Как узнать историю домена и сайта на нём?
Содержание:
- Плюсы и минусы привлечения подписчиков без накрутки
- Всемирный Веб архив сайтов интернета
- Элементы сайта-истории
- Возможности использования веб-архивов
- Как сделать бэкап сайта и спать спокойно?
- Как использовать веб-архив?
- WWW: Сервис oldweb.today позволяет заглянуть в прошлое интернета
- Создание резервной копии сайта через панель управления хостинга
- archive.md
- Вконтакте
- Бесплатные способы восстановления
- Скопировать из браузера
- Какие есть ограничения у копий
- Вконтакте
- В наши дни создатель первого сайта выступает за свободный интернет
Плюсы и минусы привлечения подписчиков без накрутки
Любому аккаунту нужны подписчики, которых можно найти, не прибегая к накрутке. При этом следует знать плюсы и минусы такого продвижения.
Достоинства:
- Нет риска блокировки аккаунта.
- К аккаунту присоединяются живые подписчики.
- Профиль можно раскрутить без материальных вливаний.
Недостатки:
- Работу по увеличению вовлеченности аудитории нужно проводить регулярно.
- Понадобится много времени для осуществления мероприятий по привлечению фолловеров.
- Не все методы раскрутки увеличат количество подписчиков.
Обратите внимание! В эпоху коронавируса все ищут дополнительные возможности заработка. Удивительно, что альтернативными способами зарабатывать можно гораздо больше, вплоть до миллионов рублей в месяц
Один из наших лучших авторов написал отличную статью про заработок на играх с отзывами людей.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
Элементы сайта-истории
Любая история – это в первую очередь повествование. История на сайте – не исключение.
Повествование складывается из следующих элементов:
- Персонаж. Выступать в качестве персонажа может продукт компании, сам бренд или что-то еще. Может быть и вымышленный персонаж, который несет в себе собирательный образ, например, целевой аудитории компании.
- Конфликт (событие). В роли конфликта могут быть какие-либо волнующие целевую аудиторию проблемы. Ситуации, в которые попадает клиент и в решении которых может помочь компания.
- Действие. Это те действия, который должен совершить клиент, чтобы решить конфликт, проблему. И в истории рассказывается, какие это должны быть действия. Тут могут быть и действия, которые совершает компания, чтобы решить проблему клиента. Часто описывается конечный результат действий, положительные эмоции от использования продукта, счастье клиента после того, как проблема решена.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Как сделать бэкап сайта и спать спокойно?
Давайте поговорим откровенно, как говориться пока петух не клюнет, никто не хочет ничего делать и заботится о той или иной проблеме. Таже ситуация относится и к безопасности сайта. Многие владельцы работают в сети, делают свою работу, пишут блоги и даже могут не знать, что на их сайт попал вирус или же с зараженного компьютера или со скаченного на сомнительном сайте стороннего расширения в котором имелась брешь в безопасности.
Если Вы получите вирус на свой сайт то готовьтесь к тому что поисковые системы его обнаружат и пометят в поиске да и просто при его открытии как “Данные сайт может угрожать вашему компьютеру” и закроет доступ пользователя к нему а отсюда следует, что Вы будите терять аудиторию и доверие поисковиков которое Вы так долго заслуживали.
Когда произойдет беда а она может случиться в любой момент, скажу Вам у меня лично был вирус на одном из первых сайтов когда я только этому учился и после того как специалист начал анализ сайта оказалось что вирус сидел долгое время и это как замедленная бомба. Получилось так что она активировалась через несколько недель, а бэкапы сайтов хранятся не так долг как хотелось бы и поверх чистых резервных копий запишутся и зараженные а тут уже деваться некуда будет кроме как чистить сайт и проверять все файлы. Поэтому кроме создании бэкапа сайта на самом хостинге я советую делать резервную копию еще и себе на компьютер и просто отправлять в облачное хранилище, такое как приложение Яндекс.Диск или Гугл-диск, лично я делаю так, береженого бог бережет как говорится.
