Json в python
Содержание:
- Сериализация объектов Python для чтения при помощи других языков
- 19.2.2. Encoders and Decoders¶
- Standard Compliance and Interoperability¶
- Пример десериализации JSON Python
- Кодировщики и декодировщики
- Погружение
- 인코더와 디코더¶
- Implement a custom JSON decoder using json.load()
- Exceptions Related to JSON Library in Python:
- Сохранение данных в файл Pickle.
- Standard Compliance and Interoperability¶
- JSON to Python (Decoding)
- Performance
- 명령 줄 인터페이스¶
- Основы
- Сохранение данных в JSON
- All done!
Сериализация объектов Python для чтения при помощи других языков
Формат данных используемый модулем pickle Python-зависимый. Он не пытается быть совместимым с другими языками программирования. Если межязыковая совместимость есть среди ваших потребностей, вам следует присмотреться к форматам сериализации. Один из таких форматов JSON. «JSON» это аббревиатура от «JavaScript Object Notation», но не позволяйте имени обмануть вас — JSON был наверняка разработан для использования многими языками программирования.
Во — вторых, как и с любым текстовым форматом, существует проблема пробелов. JSON позволяет вставлять произвольное количество пробелов (табуляций, переводов строк, и пустых строк) между значениями. Пробелы в нем «незначащие», что значит, кодировщики JSON могут добавлять так много или так мало пробелов как захотят, и декодировщики JSON будут игнорировать пробелы между значениями. Это позволяет вам использовать красивый вывод(pretty-print) для отображения ваших данных в формате JSON, удобно отображать вложенные значения различными уровнями отступа так чтобы вы могли читать все в стандартном просмотрщике или текстовом редакторе. Модуль json в Python имеет опции красивого вывода во время кодирования данных.
19.2.2. Encoders and Decoders¶
- class (object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None)
-
Simple JSON decoder.
Performs the following translations in decoding by default:
JSON Python object dict array list string str number (int) int number (real) float true True false False null None It also understands , , and as their
corresponding values, which is outside the JSON spec.object_hook, if specified, will be called with the result of every JSON
object decoded and its return value will be used in place of the given
. This can be used to provide custom deserializations (e.g. to
support JSON-RPC class hinting).object_pairs_hook, if specified will be called with the result of every
JSON object decoded with an ordered list of pairs. The return value of
object_pairs_hook will be used instead of the . This
feature can be used to implement custom decoders that rely on the order
that the key and value pairs are decoded (for example,
will remember the order of insertion). If
object_hook is also defined, the object_pairs_hook takes priority.Changed in version 3.1: Added support for object_pairs_hook.
parse_float, if specified, will be called with the string of every JSON
float to be decoded. By default, this is equivalent to .
This can be used to use another datatype or parser for JSON floats
(e.g. ).parse_int, if specified, will be called with the string of every JSON int
to be decoded. By default, this is equivalent to . This can
be used to use another datatype or parser for JSON integers
(e.g. ).parse_constant, if specified, will be called with one of the following
strings: , , .
This can be used to raise an exception if invalid JSON numbers
are encountered.If strict is false ( is the default), then control characters
will be allowed inside strings. Control characters in this context are
those with character codes in the 0–31 range, including (tab),
, and .If the data being deserialized is not a valid JSON document, a
will be raised.- (s)
-
Return the Python representation of s (a instance
containing a JSON document).will be raised if the given JSON document is not
valid.
- (s)
-
Decode a JSON document from s (a beginning with a
JSON document) and return a 2-tuple of the Python representation
and the index in s where the document ended.This can be used to decode a JSON document from a string that may have
extraneous data at the end.
Standard Compliance and Interoperability¶
The JSON format is specified by RFC 7159 and by
ECMA-404.
This section details this module’s level of compliance with the RFC.
For simplicity, and subclasses, and
parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some
extensions that are valid JavaScript but not valid JSON. In particular:
-
Infinite and NaN number values are accepted and output;
-
Repeated names within an object are accepted, and only the value of the last
name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not
RFC-compliant, this module’s deserializer is technically RFC-compliant under
default settings.
Character Encodings
The RFC requires that JSON be represented using either UTF-8, UTF-16, or
UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets
ensure_ascii=True by default, thus escaping the output so that the resulting
strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in
terms of conversion between Python objects and
, and thus does not otherwise directly address
the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text,
and this module’s serializer does not add a BOM to its output.
The RFC permits, but does not require, JSON deserializers to ignore an initial
BOM in their input. This module’s deserializer raises a
when an initial BOM is present.
The RFC does not explicitly forbid JSON strings which contain byte sequences
that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16
surrogates), but it does note that they may cause interoperability problems.
By default, this module accepts and outputs (when present in the original
) code points for such sequences.
