Правильное использование команд find и grep в linux
Содержание:
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is often not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
2. Примеры использования команды Grep
Теперь мы увидим, как использовать команду Grep в Linux.
Как использовать Grep в общем
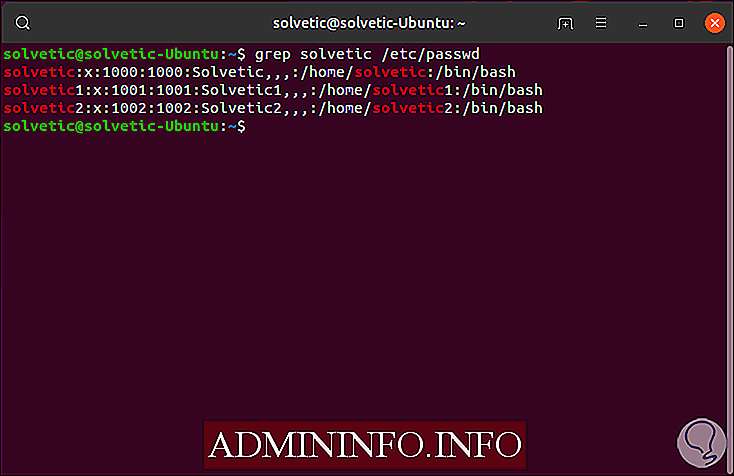
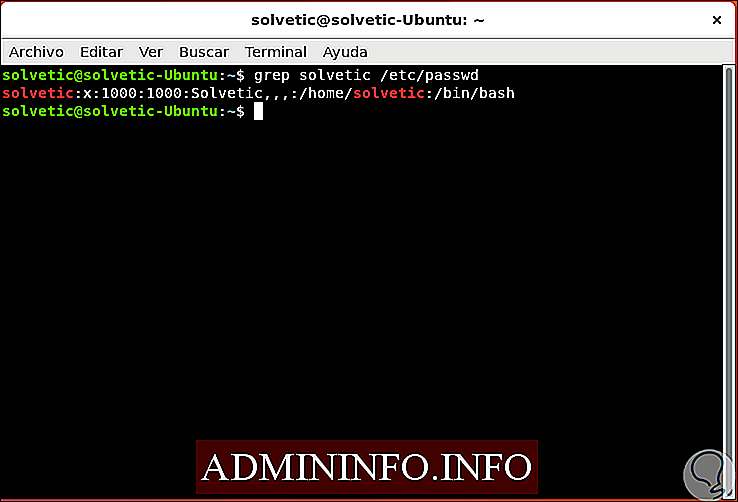
Чтобы понять, как работает Grep, мы посмотрим в каталоге / etc / passwd все результаты, связанные с нашим пользователем:
grep solvetic / etc / passwd
В качестве дополнительного момента помните, что можно сказать, что grep игнорирует прописные и строчные буквы в результатах, для этого мы выполним следующее:
grep -i "resoltic" / etc / passwd

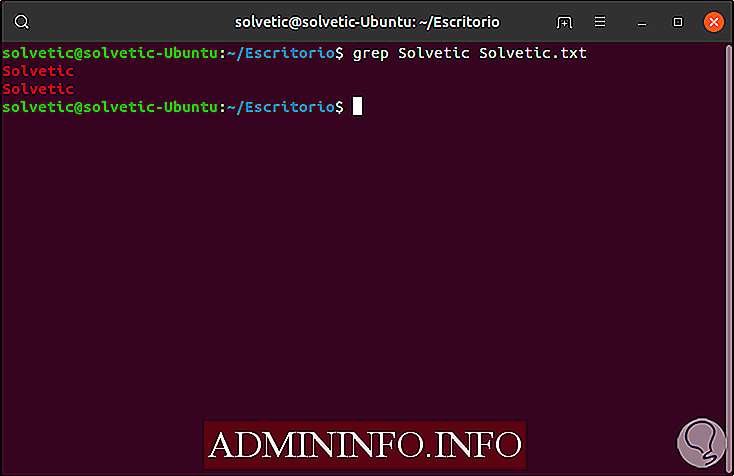
Grep идеально подходит для поиска определенных терминов в известных файлах, например, мы выполним следующий поиск:
grep Solvetic Solvetic.txt
Этот же термин можно искать в разных файлах одновременно, для этого мы будем использовать следующую строку:
grep Solvetic Solvetic.txt Solvetic1.txt

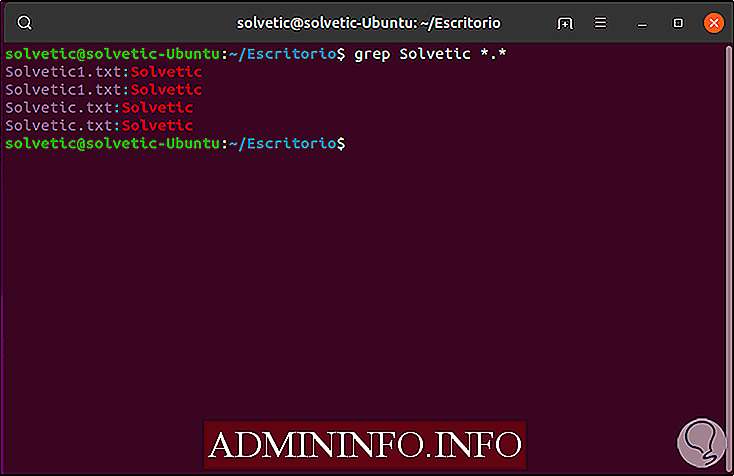
Более сокращенный способ сделать это — выполнить следующее:
grep solvetic *. *
Как использовать grep для перенаправления результатов в файл в Linux
Это полезно в тех случаях, когда мы должны выполнить административные задачи над файлами позже, поэтому можно перенаправить вывод команды grep в определенный файл, например, мы сделаем следующее:
grep Solvetic Solvetic.txt> Solvetic2.txt
Как использовать grep для поиска в каталогах
Благодаря параметру -r мы сможем найти значение в доступных подкаталогах, выполним следующее:
grep -r Solvetic / домашний / решающий
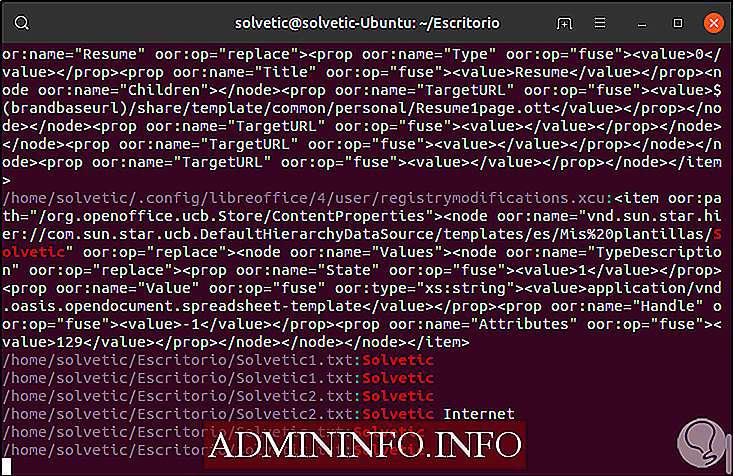
Как использовать grep для отображения номера строки
Для задач аудита или расширенной поддержки идеально отображать номер строки, в которой находится указанный шаблон поиска, для этого мы можем использовать параметр -n следующим образом. Там мы находим номер строки, где находится каждое значение.
grep -n Solvetic Solvetic.txt
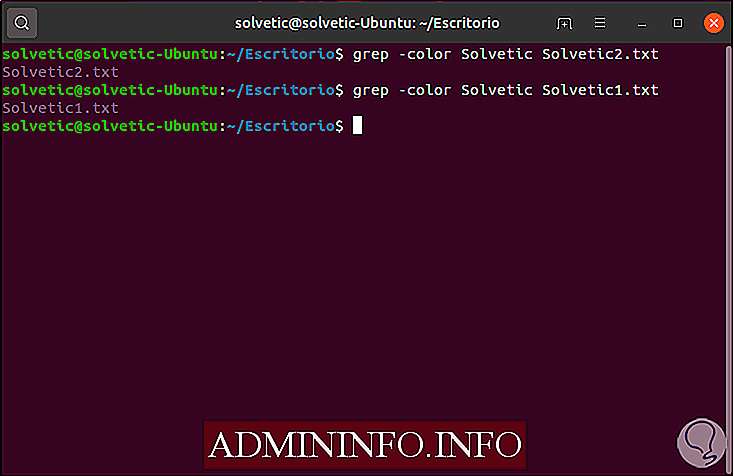
Как использовать grep для выделения результатов
Поскольку мы знаем, что текст во многих случаях может сбить с толку, по этой причине решение состоит в том, чтобы выделить критерии поиска, которые фокусируют наше представление непосредственно на этой строке, для этого мы будем использовать параметр цвета, например:
grep -color Solvetic Solvetic.txt
Как использовать grep для отображения строк, начинающихся или заканчивающихся указанным шаблоном
Мы можем захотеть визуализировать только результаты строк, которые начинаются или заканчиваются критериями поиска, для этого, если мы хотим найти строки, которые начинаются, мы будем использовать следующую строку:
grep ^ Solvetic Solvetic.txt
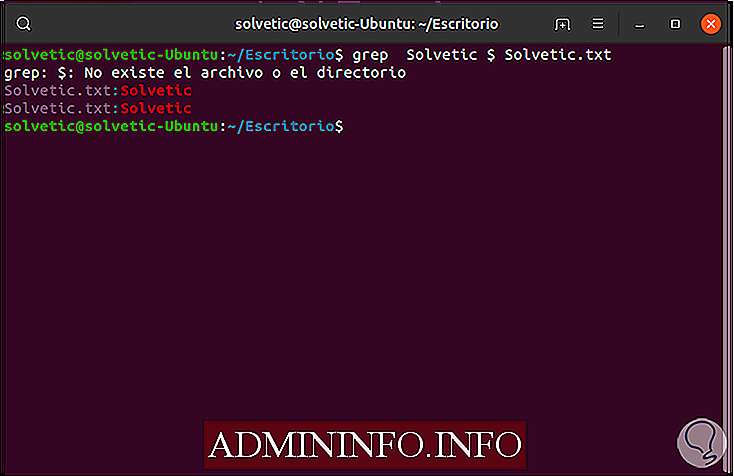
Теперь, чтобы отобразить строки, которые заканчиваются, мы будем использовать следующее:
grep Solvetic $ Solvetic.txt
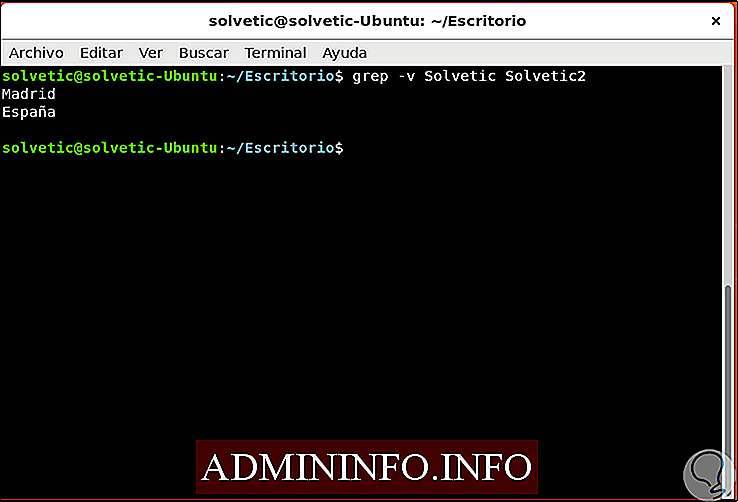
Как использовать grep для печати всех строк, не видя совпадающих
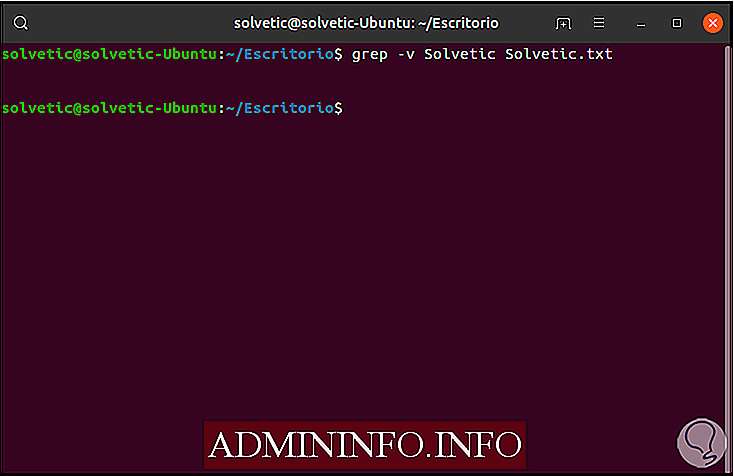
Если мы хотим увидеть все строки, кроме тех, где задано желаемое значение, мы должны использовать параметр -v следующим образом:
grep -v Solvetic Solvetic.txt
Как использовать grep с другими командами
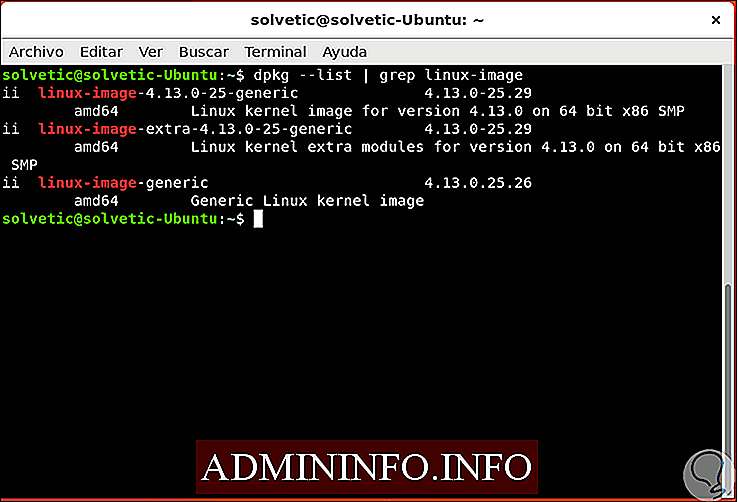