Давайте рассмотрим процесс создания резервной копии файлов своего сайта на Вашем хостинге, я это буду показывать на примере одного из сайтов. Для этого нам нужно создать соединение с хостером где хранится сайт либо через панель управления или же воспользоваться FTP соединением.
Как использовать веб-архив?
 Форма для поиска информации на Peeep.us
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
WWW: Сервис oldweb.today позволяет заглянуть в прошлое интернета
Если ты застал ранние деньки интернета, то наверняка любишь поностальгировать: вспомнить диалап и домашние страницы с гифками, первую версию «Яндекса» с окурком, старый добрый Netscape Navigator и прочие радости почти двадцатилетней давности. Если же ты добрался до Сети только в двухтысячных, то тебе будет полезно узнать, с чего всё начиналось.
Удовлетворить любопытство или потешить ностальгию можно при помощи Internet Archive: вбил адрес, выбрал дату, дождался загрузки и перед тобой давняя-предавняя версия какого-нибудь сайта. Но всё же смотреть на старый интернет через современный браузер слегка неспортивно.
Сервис oldweb.today (это и название и очень удачный URL) предоставляет куда более полный экспириенс. Когда ты задашь URL и дату, в твоем браузере откроется окно с виртуальной машиной, в которой крутится старая операционная система и один из старых браузеров. На выбор NSCA Mosaic 2.2, Netscape Navigator 3 и 4 и Internet Explorer 4 и 5.

Данные сайтов будут подгружаться из всё того же Internet Archive, но для витуалки эти данные будут выглядеть как самый настоящий интернет. Каждая сессия может длиться не дольше десяти минут, но этого вполне достаточно, чтобы испытать мощное умиление или шок от того, как убого раньше выглядели сайты. А если время выйдет, то никто не мешает загрузить по новой.
В основе oldweb.today — технология Docker, с которой читатели Х должны быть отлично знакомы (если ты не знаком, см. номер 196 за май 2015). Внутри Docker поднимается эмулятор старой ОС, и уже в нем — браузер, окно которого и транслируется пользователю. Для особо любопытных есть исходники всей пирамиды.
Создание резервной копии сайта через панель управления хостинга
Создавать соединение с хостингом думаю не надо учить никого так как все уже там были раз создали свой сайт, достаточно просто ввести свой логин и пароль и Вы попадете в свою панель управления. Панели конечно будут отличаться (у меня к примеру хостинг timeweb) но суть везде одинакова и нам нужно найти раздел “BackUp” в моем случае резервные копии где мы и будем проводить все манипуляции с нашими файлами.
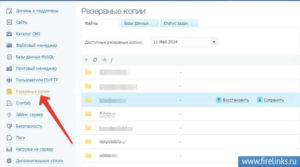
В нашем разделе выбираем “сохранить” и переходим в раздел “Статус задач” где мы отслеживаем ход выполнения данной команды. Если Вы запросили сохранение резервной копии то Вам еще придет письмо на почту аккаунта для избежание мошеннических действий.


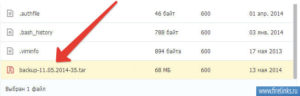
Ну вот уже половину мы с вами сделали, не так уж и сложно. Думаю каждый разберется на своем хостинге за пару минут, ну уж если будут проблемы у всех хостеров имеются службы поддержки или же разделы вопрос-ответ.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Вконтакте
Ради прикола я еще решил проверить социальную сеть вконтакте и посмотреть предыдущие версии этого сайта. Все мы помним, что сеть начала свою деятельность еще в 2006 году и тогда сайт располагался по адресу vkontakte.ru, а не vk.com. Вот его я и решил ввести и посмотреть его в 2006 году. Вы помните такой дизайн? Вот таким он был.

Я зарегистрировался в 2007 году (помню, как даже смотрел дату регистрации в вк) и вот так выглядел тогда этот сайт.