Infinite and NaN Number Values
The RFC does not permit the representation of infinite or NaN number values.
Despite that, by default, this module accepts and outputs ,
, and as if they were valid JSON number literal values:
>>> # Neither of these calls raises an exception, but the results are not valid JSON
>>> json.dumps(float('-inf'))
'-Infinity'
>>> json.dumps(float('nan'))
'NaN'
>>> # Same when deserializing
>>> json.loads('-Infinity')
-inf
>>> json.loads('NaN')
nan
In the serializer, the allow_nan parameter can be used to alter this
behavior. In the deserializer, the parse_constant parameter can be used to
alter this behavior.
Repeated Names Within an Object
The RFC specifies that the names within a JSON object should be unique, but
does not mandate how repeated names in JSON objects should be handled. By
default, this module does not raise an exception; instead, it ignores all but
the last name-value pair for a given name:
>>> weird_json = '{"x": 1, "x": 2, "x": 3}'
>>> json.loads(weird_json)
{'x': 3}
The object_pairs_hook parameter can be used to alter this behavior.
Top-level Non-Object, Non-Array Values
The old version of JSON specified by the obsolete RFC 4627 required that
the top-level value of a JSON text must be either a JSON object or array
(Python or ), and could not be a JSON null,
boolean, number, or string value. RFC 7159 removed that restriction, and
this module does not and has never implemented that restriction in either its
serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere
to the restriction yourself.
Пример десериализации JSON Python
На этот раз, представьте что у вас есть некие данные, хранящиеся на диске, которыми вы хотите манипулировать в памяти. Вам все еще нужно будет воспользоваться контекстным менеджером, но на этот раз, вам нужно будет открыть существующий data_file.json в режиме для чтения.
Python
with open(«data_file.json», «r») as read_file:
data = json.load(read_file)
|
1 |
withopen(«data_file.json»,»r»)asread_file data=json.load(read_file) |
Здесь все достаточно прямолинейно, но помните, что результат этого метода может вернуть любые доступные типы данных из таблицы конверсий
Это важно только в том случае, если вы загружаете данные, которые вы ранее не видели. В большинстве случаев, корневым объектом будет dict или list
Если вы внесли данные JSON из другой программы, или полученную каким-либо другим способом строку JSON форматированных данных в Python, вы можете легко десериализировать это при помощи loads(), который естественно загружается из строки:
Python
json_string = «»»
{
«researcher»: {
«name»: «Ford Prefect»,
«species»: «Betelgeusian»,
«relatives»:
}
}
«»»
data = json.loads(json_string)
|
1 |
json_string=»»» { } data=json.loads(json_string) |
Ву а ля! Вам удалось укротить дикого JSON, теперь он под вашим контролем. Но что вы будете делать с этой силой — остается за вами. Вы можете кормить его, выращивать, и даже научить новым приемам. Не то чтобы я не доверяю вам, но держите его на привязи, хорошо?
Кодировщики и декодировщики
Класс json.JSONDecoder(object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None) — простой декодер JSON.
Выполняет следующие преобразования при декодировании:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
Он также понимает NaN, Infinity, и -Infinity как соответствующие значения float, которые находятся за пределами спецификации JSON.
Класс json.JSONEncoder(skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, sort_keys=False, indent=None, separators=None, default=None)
Расширяемый кодировщик JSON для структур данных Python. Поддерживает следующие объекты и типы данных по умолчанию:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
Погружение
С первого взгляда, идея сериализации проста. У вас есть структура данных в памяти, которую вы хотите сохранить, использовать повторно, или отправить кому либо. Как вам это сделать? Это зависит от того как вы ее сохраните, как вы ее хотите использовать, и кому вы ее хотите отправить. Многие игры позволяют вам сохранять ваш прогресс перед выходом и возобновлять игру после запуска. (Вообще, многие неигровые приложения также позволяют это делать). В этом случае, структура, которая хранит ваш прогресс в игре, должна быть сохранена на диске, когда вы закрываете игру, и загружена с диска, когда вы ее запускаете. Данные предназначены только для использования той же программой что и создала их, никогда не посылаются по сети, и никогда не читаются ничем кроме программы их создавшей. Поэтому проблемы совместимости ограничены тем, чтобы более поздние версии программы могли читать данные созданные ранними версиями.
Для таких случаев модуль pickle идеален. Это часть стандартной библиотеки Python, поэтому он всегда доступен. Он быстрый, большая часть написана на C, как и сам интерпретатор Python. Он может сохранять совершенно произвольные комплексные структуры данных Python.
Что может сохранять модуль pickle?
- Все встроенные типы данных Python: тип boolean, Integer, числа с плавающей точкой, комплексные числа, строки, объекты bytes, массивы байт, и None.
