Обзор средств sqlsql tools overview
Содержание:
- Совместимость
- Процедурные расширения
- JOIN-соединения – операции горизонтального соединения данных
- Выражение CASE – условный оператор языка SQL
- Команды языка определения данных
- Выполнение запросов
- Операции записи
- Работа в сервисе sql fiddle
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Булевы операторы и простые операторы сравнения
- PowerShell и SQL Server
- Ресурсы SQL Server
- История
- Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
- SELECT – оператор выборки данных
- Как ускорить работу компьютера (ноутбука) Windows 7
- Уровни работы с данными
- Примеры:Examples:
- В.C. Совместное использование DISTINCT и SELECTUsing DISTINCT with SELECT
- Г.D. Использование GROUP BYUsing GROUP BY
- Д.E. Использование GROUP BY с несколькими группамиUsing GROUP BY with multiple groups
- Е.F. Использование GROUP BY и WHEREUsing GROUP BY and WHERE
- Ж.G. Использование GROUP BY с выражениемUsing GROUP BY with an expression
- З.H. Использование GROUP BY с ORDER BYUsing GROUP BY with ORDER BY
- И.I. Использование предложения HAVINGUsing the HAVING clause
- SQL syntax used
Совместимость
Команда соответствует стандарту SQL, с описанными ниже исключениями.
Временные таблицы
Хотя синтаксис подобен аналогичному в стандарте SQL, результат получается другим. В стандарте временные таблицы определяются только один раз и существуют (изначально пустые) в каждом сеансе, в котором они используются. PostgreSQL вместо этого требует, чтобы каждый сеанс выполнял собственную команду для каждой временной таблицы, которая будет использоваться. Это позволяет использовать в разных сеансах таблицы с одинаковыми именами для разных целей, тогда как при подходе, регламентированном стандартом, все экземпляры временной таблицы с одним именем должны иметь одинаковую табличную структуру.
Поведение временных таблиц, описанное в стандарте, в большинстве своём игнорируют и другие СУБД, так что в этом отношении PostgreSQL ведёт себя так же, как и ряд других СУБД.
В стандарте SQL также разделяются глобальные и локальные временные таблицы — в локальной временной таблице содержится отдельный набор данных для каждого модуля SQL в отдельном сеансе, хотя её определение так же разделяется между ними. Так как в PostgreSQL модули SQL не поддерживаются, это различие в PostgreSQL не существует.
Совместимости ради, PostgreSQL принимает ключевые слова и в объявлении временной таблицы, но в настоящее время они никак не действуют. Использовать их не рекомендуется, так как в будущих версиях PostgreSQL может быть принята их интерпретация, более близкая к стандарту.
Предложение для временных таблиц тоже подобно описанному в стандарте SQL, но есть некоторые отличия. Если предложение опущено, в SQL подразумевается поведение . Однако в PostgreSQL по умолчанию действует . Параметр в стандарте SQL отсутствует.
Неотложенные ограничения уникальности
Когда ограничение или не является отложенным, PostgreSQL проверяет уникальность непосредственно в момент добавления или изменения строки. Стандарт SQL говорит, что уникальность должна обеспечиваться только в конце оператора; это различие проявляется, например когда одна команда изменяет множество ключевых значений. Чтобы получить поведение, оговоренное стандартом, объявите ограничение как откладываемое (), но не отложенное (т. е., ). Учтите, что этот вариант может быть значительно медленнее, чем немедленная проверка ограничений.
Ограничения-проверки для столбцов
Стандарт SQL говорит, что ограничение , определяемое для столбца, может ссылаться только на столбец, с которым оно связано; только ограничения для таблиц могут ссылаться на несколько столбцов. В PostgreSQL этого ограничения нет; он воспринимает ограничения-проверки для столбцов и таблиц одинаково.