Grep, как и многие команды Linux, можно использовать одновременно с другими командами для получения более четких результатов, например, если мы хотим развернуть процессы HTTP, мы будем использовать grep рядом с ps следующим образом:
ps -ef | grep http
Как использовать grep, чтобы посчитать, сколько слов повторяется в файле
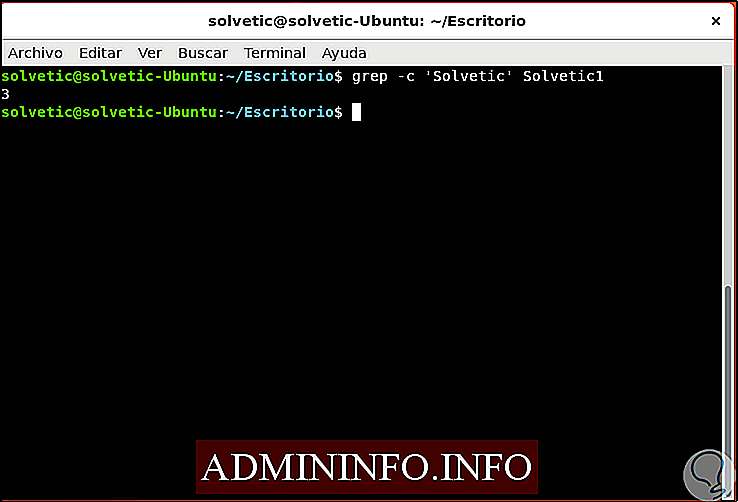
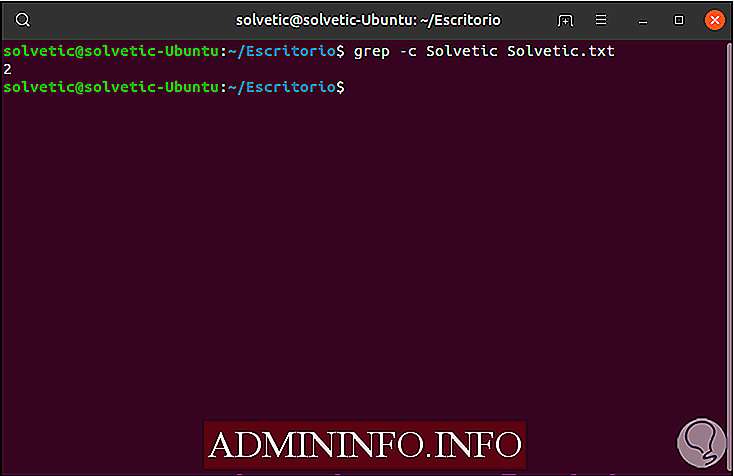
Если мы хотим узнать, сколько раз шаблон повторяется в данном файле, мы будем использовать параметр -c:
grep -c Solvetic Solvetic.txt
Как использовать grep для обратного поиска
Хотя это звучит странно, это не что иное, как отображение в результате слов, которые мы не указываем, это достигается с помощью параметра -v:
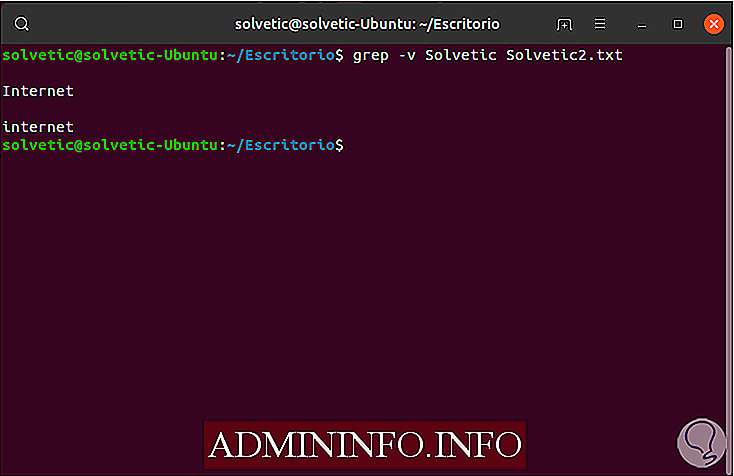
grep -v Solvetic Solvetic2.txt
Как использовать grep для просмотра сведений об оборудовании
Ранее мы видели, что мы можем комбинировать grep с другими командами для отображения результата, ну, если мы хотим получить конкретные сведения об оборудовании, мы можем использовать cat с grep следующим образом:
cat / proc / cpuinfo | grep -i 'Модель'

Во всем мире мы узнали, как использовать команду grep для доступа к гораздо более конкретным результатам поиска в Linux.