- Списки, кортежи, словари и множества, содержащие любую комбинацию встроенных типов данных
- Списки, кортежи, словари и множества, содержащие любую комбинацию списков, кортежей, словарей и множеств содержащий любую комбинацию встроенных типов данных (и так далее, вплоть до максимального уровня вложенности, который поддерживает Python).
- Функции, классы и экземпляры классов (с caveats).
Если для вас этого мало, то модуль pickle еще и расширяем. Если вам интересна эта возможность, то смотрите ссылки в разделе «Дальнейшее чтение» в конце этой главы.
인코더와 디코더¶
- class (*, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None)
-
간단한 JSON 디코더.
기본적으로 디코딩할 때 다음과 같은 변환을 수행합니다:
JSON
파이썬
오브젝트(object)
dict
배열(array)
list
문자열(string)
str
숫자 (정수)
int
숫자 (실수)
float
true
True
false
False
null
None
또한, , 및 를 해당 값으로 이해합니다. 이 값은 JSON 명세에 속하지 않습니다.
object_hook이 지정되면, 모든 JSON 오브젝트의 디코딩된 결과로 호출되며, 반환 값을 주어진 대신 사용합니다. 사용자 정의 역 직렬화를 제공하는 데 사용할 수 있습니다 (예를 들어, JSON-RPC 클래스 힌팅을 지원하기 위해).
object_pairs_hook이 지정되면 모든 오브젝트 리터럴의 쌍의 순서 있는 목록으로 디코딩된 결과로 호출됩니다. 대신 object_pairs_hook의 반환 값이 사용됩니다. 이 기능은 사용자 정의 디코더를 구현하는 데 사용할 수 있습니다. object_hook도 정의되어 있으면, object_pairs_hook이 우선순위를 갖습니다.
버전 3.1에서 변경: object_pairs_hook에 대한 지원이 추가되었습니다.
parse_float가 지정되면, 디코딩될 모든 JSON float의 문자열로 호출됩니다. 기본적으로, 이것은 와 동등합니다. JSON float에 대해 다른 데이터형이나 구문 분석기를 사용하고자 할 때 사용될 수 있습니다 (예를 들어, ).
parse_int가 지정되면, 디코딩될 모든 JSON int의 문자열로 호출됩니다. 기본적으로 이것은 와 동등합니다. JSON 정수에 대해 다른 데이터형이나 구문 분석기를 사용하고자 할 때 사용될 수 있습니다 (예를 들어 ).
parse_constant가 지정되면, 다음과 같은 문자열 중 하나로 호출됩니다: , , . 잘못된 JSON 숫자를 만날 때 예외를 발생시키는 데 사용할 수 있습니다.
strict가 거짓이면 (가 기본값입니다), 문자열 안에 제어 문자가 허용됩니다. 이 문맥에서 제어 문자는 0–31 범위의 문자 코드를 가진 것들인데, (탭), , 및 을 포함합니다.
역 직렬화되는 데이터가 유효한 JSON 문서가 아니면, 가 발생합니다.
버전 3.6에서 변경: 모든 매개 변수가 이제 입니다.
- (s)
-
s(JSON 문서가 포함된 인스턴스)의 파이썬 표현을 반환합니다.
주어진 JSON 문서가 유효하지 않으면 가 발생합니다.
- (s)
-
s(JSON 문서로 시작하는 )에서 JSON 문서를 디코딩하고, 파이썬 표현과 문서가 끝난 s에서의 인덱스로 구성된 2-튜플을 반환합니다.
끝에 여분의 데이터가 있을 수 있는 문자열에서 JSON 문서를 디코딩하는 데 사용할 수 있습니다.
Implement a custom JSON decoder using json.load()
The built-in json module of Python can only handle Python primitives types that have a direct JSON equivalent (e.g., dictionary, lists, strings, numbers, None, etc.).
When you execute a or method, it returns a Python dictionary. If you want to convert JSON into a custom Python object then we can write a custom JSON decoder and pass it to the method so we can get a custom Class object instead of a dictionary.
Let’s see how to use the JSON decoder in the load method. In this example, we will see how to use parameter of a load method.
Output:
After Converting JSON into Movie Object Interstellar 2014 7000000
Also read:
- Check if a key exists in JSON and Iterate the JSON array
- Python Parse multiple JSON objects from file
Exceptions Related to JSON Library in Python:
- Class json.JSONDecoderError handles the exception related to decoding operation. and it’s a subclass of ValueError.
