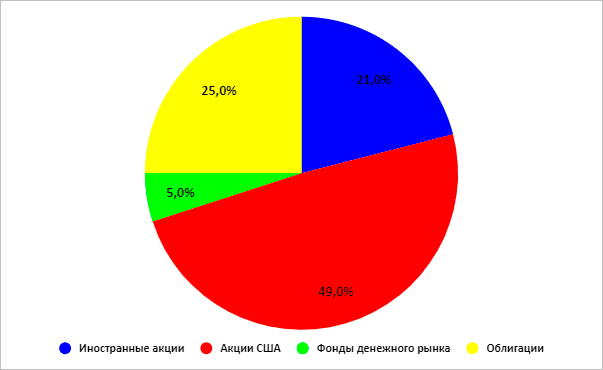
Агрессивный
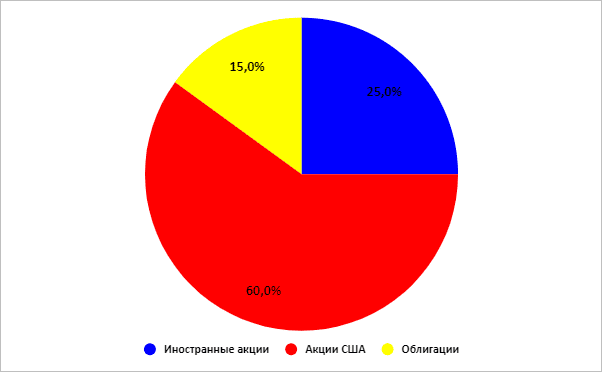
Среднегодовая доходность по этим вариантам распределения активов составила:
| Консервативный | Сбалансированный | Роста | Агрессивный |
| 5,96 % | 7,96 % | 8,97 % | 9,65 % |
Рейтинговое агентство Morningstar ввело больше активов, чем Fidelity. Добавились товары и недвижимость.
Консервативный
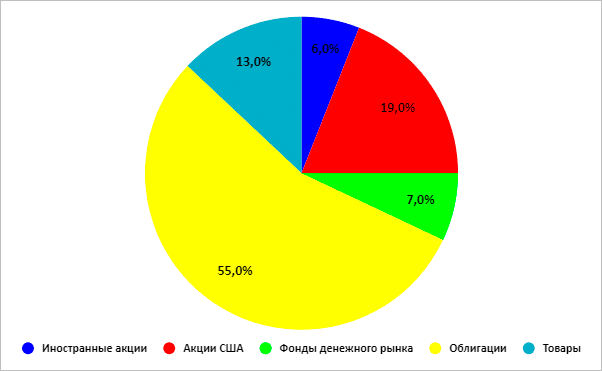
Умеренный (доля недвижимости – 4 %, денежного рынка – 2 %)
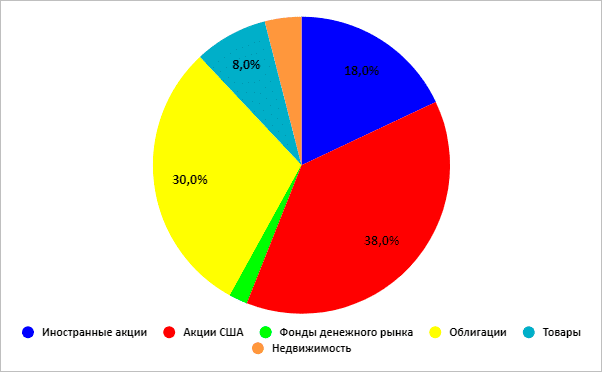
Портфель роста
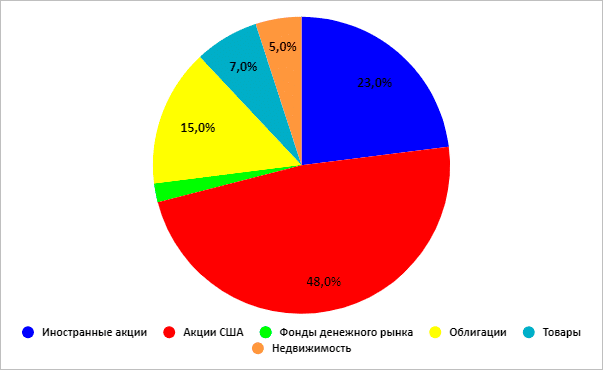
Агрессивный
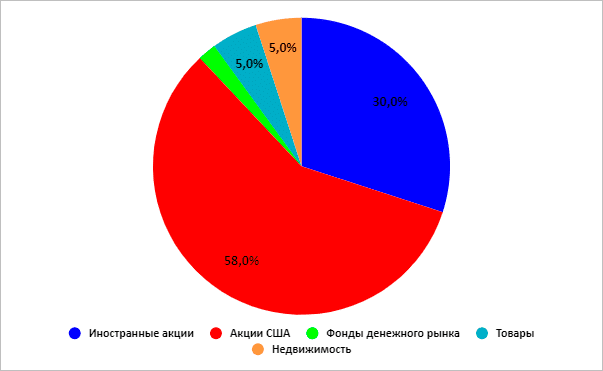
Типы данных и выражения sql
Типы
данных
Символьный
тип данных содержащий буквы, цифры,
специальные символы
CHAR
или CHAR
(n)
– символьные строки фиксированные
данные
VARCHAR
(n)
– символьные строки
Целые
числа
INTЕGER
или INT
– целое для решения которого отводится,
как байта
SMALLINT
– короткое
целое (2 байта)
FLOAT
–
число плавающих точек
DECIMAL
(p)
– аналогично FLOAT
с числовым значение цифр р
DECIMAL
(p,
n)
– аналогично предыдущим, р – общее
количество десятичных чисел
Денежный
тип
MONEY
(p,
n)
– аналогично типу DECIMAL
(p,
n)
Дата
и время
DATE
— дата
TIME
— время
INTERVAL
– временный интервал
DATETIME
– момент время
Двоичные
данные
BINARY
BYTE
BLOB
– хранить данные любого объема в двоичном
коде
Последовательный
тип
SERIAL
– тип данных на основе INTEGER
позволяющий сформировать уникальные
значения
Выражения
Арифметические
выражения
+,
-, *, %, /, ^,
Логические
операции
AND
– логическое умножение
OR
– лог сложение
NOT
–лог отриц
Текстовые
операции
&
— слияние слов
Пример
выражения
Kol*Price
(Kol*Price)/8200
AVG
Язык
SQL
оперирует терминами: таблица, строка,
столбец или колонка.
Полное
имя таблицы: имя _ владельца.имя_таблицы
Полное
имя столбца: имя _ владельца.имя_столбца
Основной
яз SQL составляет операции, условно
разбитые на несколько групп.
Категории
операторов
SQL:
-
Date
Definition Language (DDC) -
Date
Manipulation Language (DML) -
Date
Control Language (DCL) -
Transaction
Control Language (TCL) -
Cursor
Control Language (CCL)
Команды языка управления транзакциями
Команды языка управления транзакциями ( TCL (Тгаnsасtiоn Соntrol Language) ) команды позволяют определить исход транзакции.