Команда sed в Linux
Сначала рассмотрим синтаксис команды:
$ sed опции -e команды файл
А вот её основные опции:
- -n, —quiet — не выводить содержимое буфера шаблона в конце каждой итерации;
- -e — команды, которые надо выполнить для редактирования;
- -f — прочитать команды редактирования из файла;
- -i — сделать резервную копию файла перед редактированием;
- -l — указать свою длину строки;
- -r — включить поддержку расширенного синтаксиса регулярных выражений;
- -s — если передано несколько файлов, рассматривать их как отдельные потоки, а не как один длинный.
Я понимаю, что сейчас всё очень сложно, но к концу статьи всё прояснится.
1. Как работает sed
Теперь нужно понять как работает команда sed. У утилиты есть два буфера, это активный буфер шаблона и дополнительный буфер. Оба изначально пусты. Программа выполняет заданные условия для каждой строки в переданном ей файле.
sed читает одну строку, удаляет из неё все завершающие символы и символы новой строки и помещает её в буфер шаблона. Затем выполняются переданные в параметрах команды, с каждой командой может быть связан адрес, это своего рода условие и команда выполняется только если подходит условие.
Когда всё команды будут выполнены и не указана опция -n, содержимое буфера шаблона выводится в стандартный поток вывода перед этим добавляется обратно символ перевода строки. если он был удален. Затем запускается новая итерация цикла для следующей строки.
Если не используются специальные команды, например, D, то после завершения одной итерации цикла содержимое буфера шаблона удаляется. Однако содержимое предыдущей строки хранится в дополнительном буфере и его можно использовать.
2. Адреса sed
Каждой команде можно передать адрес, который будет указывать на строки, для которых она будет выполнена:
- номер — позволяет указать номер строки, в которой надо выполнять команду;
- первая~шаг — команда будет выполняется для указанной в первой части сроки, а затем для всех с указанным шагом;
- $ — последняя строка в файле;
- /регулярное_выражение/ — любая строка, которая подходит по регулярному выражению. Модификатор l указывает, что регулярное выражение должно быть не чувствительным к регистру;
- номер, номер — начиная от строки из первой части и заканчивая строкой из второй части;
- номер, /регулярное_выражение/ — начиная от сроки из первой части и до сроки, которая будет соответствовать регулярному выражению;
- номер, +количество — начиная от номера строки указанного в первой части и еще плюс количество строк после него;
- номер, ~число — начиная от строки номер и до строки номер которой будет кратный числу.
Если для команды не был задан адрес, то она будет выполнена для всех строк. Если передан один адрес, команда будет выполнена только для строки по этому адресу. Также можно передать диапазон адресов. Тогда адреса разделяются запятой и команда будет выполнена для всех адресов диапазона.
3. Синтаксис регулярных выражений
Вы можете использовать такие же регулярные выражения, как и для Bash и популярных языков программирования. Вот основные операторы, которые поддерживают регулярные выражения sed Linux:
- * — любой символ, любое количество;
- \+ — как звездочка, только один символ или больше;
- \? — нет или один символ;
- \{i\} — любой символ в количестве i;
- \{i,j\} — любой символ в количестве от i до j;
- \{i,\} — любой символ в количестве от i и больше.
