Что такое реляционная база данных
Содержание:
- Шаг 1. Подготовка данных
- Литература
- Реляционные операции
- Особенности, структура и термины, связанные с реляционной моделью
- Ключи
- Применение по прямому назначению
- Обзор
- Контроль за реляционной базой любого размера
- Как хранится информация в БД
- Реляционная база данных
- Структура данных в реляционной модели данных
- Как ускорить работу компьютера (ноутбука) Windows 7
- Преимущества и недостатки
- Жесткие диски цены
- Модель сетевой базы данных
- MergeSort (Сортировка слиянием)
- 5 последних уроков рубрики «Разное»
Шаг 1. Подготовка данных
Для того чтобы нам было с чем работать, я набрал в твиттере запрос “#databases” и сформировал таблицу из 10 записей:
Таблица 1
| full_name | username | text | created_at | following_username |
|---|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 | Scootmedia, MetiersInternet |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 | klout, zillow |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 | DayJobDoc, byosko |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 | CindyCrawford, Arjantim |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 | MichaelDell, Yahoo |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 | MichaelDell, Yahoo |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 | RealSkipBayless, stephenasmith |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 | RealSkipBayless, stephenasmith |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 | dellock6, rohitkilam |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 | drsql, steam_games |
В первую очередь, давайте разберёмся с колонками:
- full_name: имя пользователя
- username: логин в Twitter-е
- text: текст твита
- created_at: время создания твита
- following_username: список пользователей, разделённых запятыми, которые подписались на этот твитт. Для краткости я сократил этот список до 2 имён.
Это реальные данные. Если хотите, вы можете их найти и обновить.
Хорошо. Теперь все наши данные находятся в одном месте. Даёт ли это нам возможность легко осуществить поиск по ним? Не совсем. Данная таблица далека от идеала. Во-первых, в некоторых столбцах у нас есть повторяющиеся записи: к примеру, в х “username” и “following_username”. Также колонка “following_username” нарушает правила реляционных моделей, т.к. её в ячейках присутствует более 1 значения (записи разделены запятыми).
К тому же у нас попадаются дубликаты и в строках.
Повторяющиеся данные действительно являются проблемой, т.к. они затрудняют процесс CRUD. К примеру, при поиске по данной таблице на обработку дубликатов будет уходить дополнительное время. К тому же, если пользователь обновит твитт, то нам нужно будет перезаписать все дубликаты.
Решение данной проблемы заключается в разделении Таблицы 1 на несколько таблиц. Давайте примемся за решение первой проблемы, а именно — устранение дубликатов в столбцах.
Литература
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. — ISBN 5-8459-0788-8 (рус.) 0-321-19784-4 (англ.).
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. — ISBN 5-8459-0384-X.
- C. J. Date. Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с. — ISBN 978-1-59059-746-0, 1-59059-746-X.
- Date, C. J. Database in Depth. — O’Reilly, 2005. — 240 с. — ISBN 0-596-10012-4.
Реляционные операции
Запросы к реляционной базе данных и производные реляционные переменные в базе данных выражаются в реляционном исчислении или реляционной алгебре . В своей первоначальной реляционной алгебре Кодд ввел восемь реляционных операторов в две группы по четыре оператора в каждой. Первые четыре оператора были основаны на традиционных математических операциях над множеством :
- Оператор объединения объединяет кортежи двух отношений и удаляет все повторяющиеся кортежи из результата. Оператор реляционного объединения эквивалентен оператору SQL UNION .
- Оператор пересечения создает набор кортежей, которые являются общими для двух отношений. Пересечение реализовано в SQL в виде оператора INTERSECT .
- Оператор разности воздействует на два отношения и создает набор кортежей из первого отношения, которых нет во втором отношении. Различие реализовано в SQL в виде оператора EXCEPT или MINUS.
- Декартово произведение двух отношений является объединение , которое не ограничивается каким — либо критериям, в результате чего в каждом наборе из первого соотношения, совпадающим с каждым кортежем второго соотношения. Декартово произведение реализовано в SQL как оператор перекрестного соединения .