Команды управления транзакциями управляют изменениями в базе данных, которые осуществляются командами манипулирования данными.Транзакция (или логическая единица работы) – неделимая с точки зрения воздействия на базу данных последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.COMMIT — заканчивает («подтверждает») текущую транзакцию и делает постоянными (сохраняет в базе данных) изменения, осуществленные этой транзакцией. Также стирает точки сохранения этой транзакции и освобождает ее блокировки. Можно также использовать эту команду для того, чтобы вручную подтвердить сомнительную распределенную транзакцию.ROLLBACK — выполняет откат транзакции, т.е. отменяет все изменения, сделанные в текущей транзакции. Можно также использовать эту команду для того, чтобы вручную отменить работу, проделанную сомнительной распределенной транзакцией.
Понятие транзакции имеет непосредственную связь с понятием целостности базы данных. Очень часто база данных может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Например, невозможно принять сотрудника в отдел, название и код которого отсутствует в базе данных.
В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии базы данных и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и база данных остается в таком состоянии, в котором находилась к моменту начала транзакции, т.е. в целостном состоянии.
В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей, т.е., если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т.е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами. Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
SET @cvalue = 0
В следующем запросе, мы созданную ранее переменную и применим:
SELECT products.Name AS Name, (@cvalue := @cvalue + Orders) as Orders, Date FROM (SELECT ProductID AS ProductID, SUM(Orders) AS Orders, DATE(date) AS Date FROM statistics WHERE ProductID = '1' GROUP BY date) AS statistics JOIN products ON statistics.ProductID = products.id
Итоговый отчет:
+-----------------------+--------+------------+ | Name | Orders | Date | +-----------------------+--------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | | Процессоры Pentium II | 2 | 2014-09-12 | | Процессоры Pentium II | 4 | 2014-09-14 | | Процессоры Pentium II | 6 | 2014-09-15 | +-----------------------+--------+------------+
Получить используемую в примерах базу данных можно здесь.