- Exception — json.JSONDecoderError(msg, doc)
- Parameters of Exception are,
- msg – Unformatted Error message
- doc – JSON docs parsed
- pos – start index of doc when it’s failed
- lineno – line no shows correspond to pos
- colon – column no correspond to pos
Example,
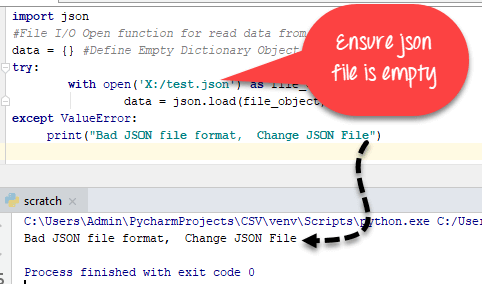
import json
#File I/O Open function for read data from JSON File
data = {} #Define Empty Dictionary Object
try:
with open('json_file_name.json') as file_object:
data = json.load(file_object)
except ValueError:
print("Bad JSON file format, Change JSON File")
Сохранение данных в файл Pickle.
Модуль Pickle работает со структурами данных. Давайте создадим одну.
>>> shell 1 ①>>> entry = {} ②>>> entry’title’ = ‘Dive into history, 2009 edition’>>> entry’article_link’ = ‘http://diveintomark.org/archives/2009/03/27/dive-into-history-2009-edition’>>> entry’comments_link’ = None>>> entry’internal_id’ = b’\xDE\xD5\xB4\xF8′>>> entry’tags’ = (‘diveintopython’, ‘docbook’, ‘html’)>>> entry’published’ = True>>> import time>>> entry’published_date’ = time.strptime(‘Fri Mar 27 22:20:42 2009′) ③>>> entry’published_date’ time.struct_time(tm_year=2009, tm_mon=3, tm_mday=27, tm_hour=22, tm_min=20, tm_sec=42, tm_wday=4, tm_yday=86, tm_isdst=-1)
① Все дальнейшее происходит в консоли Python #1.
② Идея в том чтобы создать словарь, который будет представлять что-нибудь полезное, например элемент рассылки Atom. Также я хочу быть уверенным, что он содержит несколько разных типов данных, чтобы раскрыть возможности модуля pickle. Не вчитывайтесь слишком сильно в эти переменные.
③ Модуль time содержит структуру данных (struct_time) для представления момента времени (вплоть до миллисекунд) и функции для работы с этими структурами. Функция strptime() принимает на вход форматированную строку и преобразует ее в struct_time. Эта строка в стандартном формате, но вы можете контролировать ее при помощи кодов форматирования. Для более подробного описания загляните в модуль time.
Теперь у нас есть замечательный словарь. Давайте сохраним его в файл.
>>> shell ①1>>> import pickle>>> with open(‘entry.pickle’, ‘wb’) as f: ②
… pickle.dump(entry, f) ③
…
① Мы все еще в первой консоли
② Используйте функцию open() для того чтобы открыть файл. Установим режим работы с файлом в ‘wb’ для того чтобы открыть файл для записи в двоичном режиме. Обернем его в конструкцию with для того чтобы быть уверенным в том что файл закроется автоматически, когда вы завершите работу с ним.
③ Функция dump() модуля pickle принимает сериализуемую структуру данных Python, сериализует ее в двоичный, Python-зависимый формат использует последнюю версию протокола pickle и сохраняет ее в открытый файл.
Последнее предложение было очень важным.
- Протокол pickle зависит от Python; здесь нет гарантий совместимости с другими языками. Вы возможно не сможете взять entry.pickle файл, который только что сделали и как — либо с пользой его использовать при помощи Perl, PHP, Java или любого другого языка программирования
- Не всякая структура данных Python может быть сериализована модулем Pickle. Протокол pickle менялся несколько раз с добавлением новых типов данных в язык Python, и все еще у него есть ограничения.
- Как результат, нет гарантии совместимости между разными версиями Python. Новые версии Python поддерживают старые форматы сериализации, но старые версии Python не поддерживают новые форматы (поскольку не поддерживают новые форматы данных)
- Пока вы не укажете иное, функции модуля pickle будут использовать последнюю версию протокола pickle. Это сделано для уверенности в том, что вы имеете наибольшую гибкость в типах данных, которые вы можете сериализовать, но это также значит, что результирующий файл будет невозможно прочитать при помощи старых версий Python, которые не поддерживают последнюю версию протокола pickle.
- Последняя версия протокола pickle это двоичный формат. Убедитесь, что открываете файлы pickle в двоичном режиме, или данные будут повреждены при записи.
Standard Compliance and Interoperability¶
The JSON format is specified by RFC 7159 and by
ECMA-404.
This section details this module’s level of compliance with the RFC.
For simplicity, and subclasses, and
parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some
extensions that are valid JavaScript but not valid JSON. In particular:
-
Infinite and NaN number values are accepted and output;
-
Repeated names within an object are accepted, and only the value of the last
name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not
RFC-compliant, this module’s deserializer is technically RFC-compliant under
default settings.