Остальные операторы, предложенные Коддом, включают специальные операции, характерные для реляционных баз данных:
- Операция выбора или ограничения извлекает кортежи из отношения, ограничивая результаты только теми, которые соответствуют определенному критерию, то есть подмножеству с точки зрения теории множеств. SQL-эквивалентом выбора является оператор запроса SELECT с предложением WHERE .
- Операция проецирования извлекает только указанные атрибуты из кортежа или набора кортежей.
- Операция соединения, определенная для реляционных баз данных, часто называется естественным соединением. В этом типе соединения два отношения связаны своими общими атрибутами. MySQL аппроксимация естественного соединения — это оператор внутреннего соединения . В SQL INNER JOIN предотвращает появление декартова произведения, когда в запросе есть две таблицы. Для каждой таблицы, добавленной в SQL-запрос, добавляется одно дополнительное ВНУТРЕННЕЕ СОЕДИНЕНИЕ, чтобы предотвратить декартово произведение. Таким образом, для N таблиц в запросе SQL должно быть N − 1 INNER JOINS, чтобы предотвратить декартово произведение.
- Операция является немного более сложной операцией и по существу включает в себя использование кортежей одного отношения (делимого) для разделения второго отношения (делителя). Оператор реляционного деления фактически противоположен оператору декартового произведения (отсюда и название).
Другие операторы были введены или предложены после того, как Кодд представил первоначальную восьмерку, включая операторы реляционного сравнения и расширения, которые, помимо прочего, предлагают поддержку вложенности и иерархических данных.
Особенности, структура и термины, связанные с реляционной моделью
Каждый источник по-своему описывает ее элементы, поэтому для меньшей путаницы хотелось бы привести небольшую подсказку:
- реляционная табличка = сущность;
- макет = атрибуты = наименование полей = заголовок столбцов сущности;
- экземпляр сущности = кортеж = запись = строка таблички;
- значение атрибута = ячейка сущности= поле.
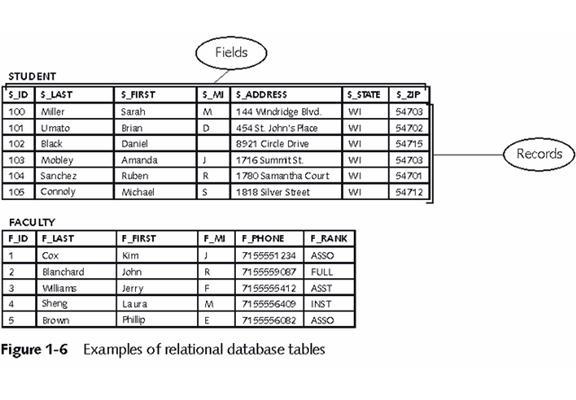
Для перехода к свойствам реляционной базы данных следует знать, из каких базовых компонентов она состоит и для чего они предназначены.
- Сущность. Таблица реляционной базы данных может быть одна, а может быть целый набор из таблиц, которые характеризируют описанные объекты благодаря хранящимся в них данным. У них фиксированное количество полей и переменное число записей. Таблица реляционной модели баз данных составляется из строк, атрибутов и макета.
- Запись – переменное число строк, отображающих данные, что характеризируют описываемый объект. Нумерация записей производится системой автоматически.
- Атрибуты — данные, демонстрирующие собой описание столбцов сущности.
- Поле. Представляет собой столбец сущности. Их количество – фиксированная величина, устанавливаемая во время создания или изменения таблицы.
Теперь, зная составляющие элементы таблицы, можно переходить к свойствам реляционной модели database:
- Сущности реляционной БД двумерные. Благодаря этому свойству с ними легко проделывать различные логические и математические операции.
- Порядок следования значений атрибутов и записей в реляционной таблице может быть произвольным.
- Столбец в пределах одной реляционной таблицы должен иметь свое индивидуальное название.