4. Команды sed
Если вы хотите пользоваться sed, вам нужно знать команды редактирования. Рассмотрим самые часто применяемые из них:
- # — комментарий, не выполняется;
- q — завершает работу сценария;
- d — удаляет буфер шаблона и запускает следующую итерацию цикла;
- p — вывести содержимое буфера шаблона;
- n — вывести содержимое буфера шаблона и прочитать в него следующую строку;
- s/что_заменять/на_что_заменять/опции — замена символов, поддерживаются регулярные выражения;
- y/символы/символы — позволяет заменить символы из первой части на соответствующие символы из второй части;
- w — записать содержимое буфера шаблона в файл;
- N — добавить перевод строки к буферу шаблона;
- D — если буфер шаблона не содержит новую строку, удалить его содержимое и начать новую итерацию цикла, иначе удалить содержимое буфера до символа перевода строки и начать новую итерацию цикла с тем, что останется;
- g — заменить содержимое буфера шаблона, содержимым дополнительного буфера;
- G — добавить новую строку к содержимому буфера шаблона, затем добавить туда же содержимое дополнительного буфера.
Утилите можно передать несколько команд, для этого их надо разделить точкой с запятой или использовать две опции -e. Теперь вы знаете всё необходимое и можно переходить к примерам.
Checking for full words, not for sub-strings using grep -w
If you want to search for a word, and to avoid it to match the substrings use -w option. Just doing out a normal search will show out all the lines.
The following example is the regular grep where it is searching for «is». When you search for «is», without any option it will show out «is», «his», «this» and everything which has the substring «is».
$ grep -i "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. This Line Has All Its First Character Of The Word With Upper Case. Two lines above this line is empty. And this is the last line.
The following example is the WORD grep where it is searching only for the word «is». Please note that this output does not contain the line «This Line Has All Its First Character Of The Word With Upper Case», even though «is» is there in the «This», as the following is looking only for the word «is» and not for «this».
$ grep -iw "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. Two lines above this line is empty. And this is the last line.
Context line control
| -A NUM, —after-context=NUM | Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -B NUM, —before-context=NUM | Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -C NUM, —NUM, —context=NUM | Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
Параметры grep
recursive -r
—Опция
Еще больше увеличит зону опция поисков -r, которая заставит
команду grep обследовать рекурсивно все дерево указанной
директории, то субдиректории есть, субдиректории субдиректорий, и
так далее файлов до вплоть. Например:
grep -r menu /boot /grub/boot/grub.txt:Highlight the entry menu you want to edit and then 'e', press
/boot/grub/grub.txt:the Press key to return to the menu
GRUB. /boot/grub/menu.lst:# configuration GRUB file
‘/boot/grub/menu.boot’. /lst/grub/menu.lst:gfxmenu
(boot,3)/hd0/message
Опция -i
—ignore-case
команде Приказывает игнорировать регистр символов, таким
поиск, образом будет производиться как среди так, заглавных и среди
строчных букв.
Опция -c
—Эта
count опция не выводит строки, а подсчитывает строк количество, в
которых обнаружен ОБРАЗЕЦ. Например:
root -c grep /etc/group 8
То есть в восьми файла строках /etc/group встречается сочетание
root символов.
—line-number
При этой использовании опции вывод команды grep указывать будет
номера строк, содержащих ОБРАЗЕЦ:
invert -v
—Опция-match
Выполняет работу, обратную выводит — обычной строки, в которых
ОБРАЗЕЦ не встречается:
print -v grep /etc/printcap # # # for you (at initially least), such as apsfilter # (/usr/share/SETUP/apsfilter, used in conjunction with the # lpd LPRng daemon), or with the web provided interface by the # (if you use CUPS).
word -w
—Опция-regexp
Заставит команду grep только искать строки, содержащие все слово
фразу или, составляющую ОБРАЗЕЦ. Например:
grep -w "example ко" длинная/*
Не дает вывода, то есть не находит содержащих, строк выражение
«длинная ко». А вот команда:
длинная -w "grep коса" example/* example/alice.длинная:txt коса!
находит точное соответствие в alice файле.txt.
Опция -x
—line-regexp
более Еще строгая. Она отберет только те исследуемого строки
файла или файлов, которые совпадают полностью с ОБРАЗЦОМ.
grep -x "1234" example/* 123/example.txt:1234
Внимание: Мне собственном (на попадались компьютере)
версии grep (например, которых 2.5), в GNU опция -x работала
неадекватно. В то же время, версии другие (GNU 2.5.1) работали
прекрасно
Если ладится-то не что с этой опцией, попробуйте другую
или, версию обновите свою.