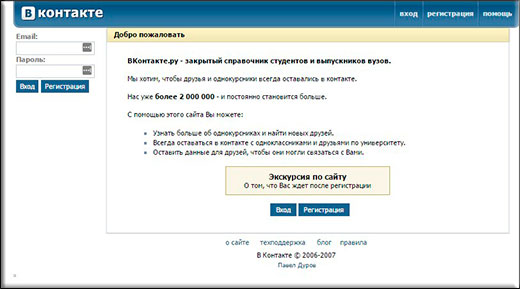
В 2011 году ВК ограничил свободные регистрации в связи с наплывом фейковых страниц. там просто так было нельзя. Нужно было получить приглашение от зарегистрированного пользователя. И вот тогда главная страница смотрелась так.
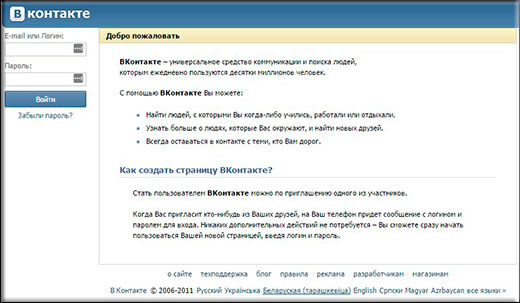
А с 2012 года сайт переходит на новый домен vk.com, и со старого происходит автоматическая переадресация. Поэтому с этого момента у вас не получится посмотреть, как выглядел vkontakte.ru например в 2013 году, так как надо вводить уже современный адрес и смотреть там.

В общем как-то так. Здорово, да? Я вот прошелся по старым дизайна вконтакте, и аж ностальгия взяла. Когда я регистрировался, там находилось всего чуть более миллиона человек. А теперь там сотни миллионов.
Ну в общем рекомендую вам тоже пройтись по задворкам прошлого и взглянуть, как всё выглядело раньше. А на сегодня я уже буду закругляться. Надеюсь, что статья была для вас интересной, поэтому не забудьте подписаться на обновления моего блога. С нетерпением буду вас снова ждать у себя в гостях. Удачи вам. Пока-пока!
Бесплатные способы восстановления
Ручной
Собственно основной ресурс, который используют все сервисы для восстановления сайта это https://archive.org/web/
Ниже отображается календарь за выбранный год, там вы можете увидеть конкретный месяц и день, когда был произведен снимок.
Кликайте по снимку, откроется окно со страницей сайта за тот день. Открываете консоль разработчика и копируете html и все ресурсы необходимые странице — картинки, css, js и др. Неблагодарное дело.
Аналоги archive.org
https://archive.org/web/ не единственый проект, который делает снимки сайтов и хранит их. Существуют и другие напримерArchive.ishttp://timetravel.mementoweb.org/ уникальный проект, своего рода гугл по сайтам-аналогам archive.org
Веб кэш
Если нужно восстановить данные сайта, которые были потеряны недавно, может подойти кэш поисковой системы Гугл. Можно попробовать тут https://thisis-blog.ru/posmotret-sajt-v-keshe/
Библиотеки
Можно развернуть и свою поделку под свои нужды, если есть возможность. На гитхабе ищется по ключу wayback-machine
Что там можно найти, примеры:
https://pypi.org/project/wayback-scraper/https://github.com/sangaline/wayback-machine-scraperhttps://github.com/hartator/wayback-machine-downloader
Делитесь своим опытом использования данных сервисов. Если нашли ошибку, либо есть что добавить, тоже пишите.
Скопировать из браузера
Можно перенести данные из обозревателя в любой текстовый редактор. Для этого лучше всего подойдёт Microsoft Word. В нём корректно отображаются изображения и форматирование. Хотя из-за специфики документа может не очень эстетично выглядеть реклама, меню и некоторые фреймы.
Вот как скопировать страницу сайта:
- Откройте нужный URL.
- Нажмите Ctrl+A. Или кликните правой кнопкой мыши по любой свободной от картинок и flash-анимации области и в контекстном меню выберите «Выделить». Это надо сделать для охвата всей информации, а не какого-то произвольного куска статьи.
- Ctrl+C. Или в том же контекстном меню найдите опцию «Копировать».
- Откройте Word.
- Поставьте курсор в документ и нажмите клавиши Ctrl+V.