- Все данные в столбце сущности имеют фиксированную длину и одинаковый тип.
- Любая запись в сущности считается одним элементом данных.
- Составляющие компоненты строк единственны в своем роде. В реляционной сущности отсутствуют одинаковые строки.
Исходя из свойств реляционной СУБД, понятно, что значения атрибутов должны быть одинакового типа, длины. Рассмотрим особенности значений атрибутов.
Ключи
Каждая строка в таблице имеет свой уникальный ключ. Строки в таблице можно связать со строками в других таблицах, добавив столбец для уникального ключа связанной строки (такие столбцы известны как внешние ключи ). Кодд показал, что отношения данных произвольной сложности могут быть представлены простым набором концепций.
Часть этой обработки включает постоянную возможность выбрать или изменить одну и только одну строку в таблице. Таким образом, большинство физических реализаций имеют уникальный первичный ключ (PK) для каждой строки в таблице. Когда в таблицу записывается новая строка, создается новое уникальное значение для первичного ключа; это ключ, который система использует в первую очередь для доступа к таблице. Производительность системы оптимизирована для ПК. Другие, более естественные ключи также могут быть идентифицированы и определены как альтернативные ключи (AK). Часто для формирования AK требуется несколько столбцов (это одна из причин, по которой один целочисленный столбец обычно превращается в PK). И PK, и AK имеют возможность однозначно идентифицировать строку в таблице. Дополнительная технология может применяться для обеспечения уникального идентификатора во всем мире, глобального уникального идентификатора , когда есть более широкие системные требования.
Первичные ключи в базе данных используются для определения отношений между таблицами. Когда ПК переходит в другую таблицу, он становится внешним ключом в другой таблице. Когда каждая ячейка может содержать только одно значение, а PK переносится в обычную таблицу сущностей, этот шаблон проектирования может представлять отношения « один к одному» или « один ко многим» . Большинство проектов реляционных баз данных разрешают отношения « многие ко многим» путем создания дополнительной таблицы, содержащей PK из обеих других таблиц сущностей — отношение становится сущностью; затем таблица разрешения именуется соответствующим образом, и два FK объединяются, чтобы сформировать PK. Миграция PK в другие таблицы — вторая основная причина, по которой целые числа, назначенные системой, обычно используются в качестве PK; обычно нет ни эффективности, ни ясности в переносе множества других типов столбцов.
Отношения
Отношения — это логическая связь между различными таблицами, установленная на основе взаимодействия между этими таблицами.
Применение по прямому назначению
Не следует путать БД и хранилище данных. В хранилище данные накапливаются за долгий период времени, в то время как база всё время меняет их на актуальные. Из-за этого хранилища плохо подходят под автоматизированные процессы анализа.
Неизменность данных также отличительная черта хранилища. Поэтому они предназначены для более содержательного исследования информации.

Без применения БД не обойтись при создании динамичного сайта. Если на нём несколько страниц и информация на них постоянно обновляется, потребуется автоматизация управления контентом. Данные для наполнения сайта будут содержаться и браться из базы. Таким образом содержимое страницы будет автоматически формироваться для каждого пользователя индивидуально.
Написание сайта это не только построение его реляционной базы. Для создания сайта на языке php нужно знать множество нюансов. Такие особенности и примеры решения возникающих трудностей в своих видеоуроках рассказывает Михаил Русаков. Благодаря его курсам вы сможете вывести свои навыки на более профессиональный уровень. А получая новые знания, расширите круг своих возможностей.

Подписывайтесь на обновления моего блога, тут часто появляются интересные и полезные статьи. А подписавшись на мою группу Вконтакте, вы сможете получать последние обновления прямо в свою новостную ленту.