Character Encodings
The RFC requires that JSON be represented using either UTF-8, UTF-16, or
UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets
ensure_ascii=True by default, thus escaping the output so that the resulting
strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in
terms of conversion between Python objects and
, and thus does not otherwise directly address
the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text,
and this module’s serializer does not add a BOM to its output.
The RFC permits, but does not require, JSON deserializers to ignore an initial
BOM in their input. This module’s deserializer raises a
when an initial BOM is present.
The RFC does not explicitly forbid JSON strings which contain byte sequences
that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16
surrogates), but it does note that they may cause interoperability problems.
By default, this module accepts and outputs (when present in the original
) code points for such sequences.
Infinite and NaN Number Values
The RFC does not permit the representation of infinite or NaN number values.
Despite that, by default, this module accepts and outputs ,
, and as if they were valid JSON number literal values:
>>> # Neither of these calls raises an exception, but the results are not valid JSON
>>> json.dumps(float('-inf'))
'-Infinity'
>>> json.dumps(float('nan'))
'NaN'
>>> # Same when deserializing
>>> json.loads('-Infinity')
-inf
>>> json.loads('NaN')
nan
In the serializer, the allow_nan parameter can be used to alter this
behavior. In the deserializer, the parse_constant parameter can be used to
alter this behavior.
Repeated Names Within an Object
The RFC specifies that the names within a JSON object should be unique, but
does not mandate how repeated names in JSON objects should be handled. By
default, this module does not raise an exception; instead, it ignores all but
the last name-value pair for a given name:
>>> weird_json = '{"x": 1, "x": 2, "x": 3}'
>>> json.loads(weird_json)
{'x': 3}
The object_pairs_hook parameter can be used to alter this behavior.
Top-level Non-Object, Non-Array Values
The old version of JSON specified by the obsolete RFC 4627 required that
the top-level value of a JSON text must be either a JSON object or array
(Python or ), and could not be a JSON null,
boolean, number, or string value. RFC 7159 removed that restriction, and
this module does not and has never implemented that restriction in either its
serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere
to the restriction yourself.
JSON to Python (Decoding)
JSON string decoding is done with the help of inbuilt method loads() & load() of JSON library in Python. Here translation table show example of JSON objects to Python objects which are helpful to perform decoding in Python of JSON string.
| JSON | Python |
| Object | dict |
| Array | list |
| String | unicode |
| number – int | number — int, long |
| number – real | float |
| True | True |
| False | False |
| Null | None |
Let’s see a basic example of decoding in Python with the help of json.loads() function,
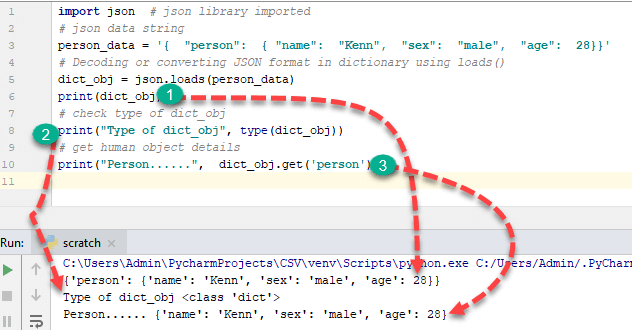
import json # json library imported
# json data string
person_data = '{ "person": { "name": "Kenn", "sex": "male", "age": 28}}'
# Decoding or converting JSON format in dictionary using loads()
dict_obj = json.loads(person_data)
print(dict_obj)
# check type of dict_obj
print("Type of dict_obj", type(dict_obj))
# get human object details
print("Person......", dict_obj.get('person'))
Output:
{'person': {'name': 'Kenn', 'sex': 'male', 'age': 28}}
Type of dict_obj <class 'dict'>
Person...... {'name': 'John', 'sex': 'male'}
Decoding JSON File or Parsing JSON file in Python
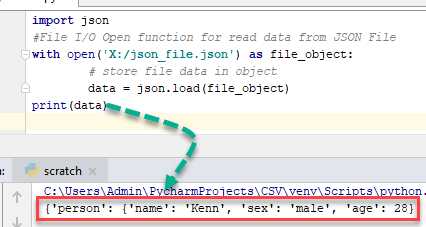
NOTE: Decoding JSON file is File Input /Output (I/O) related operation. The JSON file must exist on your system at specified the location that you mention in your program.
Example,
import json
#File I/O Open function for read data from JSON File
with open('X:/json_file.json') as file_object:
# store file data in object
data = json.load(file_object)
print(data)
Here data is a dictionary object of Python.
Output:
{'person': {'name': 'Kenn', 'sex': 'male', 'age': 28}}
Compact Encoding in Python
When you need to reduce the size of your JSON file, you can use compact encoding in Python.