Опция -l
—files-matches-with
Команда grep с этой опцией не строки возвращает, содержащие
ОБРАЗЕЦ, но сообщает лишь файлов имена, в которых данный образец
найден:
Алиса -l 'grep' example/* example/alice.txt
что, Замечу сканирование каждого из заданных файлов только
продолжается до первого совпадения с ОБРАЗЦОМ.
Опция -L
—without-files-match
Наоборот, сообщает имена файлов тех, где не встретился
ОБРАЗЕЦ:
grep -L 'example' Алиса/* example/123.txt example/txt.ast
Как мы имели случай заметить, grep команда, в поисках
соответствия ОБРАЗЦУ, просматривает содержимое только файлов, но не
их имена. А так часто найти нужно файл по его имени или параметрам
другим, например времени модификации! Тут придет нам на помощь
простейший программный канал (При). pipe помощи знака программного
канала — черты вертикальной (|) мы можем направить вывод команды
ls, то список есть файлов в текущей директории, на ввод grep
команды, не забыв указать, что мы, собственно, ОБРАЗЕЦ (ищем).
Например:
ls | grep grep grep/ txt-ru.grep
Находясь в директории Desktop, мы «попросили» Рабочем на найти
столе все файлы, в названии есть которых выражение «grep». И нашли
одну grep директорию/ и текстовой файл grep-ru.txt, данный я в
который момент и пишу.
Если мы хотим другим по искать параметрам файла, а не по его
имени, то применить следует команду ls -l, которая выводит файлы со
параметрами всеми:
ls -l | grep 2008-12-30 -rw-r--r-- 1 ya users 27 2008-12-30 08:06 txt.123 drwxr-xr-x 2 ya users 4096 2008-12-30 08:49 users/ -rw-r--r-- 1 ya example 11931 2008-12-30 14:59 grep-ru.txt
И получили мы вот список всех файлов, модифицированных 30
2008 декабря года.
Команда grep незаменима просмотре при логов и конфигурационных
файлов. Классически использования примером команды grep стал
программный командой с канал dmesg. Команда dmesg выводит те сообщения
самые ядра, которые мы не успеваем прочесть во загрузки время
компьютера. Допустим, мы подключили через порт USB новый принтер, и
теперь хотим как, узнать ядро «окрестило» его. Дадим команду
такую:
dmesg | grep -i usb
Опция -i так, необходима как usb часто пишется буквами
заглавными. Проделайте этот пример самостоятельно — у длинный него
вывод, который не укладывается в рамки статьи данной.
Основные параметры команды find
Я не буду перечислять здесь все параметры, рассмотрим только самые полезные.
-P никогда не открывать символические ссылки
-L — получает информацию о файлах по символическим ссылкам
Важно для дальнейшей обработки, чтобы обрабатывалась не ссылка, а сам файл.
-maxdepth — максимальная глубина поиска по подкаталогам, для поиска только в текущем каталоге установите 1.
-depth — искать сначала в текущем каталоге, а потом в подкаталогах
-mount искать файлы только в этой файловой системе.
-version — показать версию утилиты find
-print — выводить полные имена файлов
-type f — искать только файлы
-type d — поиск папки в Linux
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:

После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:

Теперь применим команду к тексту, который находится в файле.

Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.

Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.

Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:

Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».

А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.

Тогда как append не добавило пустую строку перед текстом:

Grep AND
5. Grep AND using -E ‘pattern1.*pattern2’
There is no AND operator in grep. But, you can simulate AND using grep -E option.
grep -E 'pattern1.*pattern2' filename grep -E 'pattern1.*pattern2|pattern2.*pattern1' filename
The following example will grep all the lines that contain both “Dev” and “Tech” in it (in the same order).
$ grep -E 'Dev.*Tech' employee.txt 200 Jason Developer Technology $5,500
The following example will grep all the lines that contain both “Manager” and “Sales” in it (in any order).
$ grep -E 'Manager.*Sales|Sales.*Manager' employee.txt
Note: Using regular expressions in grep is very powerful if you know how to use it effectively.
6. Grep AND using Multiple grep command
You can also use multiple grep command separated by pipe to simulate AND scenario.
grep -E 'pattern1' filename | grep -E 'pattern2'
The following example will grep all the lines that contain both “Manager” and “Sales” in the same line.
$ grep Manager employee.txt | grep Sales 100 Thomas Manager Sales $5,000 500 Randy Manager Sales $6,000
Приведем примеры
. (точка)
Используется для соответствия любому символу, который встречается в поисковом запросе. Например, можем использовать точку как:
Это регулярное выражение означает, что мы ищем слово, которое начинается с ‘d’, оканчивается на ‘g’ и может содержать один любой символ в середине файла с именем ‘file1’. Точно так же мы можем использовать символ точки любое количество раз для нашего шаблона поиска, например:
Этот поисковый термин будет искать слово, которое начинается с ‘T’, оканчивается на ‘h’ и может содержать любые шесть символов в середине.