Обзор
Основная потребность в объектно-реляционной базе данных возникает из-за того, что и реляционная, и объектная база данных имеют свои индивидуальные преимущества и недостатки. Изоморфизм системы реляционных баз данных с математическим соотношением позволяет использовать многие полезные методы и теоремы из теории множеств. Но эти типы баз данных бесполезны, когда дело доходит до сложности данных и несоответствия между приложением и СУБД. Объектно-ориентированная модель базы данных позволяет использовать такие контейнеры, как наборы и списки, произвольные пользовательские типы данных, а также вложенные объекты. Это обеспечивает общность между системами типов приложений и системами типов баз данных, что устраняет любую проблему несоответствия импеданса. Но объектные базы данных, в отличие от реляционных, не предоставляют математической базы для их глубокого анализа.
Основная цель объектно-реляционной базы данных — преодолеть разрыв между реляционными базами данных и методами объектно-ориентированного моделирования, используемыми в таких языках программирования, как Java , C ++ , Visual Basic .NET или C # . Однако более популярной альтернативой для достижения такого моста является использование стандартных систем реляционных баз данных с некоторой формой программного обеспечения объектно-реляционного сопоставления (ORM). В то время как традиционные СУБД или СУБД SQL ориентированы на эффективное управление данными, полученными из ограниченного набора типов данных (определенных соответствующими языковыми стандартами), объектно-реляционные СУБД позволяют разработчикам программного обеспечения интегрировать свои собственные типы и методы, которые применить к ним в СУБД.
ORDBMS (например, ODBMS или OODBMS ) интегрирована с объектно-ориентированным языком программирования . Характерные свойства ORDBMS: 1) сложные данные, 2) наследование типов и 3) поведение объекта. Создание сложных данных в большинстве СУБД SQL основано на предварительном определении схемы через определяемый пользователем тип (UDT). Иерархия в структурированных сложных данных предлагает дополнительное свойство — наследование типов . То есть структурированный тип может иметь подтипы, которые повторно используют все его атрибуты и содержат дополнительные атрибуты, специфичные для этого подтипа. Другое преимущество — поведение объекта — связано с доступом к программным объектам. Такие программные объекты должны быть сохраняемыми и переносными для обработки базы данных, поэтому они обычно называются постоянными объектами . Внутри базы данных все отношения с постоянным программным объектом являются отношениями с его идентификатором объекта (OID) . Все эти моменты можно решить в соответствующей реляционной системе, хотя стандарт SQL и его реализации налагают произвольные ограничения и дополнительную сложность.
В объектно-ориентированном программировании (ООП) поведение объекта описывается с помощью методов (объектных функций). Методы, обозначенные одним именем, различаются по типу их параметров и типу объектов, к которым они прикреплены ( сигнатура метода ). В языках ООП это называется принципом полиморфизма , который кратко определяется как «один интерфейс, множество реализаций». Другие принципы ООП, наследование и инкапсуляция , связаны как с методами, так и с атрибутами. Наследование методов включено в наследование типов. Инкапсуляция в ООП является степень видимости объявлена, например, через , и модификаторы доступа .
Контроль за реляционной базой любого размера
Для работы с базой данных используется специальный софт — системы управления базами данных — СУБД. Он облегчает работу с крупными базами и ускоряет процесс их настройки. Для СУБД был создан специальный язык структурированных запросов. Эти запросы содержат координаты расположения информации — названия строк и столбцов, их типы. Чем компактнее будет сформулирован запрос, тем быстрее отыщется информация.

Чтобы лучше представить себе БД реляционного типа, сравните её с чем-нибудь уже знакомым. Таблицы в excel — наглядный аналог таблицы в реляционной базе. Даже небольшой навык работы в этой программе позволит лучше представить принцип работы БД. Здесь ячейки заполняются вручную, зато визуально видна их структура.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Реляционная база данных
Реляционная база данных наиболее интересна для понимания теории баз данных. Причина в этом одна. Будучи, аналогом таблиц, реляционная БД лучше других типов баз данных проработана математически. А значит, можно математическим языком объяснить устройство реляционной базы данных и процессы, происходящие в ней.