Example,
import json
# Create a List that contains dictionary
lst =
# separator used for compact representation of JSON.
# Use of ',' to identify list items
# Use of ':' to identify key and value in dictionary
compact_obj = json.dumps(lst, separators=(',', ':'))
print(compact_obj)
Output:
'' ** Here output of JSON is represented in a single line which is the most compact representation by removing the space character from compact_obj **
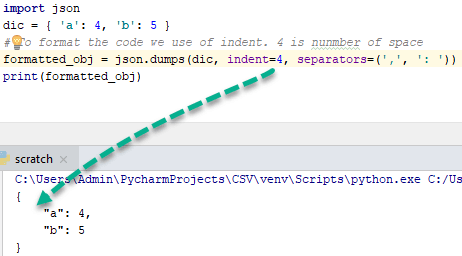
Format JSON code (Pretty print)
- The aim is to write well-formatted code for human understanding. With the help of pretty printing, anyone can easily understand the code.
- Example,
import json
dic = { 'a': 4, 'b': 5 }
''' To format the code use of indent and 4 shows number of space and use of separator is not necessary but standard way to write code of particular function. '''
formatted_obj = json.dumps(dic, indent=4, separators=(',', ': '))
print(formatted_obj)
Output:
{
"a" : 4,
"b" : 5
}
To better understand this, change indent to 40 and observe the output-
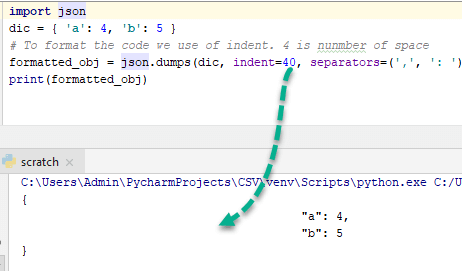
Ordering the JSON code:
sort_keys attribute in dumps() function’s argument will sort the key in JSON in ascending order. The sort_keys argument is a Boolean attribute. When it’s true sorting is allowed otherwise not
Example,
import json
x = {
"name": "Ken",
"age": 45,
"married": True,
"children": ("Alice", "Bob"),
"pets": ,
"cars": ,
}
# sorting result in asscending order by keys:
sorted_string = json.dumps(x, indent=4, sort_keys=True)
print(sorted_string)
Output:
{
"age": 45,
"cars": ,
"children": ,
"married": true,
"name": "Ken",
"pets":
}
As you may observe the keys age, cars, children, etc are arranged in ascending order.
Performance
Serialization and deserialization performance of orjson is better than
ultrajson, rapidjson, simplejson, or json. The benchmarks are done on
fixtures of real data:
-
twitter.json, 631.5KiB, results of a search on Twitter for «一», containing
CJK strings, dictionaries of strings and arrays of dictionaries, indented. -
github.json, 55.8KiB, a GitHub activity feed, containing dictionaries of
strings and arrays of dictionaries, not indented. -
citm_catalog.json, 1.7MiB, concert data, containing nested dictionaries of
strings and arrays of integers, indented. -
canada.json, 2.2MiB, coordinates of the Canadian border in GeoJSON
format, containing floats and arrays, indented.
Latency
twitter.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.59 | 1698.8 | 1 |
| ujson | 2.14 | 464.3 | 3.64 |
| rapidjson | 2.39 | 418.5 | 4.06 |
| simplejson | 3.15 | 316.9 | 5.36 |
| json | 3.56 | 281.2 | 6.06 |
twitter.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 2.28 | 439.3 | 1 |
| ujson | 2.89 | 345.9 | 1.27 |
| rapidjson | 3.85 | 259.6 | 1.69 |
| simplejson | 3.66 | 272.1 | 1.61 |
| json | 4.05 | 246.7 | 1.78 |
github.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.07 | 15265.2 | 1 |
| ujson | 0.22 | 4556.7 | 3.35 |
| rapidjson | 0.26 | 3808.9 | 4.02 |
| simplejson | 0.37 | 2690.4 | 5.68 |
| json | 0.35 | 2847.8 | 5.36 |
github.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.18 | 5610.1 | 1 |
| ujson | 0.28 | 3540.7 | 1.58 |
| rapidjson | 0.33 | 3031.5 | 1.85 |
| simplejson | 0.29 | 3385.6 | 1.65 |
| json | 0.29 | 3402.1 | 1.65 |
citm_catalog.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 0.99 | 1008.5 | 1 |
| ujson | 3.69 | 270.7 | 3.72 |
| rapidjson | 3.55 | 281.4 | 3.58 |
| simplejson | 11.76 | 85.1 | 11.85 |
| json | 6.89 | 145.1 | 6.95 |
citm_catalog.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 4.53 | 220.5 | 1 |
| ujson | 5.67 | 176.5 | 1.25 |
| rapidjson | 7.51 | 133.3 | 1.66 |
| simplejson | 7.54 | 132.7 | 1.66 |
| json | 7.8 | 128.2 | 1.72 |
canada.json serialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 4.72 | 198.9 | 1 |
| ujson | 17.76 | 56.3 | 3.77 |
| rapidjson | 61.83 | 16.2 | 13.11 |
| simplejson | 80.6 | 12.4 | 17.09 |
| json | 52.38 | 18.8 | 11.11 |
canada.json deserialization
| Library | Median latency (milliseconds) | Operations per second | Relative (latency) |
|---|---|---|---|
| orjson | 10.28 | 97.4 | 1 |
| ujson | 16.49 | 60.5 | 1.6 |
| rapidjson | 37.92 | 26.4 | 3.69 |
| simplejson | 37.7 | 26.5 | 3.67 |
| json | 37.87 | 27.6 | 3.68 |
Memory
orjson’s memory usage when deserializing is similar to or lower than
the standard library and other third-party libraries.