- После этого надо сохранить файл.
Иногда получается так, что переносится только текст. Если вам нужен остальной контент, можно взять и его. Вот как скопировать страницу веб-ресурса полностью — со всеми гиперссылками, рисунками:
- Проделайте предыдущие шаги до пункта 4.
- Кликните в документе правой кнопкой мыши.
- В разделе «Параметры вставки» отыщите кнопку «Сохранить исходное форматирование». Наведите на неё — во всплывающей подсказке появится название. Если у вас компьютер с Office 2007, возможность выбрать этот параметр появляется только после вставки — рядом с добавленным фрагментом отобразится соответствующая пиктограмма.

Способ №1: копипаст
В некоторых случаях нельзя скопировать графику и форматирование. Только текст. Даже без разделения на абзацы. Но можно сделать скриншот или использовать специальное программное обеспечение для переноса содержимого страницы на компьютер.
Сайты с защитой от копирования
Иногда на ресурсе стоит так называемая «Защита от копирования». Она заключается в том, что текст на них нельзя выделить или перенести в другое место. Но это ограничение можно обойти. Вот как это сделать:
- Щёлкните правой кнопкой мыши в любом свободном месте страницы.
- Выберите «Исходный код» или «Просмотр кода».
- Откроется окно, в котором вся информация находится в html-тегах.
- Чтобы найти нужный кусок текста, нажмите Ctrl+F и в появившемся поле введите часть слова или предложения. Будет показан искомый отрывок, который можно выделять и копировать.
Если вы хотите сохранить на компьютер какой-то сайт целиком, не надо полностью удалять теги, чтобы осталась только полезная информация. Можете воспользоваться любым html-редактором. Подойдёт, например, FrontPage. Разбираться в веб-дизайне не требуется.
- Выделите весь html-код.
- Откройте редактор веб-страниц.
- Скопируйте туда этот код.
- Перейдите в режим просмотра, чтобы увидеть, как будет выглядеть копия.
- Перейдите в Файл — Сохранить как. Выберите тип файла (лучше оставить по умолчанию HTML), укажите путь к папке, где он будет находиться, и подтвердите действие. Он сохранится на электронную вычислительную машину.
Защита от копирования может быть привязана к какому-то js-скрипту. Чтобы отключить её, надо в браузере запретить выполнение JavaScript. Это можно сделать в настройках веб-обозревателя. Но из-за этого иногда сбиваются параметры всей страницы. Она будет отображаться неправильно или выдавать ошибку. Ведь там работает много различных скриптов, а не один, блокирующий выделение.
Если на сервисе есть подобная защита, лучше разобраться, как скопировать страницу ресурса глобальной сети другим способом. Например, можно создать скриншот.
Какие есть ограничения у копий
Хочу внести ясность, что скопированный проект, даже если он точь-в-точь будет выглядеть как оригинал, это не означает что будут работать все функции. Не будет работать функционал, который исполняется на сервере, т.е. различные калькуляторы, опросы, подбор по параметрам — работать не будут 99%. Если функционал реализован с помощью Javascript, то будет работать.
Но .php скрипты скачать с сервера НЕВОЗМОЖНО, вообще НИКАК. Также не будут работать формы обратной связи и подачи заявок без ручных доработок. Учтите, что некоторые сайты имеют защиту от скачивания, и в таком случае вы получите пустую страницу или сообщение об ошибке.
Вконтакте
Чего только не скрывалось под популярным ныне доменом vk.com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.
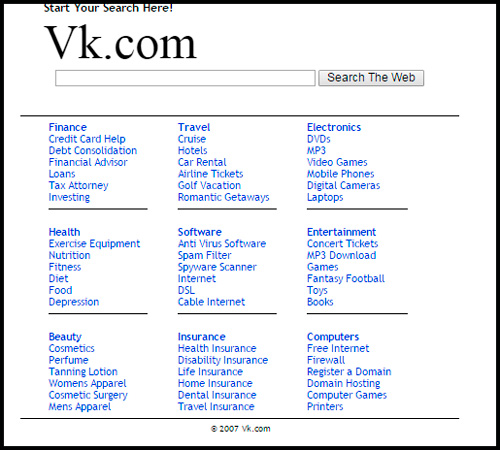
Кстати, само название социальной сети стало производным от фразы, которую Павел Дуров, создатель, постоянно слышал по радио «Эхо Москвы». Она звучала как «В полном контакте с информацией».