«Ограничение» (на самом деле это не ограничение) является расширением PostgreSQL стандарта SQL, которое реализовано для совместимости с некоторыми другими СУБД (и для симметрии с ограничением ). Так как это поведение по умолчанию для любого столбца, его присутствие не несёт смысловой нагрузки.
Наследование
Множественное наследование посредством является языковым расширением PostgreSQL. SQL:1999 и более поздние стандарты определяют единичное наследование с другим синтаксисом и смыслом. Наследование в стиле SQL:1999 пока ещё не поддерживается в PostgreSQL.
Таблицы с нулём столбцов
PostgreSQL позволяет создать таблицу без столбцов (например, ). Это расширение стандарта SQL, который не допускает таблицы с нулём столбцов. Таблицы с нулём столбцов сами по себе не очень полезны, но если их запретить, возникают странные особые ситуации с командой , так что лучшим вариантом кажется игнорировать это требование стандарта.
Хотя предложение описано в стандарте SQL, многие варианты его использования, допустимые в PostgreSQL, в стандарте не описаны, а некоторые предусмотренные в стандарте возможности не реализованы в PostgreSQL.
Табличные пространства
Концепция табличных пространств в PostgreSQL отсутствует в стандарте. Как следствие, предложения и являются расширениями.
Процедурные расширения
SQL разработан для конкретной цели: запрашивать данные, содержащиеся в реляционной базе данных . SQL — это декларативный язык программирования на основе наборов , а не императивный язык программирования, такой как C или BASIC . Однако расширения к стандартному SQL добавляют функциональные возможности процедурного языка программирования , такие как конструкции управления потоком. Они включают:
| Источник | Сокращенное название | ФИО |
|---|---|---|
| Стандарт ANSI / ISO | SQL / PSM | Модули SQL / Persistent Stored |
| Interbase / Firebird | PSQL | Процедурный SQL |
| IBM DB2 | SQL PL | Процедурный язык SQL (реализует SQL / PSM) |
| IBM Informix | SPL | Сохраненный процедурный язык |
| IBM Netezza | NZPLSQL | (на основе Postgres PL / pgSQL) |
| Изобретательный | PSQL | Invantive Procedural SQL (реализует SQL / PSM и PL / SQL ) |
| MariaDB | SQL / PSM , PL / SQL | SQL / Persistent Stored Module (реализует SQL / PSM), процедурный язык / SQL (на основе Ada ) |
| Microsoft / Sybase | T-SQL | Transact-SQL |
| Mimer SQL | SQL / PSM | SQL / Persistent Stored Module (реализует SQL / PSM) |
| MySQL | SQL / PSM | SQL / Persistent Stored Module (реализует SQL / PSM) |
| MonetDB | SQL / PSM | SQL / Persistent Stored Module (реализует SQL / PSM) |
| NuoDB | SSP | Хранимые процедуры Старки |
| Oracle | PL / SQL | Процедурный язык / SQL (на основе Ada ) |
| PostgreSQL | PL / pgSQL | Процедурный язык / язык структурированных запросов PostgreSQL (на основе сокращенного PL / SQL ) |
| SAP R / 3 | ABAP | Расширенное программирование бизнес-приложений |
| SAP HANA | SQLScript | SQLScript |
| Sybase | Watcom-SQL | SQL Anywhere Watcom-SQL Диалект |
| Терадата | SPL | Сохраненный процедурный язык |
В дополнение к стандартным расширениям SQL / PSM и проприетарным расширениям SQL на многих платформах SQL доступно процедурное и объектно-ориентированное программирование через интеграцию СУБД с другими языками. Стандарт SQL определяет расширения SQL / JRT (процедуры и типы SQL для языка программирования Java) для поддержки кода Java в базах данных SQL. Microsoft SQL Server 2005 использует SQLCLR (общеязыковая среда выполнения SQL Server) для размещения управляемых сборок .NET в базе данных, в то время как предыдущие версии SQL Server были ограничены неуправляемыми расширенными хранимыми процедурами, в основном написанными на C. PostgreSQL позволяет пользователям писать функции в широком диапазоне. множество языков, включая Perl , Python , Tcl , JavaScript (PL / V8) и C.