This measures, in the first column, RSS after importing a library and reading
the fixture, and in the second column, increases in RSS after repeatedly
calling on the fixture.
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 13.5 | 2.5 |
| ujson | 14 | 4.1 |
| rapidjson | 14.7 | 6.5 |
| simplejson | 13.2 | 2.5 |
| json | 12.9 | 2.3 |
github.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 13.1 | 0.3 |
| ujson | 13.5 | 0.3 |
| rapidjson | 14 | 0.7 |
| simplejson | 12.6 | 0.3 |
| json | 12.3 | 0.1 |
citm_catalog.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 14.6 | 7.9 |
| ujson | 15.1 | 11.1 |
| rapidjson | 15.8 | 36 |
| simplejson | 14.3 | 27.4 |
| json | 14 | 27.2 |
canada.json
| Library | import, read() RSS (MiB) | loads() increase in RSS (MiB) |
|---|---|---|
| orjson | 17.1 | 15.7 |
| ujson | 17.6 | 17.4 |
| rapidjson | 18.3 | 17.9 |
| simplejson | 16.9 | 19.6 |
| json | 16.5 | 19.4 |
Reproducing
The above was measured using Python 3.8.3 on Linux (x86_64) with
orjson 3.3.0, ujson 3.0.0, python-rapidson 0.9.1, and simplejson 3.17.2.
The latency results can be reproduced using the and
scripts. The memory results can be reproduced using the script.
명령 줄 인터페이스¶
소스 코드: Lib/json/tool.py
모듈은 JSON 객체의 유효성을 검사하고 예쁘게 인쇄하는 간단한 명령 줄 인터페이스를 제공합니다.
선택적 과 인자가 지정되지 않으면, 각각 과 이 사용됩니다:
$ echo '{"json": "obj"}' | python -m json.tool
{
"json": "obj"
}
$ echo '{1.2:3.4}' | python -m json.tool
Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
버전 3.5에서 변경: 출력은 이제 입력과 같은 순서입니다. 딕셔너리의 출력을 키에 대해 알파벳 순으로 정렬하려면 옵션을 사용하십시오.
명령 줄 옵션
-
유효성을 검사하거나 예쁘게 인쇄할 JSON 파일:
$ python -m json.tool mp_films.json { "title": "And Now for Something Completely Different", "year": 1971 }, { "title": "Monty Python and the Holy Grail", "year": 1975 }infile이 지정되지 않으면, 에서 읽습니다.
-
infile의 출력을 지정된 outfile에 씁니다. 그렇지 않으면, 에 씁니다.
-
딕셔너리의 출력을 키에 대해 알파벳 순으로 정렬합니다.
버전 3.5에 추가.
-
비 ASCII 문자의 이스케이프를 비활성화합니다. 자세한 내용은 를 참조하십시오.
버전 3.9에 추가.
-
모든 입력 행을 별도의 JSON 객체로 구문 분석합니다.
버전 3.8에 추가.
-
공백 제어를 위한 상호 배타적 옵션.
버전 3.9에 추가.
-
도움말 메시지를 표시합니다.
각주
-
the errata for RFC 7159에서 언급했듯이, JSON은 문자열에 U+2028(LINE SEPARATOR)과 U+2029(PARAGRAPH SEPARATOR) 문자를 허용하지만, JavaScript(ECMAScript Edition 5.1 기준)는 허용하지 않습니다.
Основы
json.dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw) — сериализует obj как форматированный JSON поток в fp.
Если skipkeys = True, то ключи словаря не базового типа (str, unicode, int, long, float, bool, None) будут проигнорированы, вместо того, чтобы вызывать исключение TypeError.