Устройство реляционной базы данных (РБД) базируется на основном элементе, таблице. Есть ошибочное мнение, что реляционная БД это и есть таблица. На самом деле таблица это всего лишь визуальное или лучше сказать, внешнее отражение РБД, на экране или принтере. На экране мы видим не все данные, а только фильтрованные (отобранные) данные. Пора разобраться с устройством реляционной (табличной) базы данных.
Структура данных в реляционной модели данных
Реляционная модель данных предусматривает структуру данных, обязательными объектами
которой являются:
отношение;
атрибут;
домен;
кортеж;
степень;
кардинальность;
первичный ключ.
Отношение — это плоская (двумерная) таблица, состоящая из столбцов и строк:
| ID | Фамилия | Имя | Должность | г.р. |
| 1 | Петров | Игорь | Директор | 1968 |
| 2 | Иванов | Олег | Юрист | 1973 |
| 3 | Ким | Елена | Бухгалтер | 1980 |
| 4 | Сенин | Илья | Менеджер | 1981 |
| 5 | Васин | Сергей | Менеджер | 1978 |
Атрибут — это поименованный столбец отношения.
Домен — это набор допустимых значений для одного или нескольких атрибутов.
Кортеж — это строка отношения.
Степень определяется количеством атрибутов, которое оно содержит
Кардинальность — это количество кортежей, которое содержит отношение.
Первичный ключ — это уникальный идентификатор для таблицы.
Соответствие между формальными терминами реляционной модели данных и неформальными:
- отношение (формальный термин) — таблица (неформальный термин);
- атрибут — столбец;
- кортеж — строка или запись;
- степень — количество столбцов;
- кардинальное число — количество строк;
- первичный ключ — уникальный идентификатор;
- домен — общая совокупность допустимых значений.
Как ускорить работу компьютера (ноутбука) Windows 7
Преимущества и недостатки
Надлежащие системы управления базами данных помогают получить лучший доступ к данным, а также оптимизировать управление ими. В свою очередь, точечный доступ помогает конечным пользователям быстро и эффективно обмениваться данными в рамках выполнения задач организации.
|
Модель базы данных |
Год создания |
Преимущества |
Недостатки |
|
Иерархическая |
1960-й |
Очень быстрый доступ для чтения, четкая структура, технически простой. |
Исправлена структура в дереве, которая не допускает связи между деревьями. |
|
Сетевая |
Начало 1970-х |
Поддерживает несколько способов доступа к записи, без строгой иерархии. |
Плохой обзор с большими базами данных. |
|
Реляционная |
1970-й |
Простое, гибкое создание и редактирование, легко расширяемое, быстрый ввод в эксплуатацию, простое расширение, быстрый запуск, очень динамичный контекст. |
Неуправляемый с большими объемами данных, плохой сегментацией, атрибутами искусственного ключа, внешним интерфейсом программирования, плохо отражает свойства и поведение объектов. |
|
Ориентирована на объекты |
Конец 1980-х |
Лучшая поддержка объектноориентированных языков программирования, хранение мультимедийного контента. Поддерживает объектноориентированные языки программирования, позволяет хранить мультимедийный контент. |
Более низкая производительность с большими объемами данных, мало совместимых интерфейсов. |
|
Ориентирована на документы |
1980-е |
Соответствующие данные хранятся централизованно в независимых документах, свободной структуре, концепции мультимедиа, относится к классификации сущностей БД. |
Организационная работа относительно высока, часто требует навыков программирования. |
Жесткие диски цены
Модель сетевой базы данных
Эта БД разрешает записи иметь множество родительских и дочерних форматов, способных визуализировать их в виде сетевой структуры. Напротив, в иерархической элемент реляционной СУБД имеет ряд дочерних и одну родительскую. На самом деле сетевая модель очень похожа на иерархическую, являясь ее подмножеством. Однако вместо использования одного родителя в сетевой модели используется теория множеств, обеспечивающая древовидную иерархию. Исключением является то, что дочерним таблицам можно иметь более одного родителя.