JOIN-соединения – операции горизонтального соединения данных
Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
- JOIN – левая_таблица JOIN правая_таблица ON условия_соединения
- LEFT JOIN – левая_таблица LEFT JOIN правая_таблица ON условия_соединения
- RIGHT JOIN – левая_таблица RIGHT JOIN правая_таблица ON условия_соединения
- FULL JOIN – левая_таблица FULL JOIN правая_таблица ON условия_соединения
- CROSS JOIN – левая_таблица CROSS JOIN правая_таблица
| Краткий синтаксис | Полный синтаксис | Описание (Это не всегда всем сразу понятно. Так что, если не понятно, то просто вернитесь сюда после рассмотрения примеров.) |
|---|---|---|
| JOIN | INNER JOIN | Из строк левой_таблицы и правой_таблицы объединяются и возвращаются только те строки, по которым выполняются условия_соединения. |
| LEFT JOIN | LEFT OUTER JOIN | Возвращаются все строки левой_таблицы (ключевое слово LEFT). Данными правой_таблицы дополняются только те строки левой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк правой_таблицы вставляются NULL-значения. |
| RIGHT JOIN | RIGHT OUTER JOIN | Возвращаются все строки правой_таблицы (ключевое слово RIGHT). Данными левой_таблицы дополняются только те строки правой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк левой_таблицы вставляются NULL-значения. |
| FULL JOIN | FULL OUTER JOIN | Возвращаются все строки левой_таблицы и правой_таблицы. Если для строк левой_таблицы и правой_таблицы выполняются условия_соединения, то они объединяются в одну строку. Для строк, для которых не выполняются условия_соединения, NULL-значения вставляются на место левой_таблицы, либо на место правой_таблицы, в зависимости от того данных какой таблицы в строке не имеется. |
| CROSS JOIN | — | Объединение каждой строки левой_таблицы со всеми строками правой_таблицы. Этот вид соединения иногда называют декартовым произведением. |
- Это короче и не засоряет запрос лишними словами;
- По словам LEFT, RIGHT, FULL и CROSS и так понятно о каком соединении идет речь, так же и в случае просто JOIN;
- Считаю слова INNER и OUTER в данном случае ненужными рудиментами, которые больше путают начинающих.
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
Выражение CASE – условный оператор языка SQL
| Первая форма: | Вторая форма: |
|---|---|
| CASE WHEN условие_1 THEN возвращаемое_значение_1 … WHEN условие_N THEN возвращаемое_значение_N END |
CASE проверяемое_значение WHEN сравниваемое_значение_1 THEN возвращаемое_значение_1 … WHEN сравниваемое_значение_N THEN возвращаемое_значение_N END |
Разберем на примере первую форму CASE:
| ID | Name | Salary | SalaryTypeWithELSE | SalaryTypeWithoutELSE |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | ЗП >= 3000 | ЗП >= 3000 |
| 1001 | Петров П.П. | 1500 | ЗП < 2000 | NULL |
| 1002 | Сидоров С.С. | 2500 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1003 | Андреев А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1004 | Николаев Н.Н. | 1500 | ЗП < 2000 | NULL |
| 1005 | Александров А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
Разберем на примере вторую форму CASE:
- Сотрудникам ИТ-отдела выдать по 15% от ЗП;
- Сотрудникам Бухгалтерии по 10% от ЗП;
- Всем остальным по 5% от ЗП.