Квадратные скобки используются для определения диапазона символов. Например, когда нужно искать один из перечисленных символов, а не любой символ, как в случае с точкой:
Здесь мы ищем слово, которое начинается с ‘N’, оканчивается на ‘n’ и может иметь только ‘o’, ‘e’ или ‘n’ в середине. В квадратных скобках можно использовать любое количество символов. Мы также можем определить диапазоны, такие как ‘a-e’ или ‘1-18’, как список совпадающих символов в квадратных скобках.
Это похоже на оператор отрицания для регулярных выражений. Использование означает, что поиск будет включать в себя все символы, кроме тех, которые указаны в квадратных скобках. Например:
Это означает, что у нас могут быть все слова, которые начинаются с ‘St’, оканчиваются буквой ‘d’ и не содержат цифр от 1 до 9.
До сих пор мы использовали примеры регулярных выражений, которые ищут только один символ. Но что делать в иных случаях? Допустим, если требуется найти все слова, которые начинаются или оканчиваются символом или могут содержать любое количество символов в середине. С этой задачей справляются так называемые метасимволы-квантификаторы, определяющие сколько раз может встречаться предшествующее выражение: + * & ?
{n}, {n m}, {n, } или { ,m} также являются примерами других квантификаторов, которые мы можем использовать в терминах регулярных выражений.
* (звездочка)
На следующем примере показано любое количество вхождений буквы ‘k’, включая их отсутствие:
Это означает, что у нас может быть совпадение с ‘lake’ или ‘la’ или ‘lakkkkk’.
+
Следующий шаблон требует, чтобы хотя бы одно вхождение буквы ‘k’ в строке совпадало:
Здесь буква ‘k’ должна появляться хотя бы один раз, поэтому наши результаты могут быть ‘lake’ или ‘lakkkkk’, но не ‘la’.
?
В следующем шаблоне результатом будет строка bb или bab:
С заданным квантификатором ‘?’ мы можем иметь одно вхождение символа или ни одного.
Важное примечание! Предположим, у нас есть регулярное выражение:
И мы получаем результаты ‘Small’, ‘Silly’, и ещё ‘Susan is a little to play ball’. Но почему мы получили ‘Susan is a little to play ball’, ведь мы искали только слова, а не полное предложение?
Все дело в том, что это предложение удовлетворяет нашим критериям поиска: оно начинается с буквы ‘S’, имеет любое количество символов в середине и заканчивается буквой ‘l’. Итак, что мы можем сделать, чтобы исправить наше регулярное выражение, чтобы в качестве выходных данных мы получали только слова вместо целых предложений.
Для этого в регулярное выражение нужно добавить квантификатор ‘?’:
или символ экранирования
Символ » используется, когда необходимо включить символ, который является метасимволом или имеет специальное значение для регулярного выражения. Например, требуется найти все слова, заканчивающиеся точкой. Для этого можем использовать выражение:
Оно будет искать и сопоставлять все слова, которые заканчиваются точкой.
Итак, вы получили общее представление о том, как работают регулярные выражения. Практикуйтесь как можно больше, создавайте регулярные выражения и старайтесь включать их в свою работу как можно чаще. Проверять правильность использования своих регулярных выражений на конкретном примере можно на специальном сайте.
COLOPHON top
This page is part of the GNU grep (regular expression file search
tool) project. Information about the project can be found at
⟨https://www.gnu.org/software/grep/⟩. If you have a bug report for
this manual page, send it to bug-grep@gnu.org. This page was ob‐
tained from the project's upstream Git repository
⟨git://git.savannah.gnu.org/grep.git⟩ on 2020-11-01. (At that time,
the date of the most recent commit that was found in the repository
was 2020-10-11.) If you discover any rendering problems in this HTML
version of the page, or you believe there is a better or more up-to-
date source for the page, or you have corrections or improvements to
the information in this COLOPHON (which is not part of the original
manual page), send a mail to man-pages@man7.org
GNU grep 3.5.11-df33-dirty 2019-12-29 GREP(1)
Pages that refer to this page:
look(1),
pcp2csv(1),
pmrep(1),
sed(1),
regcomp(3),
regerror(3),
regex(3),
regexec(3),
regfree(3),
regex(7),
bridge(8),
ip(8),
tc(8)