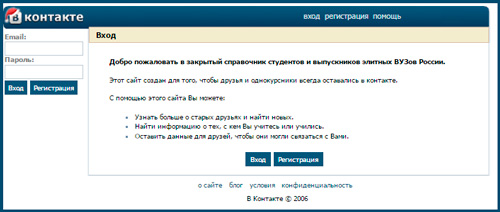
Изначально проект был создан как закрытый справочник студентов и выпускников. Об этом свидетельствует надпись на главной странице того периода.
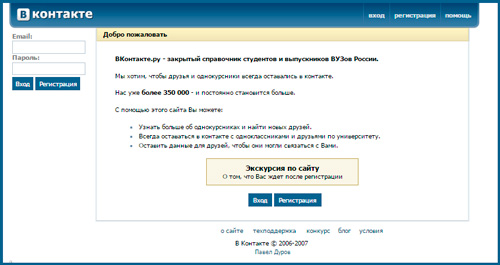
Мог ли тогда представить Павел Дуров, насколько популярным станет его проект? Сейчас даже смешно смотреть на горделивую надпись: «Нас уже 350 000». Сейчас численность проекта насчитывает миллионы.
Интересных историй о этой социальной сети предостаточно, но на мой взгляд самая впечатляющая заключается в том, что вплоть до 2014 года через Одноклассники нельзя было послать ссылку на информацию, находящуюся Вконтакте. Система не блокировала их, а просто заменяла буквы в словах.
Еще один интересный факт, о котором многие пользователи помнят. В какой-то момент администрация сайта решила поменять дизайн личных страниц. Это вызвало бурю эмоций среди пользователей.
И тут и там кипели возгласы: «Верните стену, нет микроблогу». Павел Дуров был не преклонен. В моей памяти эти воспоминания все еще свежи, а тем не менее с той поры прошло 6 лет. Военные действия разворачивались в 2010 году. Согласитесь, сейчас смотришь на этот кошмар и думаешь, что там могло нравиться, за что воевали?

Интересный момент, но благодаря социальным сетям люди не только общаются между собой и зарабатывают, но и достигают других интересных целей. Хоть в свое время дизайн стены не вернули, зато деятельность пользователей на Facebook и Вконтакте вернула в мультсериал «Гриффины» умершего пса Брайна.
Ну и на последок мне бы хотелось порекомендовать вам курс «Из зомби в интернет-предпринимателя». Становитесь популярными и вы, достигайте своих целей.

Если вы переживаете, что ничего не умеете и не знаете, просто посмотрите как изначально выглядел любой сайт, тот же Яндекс. Время решает многое. Мы растем, двигаемся вперед и учимся на своих ошибках.
Подписывайтесь на рассылку и я помогу вам справиться со сложностями. До новых встреч.
В наши дни создатель первого сайта выступает за свободный интернет
 Бернерс Ли выступает за реорганизацию интернета.
Бернерс Ли выступает за реорганизацию интернета.
Сегодня Бернерс Ли активно выступает за открытость интернета. К локализации персональных данных пользователей своей страны и идеям суверенного интернета он относится скептически.
Тим говорит, что любое разделение сети на сегменты — очень плохая идея. Причина бурного развития Веба заключалась в том, что интернет был негосударственным, открытым и общедоступным.
Бернерс Ли призывает все страны быть очень осторожными в попытках подчинить себе мировую паутину.
Интернет должен остаться свободным.
Это отдельный мир, со своими законами и правилами, который каждый день помогает и развлекает нас уже более 25 лет, но все еще далек от совершенства. Развивайся, интернет.

iPhones.ru
Недавно этому сайту исполнилось 28 лет, и его создатель все еще жив.