Преимущества сетевой БД:
- Концептуально проста и легка в разработке.
- Доступ к данным проще и гибче по отношению к иерархической модели и не позволяет члену существовать без родителя.
- Может обрабатывать сложные данные из-за своего отношения «многие ко многим». Это позволяет более естественное моделирование отношений между записями или объектами реляционной СУБД в отличие от иерархической.
- Благодаря своей гибкости легче перемещается и находит информацию в сетевой БД.
- Такая структура изолирует управляющие программы от сложных физических данных.
MergeSort (Сортировка слиянием)
Что вы делаете, когда вам нужно отсортировать коллекцию? Что? Вы вызываете функцию sort ()… Ок, хороший ответ… Но для базы данных вы должны понимать, как работает эта функция sort ().
Существует несколько хороших алгоритмов сортировки, поэтому я остановлюсь на самом важном: сортировке слиянием. Возможно, вы сейчас не понимаете, почему сортировка данных полезна, но вы должны будете понять, после части посвященной оптимизации запросов
Более того, понимание сортировки слиянием поможет нам позже понять общую операцию join баз данных, называемую merge join (объединение слиянием).
Merge (слияние)
Как и многие полезные алгоритмы, сортировка слиянием основана на хитрости: объединение 2 отсортированных массивов размера N / 2 в N-элементный отсортированный массив стоит всего N операций. Эта операция называется слиянием.
Давайте посмотрим, что это значит на простом примере:
На этом рисунке видно, что для построения окончательного отсортированного массива из 8 элементов вам нужно всего лишь выполнить итерацию один раз в 2х 4-элементных массивах. Поскольку оба 4-элементных массива уже отсортированы:
- 1) вы сравниваете оба текущих элемента в двух массивах (в начале текущий = первому)
- 2) затем возьмите наименьший, чтобы поместить его в массив из 8 элементов
- 3) и переходите к следующему элементу в массиве, где вы взяли самый маленький элемент
- и повторяйте 1,2,3, пока не дойдете до последнего элемента одного из массивов.
- Затем вы берете остальные элементы другого массива, чтобы поместить их в массив из 8 элементов.
Это работает, потому что оба 4-элементных массива отсортированы, и поэтому вам не нужно «возвращаться» в этих массивах.
Теперь, когда мы поняли этот трюк, вот мой псевдокод для merge:
Сортировка слиянием разбивает задачу на меньшие задачи, а затем находит результаты меньших задач, чтобы получить результат исходной задачи (примечание: этот вид алгоритмов называется разделяй и властвуй). Если вы не понимаете этот алгоритм, не волнуйтесь; я не понял этого в первый раз, когда увидел. Если это может помочь вам, я вижу этот алгоритм как двухфазный алгоритм:
- Фаза деления, где массив делится на меньшие массивы
- Фаза сортировки, где маленькие массивы объединяются (используя объединение), чтобы сформировать больший массив.
Division phase (фаза деления)
На этапе деления массив делится на унитарные массивы за 3 шага. Формальное количество шагов — log(N) (поскольку N=8, log(N) = 3).
Откуда я это знаю?
Я гений! Одним словом — математика. Идея состоит в том, что каждый шаг делит размер исходного массива на 2. Количество шагов — это количество раз, которое вы можете разделить исходный массив на два. Это точное определение логарифма (с основанием 2).
Sorting phase (Фаза сортировки)
На этапе сортировки вы начинаете с унитарных (одноэлементных) массивов. В течение каждого этапа вы применяете несколько операций слияния, и общая стоимость составляет N = 8 операций:
- На первом этапе у вас есть 4 слияния, которые стоят 2 операции каждый
- На втором шаге у вас есть 2 слияния, которые стоят 4 операции каждый
- На третьем шаге у вас есть 1 слияние, которое стоит 8 операций
Поскольку существует log (N) шагов, общая стоимость N * log(N) операций.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.