Если ensure_ascii = True, все не-ASCII символы в выводе будут экранированы последовательностями \uXXXX, и результатом будет строка, содержащая только ASCII символы. Если ensure_ascii = False, строки запишутся как есть.
Если check_circular = False, то проверка циклических ссылок будет пропущена, а такие ссылки будут вызывать OverflowError.
Если allow_nan = False, при попытке сериализовать значение с запятой, выходящее за допустимые пределы, будет вызываться ValueError (nan, inf, -inf) в строгом соответствии со спецификацией JSON, вместо того, чтобы использовать эквиваленты из JavaScript (NaN, Infinity, -Infinity).
Если indent является неотрицательным числом, то массивы и объекты в JSON будут выводиться с этим уровнем отступа. Если уровень отступа 0, отрицательный или «», то вместо этого будут просто использоваться новые строки. Значение по умолчанию None отражает наиболее компактное представление. Если indent — строка, то она и будет использоваться в качестве отступа.
Если sort_keys = True, то ключи выводимого словаря будут отсортированы.
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw) — сериализует obj в строку JSON-формата.
Аргументы имеют то же значение, что и для dump().
Ключи в парах ключ/значение в JSON всегда являются строками. Когда словарь конвертируется в JSON, все ключи словаря преобразовываются в строки. В результате этого, если словарь сначала преобразовать в JSON, а потом обратно в словарь, то можно не получить словарь, идентичный исходному. Другими словами, loads(dumps(x)) != x, если x имеет нестроковые ключи.
json.load(fp, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw) — десериализует JSON из fp.
object_hook — опциональная функция, которая применяется к результату декодирования объекта (dict). Использоваться будет значение, возвращаемое этой функцией, а не полученный словарь.
object_pairs_hook — опциональная функция, которая применяется к результату декодирования объекта с определённой последовательностью пар ключ/значение. Будет использован результат, возвращаемый функцией, вместо исходного словаря. Если задан так же object_hook, то приоритет отдаётся object_pairs_hook.
parse_float, если определён, будет вызван для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно float(num_str).
parse_int, если определён, будет вызван для строки JSON с числовым значением. По умолчанию эквивалентно int(num_str).
parse_constant, если определён, будет вызван для следующих строк: «-Infinity», «Infinity», «NaN». Может быть использовано для возбуждения исключений при обнаружении ошибочных чисел JSON.
Если не удастся десериализовать JSON, будет возбуждено исключение ValueError.
json.loads(s, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw) — десериализует s (экземпляр str, содержащий документ JSON) в объект Python.
Сохранение данных в JSON
Чтобы записать информацию в формате JSON с помощью средств языка Python, нужно прежде всего подключить модуль json, воспользовавшись командой import json в начале файла с кодом программы. Метод dumps отвечает за автоматическую упаковку данных в JSON, принимая при этом переменную, которая содержит всю необходимую информацию. В следующем примере демонстрируется кодирование словаря под названием dictData. В нем имеются некие сведения о пользователе интернет-портала, такие как идентификационный код, логин, пароль, полное имя, номер телефона, адрес электронной почты и данные об активности. Эти значения представлены в виде обычных строк, а также целых чисел и булевых литералов True/False.
import json
dictData = { "ID" : 210450,
"login" : "admin",
"name" : "John Smith",
"password" : "root",
"phone" : 5550505,
"email" : "smith@mail.com",
"online" : True }
jsonData = json.dumps(dictData)
print(jsonData)
{"ID": 210450, "login": "admin", "name": "John Smith", "password": "root", "phone": 5550505, "email": "smith@mail.com", "online": true}
Результат выполнения метода dumps передается в переменную под названием jsonData. Таким образом, словарь dictData был преобразован в JSON-формат всего одной строчкой. Как можно увидеть, благодаря функции print, все сведения были закодированы в своем изначальном виде. Стоит заметить, что данные из поля online были преобразованы из литерала True в true.
С помощью Python сделаем запись json в файл. Для этого дополним код предыдущего примера следующим образом:
with open("data.json", "w") as file:
file.write(jsonData)
Подробнее про запись данных в текстовые файлы описано в отдельной статье на нашем сайте.
All done!
Congratulations, you can now wield the mighty power of JSON for any and all of your nefarious Python needs.
While the examples you’ve worked with here are certainly contrived and overly simplistic, they illustrate a workflow you can apply to more general tasks:
- Import the package.
- Read the data with or .
- Process the data.
- Write the altered data with or .
What you do with your data once it’s been loaded into memory will depend on your use case. Generally, your goal will be gathering data from a source, extracting useful information, and passing that information along or keeping a record of it.
Today you took a journey: you captured and tamed some wild JSON, and you made it back in time for supper! As an added bonus, learning the package will make learning and a snap.