| ID | Name | Salary | DepartmentID | NewYearBonusPercent | BonusAmount |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 250 |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 225 |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 250 |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 300 |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 225 |
| 1005 | Александров А.А. | 2000 | NULL | 5% | 100 |
- Первым делом ЗП должны получить сотрудники у кого оклад меньше 2500
- Те сотрудники у кого оклад больше или равен 2500, получают ЗП во вторую очередь
- Внутри этих двух групп нужно упорядочить строки по ФИО (поле Name)
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1000 | Иванов И.И. | 5000 |
| 1002 | Сидоров С.С. | 2500 |
| ID | Name | Salary | DepartmentID | NewYearBonusPercent1 | NewYearBonusPercent2 |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 5% |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 15% |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 10% |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 15% |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 15% |
| 1005 | Александров А.А. | 2000 | NULL | — | 5% |
Команды языка определения данных
Команды языка определения данных DDL (Data Definition Language, язык определения данных) — это подмножество SQL, используемое для определения и модификации различных структур данных.
К данной группе относятся команды предназначенные для создания, изменения и удаления различных объектов базы данных. Команды CREATE (создание), ALTER (модификация) и DROP (удаление) имеют большинство типов объектов баз данных (таблиц, представлений, процедур, триггеров, табличных областей, пользователей и др.). Т.е. существует множество команд DDL, например, CREATE TABLE, CREATE VIEW, CREATE PROCEDURE, CREATE TRIGGER, CREATE USER, CREATE ROLE и т.д.
Некоторым кажется, что применение DDL является прерогативой администраторов базы данных, а операторы DML должны писать разработчики, но эти два языка не так-то просто разделить. Сложно организовать аффективный доступ к данным и их обработку, не понимая, какие структуры доступны и как они связаны. Также сложно проектировать соответствующие структуры, не зная, как они будут обрабатываться.
Выполнение запросов
По умолчанию, если вы не устанавливали дополнительные программы, у MySQL нет графического интерфейса пользователя. Это значит, что единственный способ работы с ней — это использование командной строки.
- Откройте командную строку (Выполнить: cmd.exe).
- Перейдите в каталог с установленной MySQL: .
- Выполните: .
- Введите пароль, заданный при установке.
Если вы всё выполнили верно, то в командной строке запустится клиент для работы с MySQL (вы поймете это по строке приглашения «mysql>»). С этого момента можно вводить любые SQL запросы, но каждый запрос обязательно должен заканчиваться точкой с запятой
Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок ‘ом, мы задаем знаения ‘ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
делает то же самое, что раньше: выбирает строки. Вместо , который использовался при чтении, мы теперь используем . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос это просто запрос или без названий колонок. Серьезно. Как и в случае с и , блок остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это . Формат такой:
Где , , это названия колонок, а , и это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с , который заполняет всю таблицу «books»:
Работа в сервисе sql fiddle
Онлайн проверка sql запросов возможна при помощи сервиса sqlFiddle.
Самый простой способ организации работы состоит из следующих этапов:
- В верхней части рабочей области сервиса выбираем язык: SQLite(WebSQL);
Открывшаяся рабочая область разделена визуально на 3 окна: левое — для кода создания таблиц и заполнения их данными, правое — для кода запросов, нижнее — для отображения результатов запросов. - В левое окно помещается код для создания таблиц и вставки в них данных (пример кода расположен ниже). Затем щелкается кнопка «Build Schema».
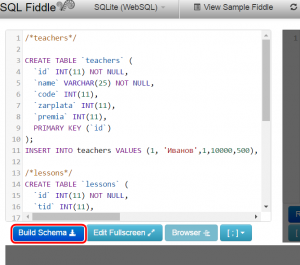
После того как схема построена (об этом сигнализирует надпись на зеленом фоне «Schema Ready»), в правое окошко вставляется код запроса и щелкается кнопка Run SQL.
Еще пример: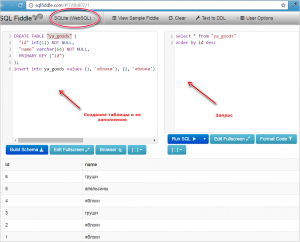
Теперь некоторые пункты рассмотрим подробнее.Создание таблиц:
Пример: создайте сразу три таблицы (teachers, lessons и courses); добавьте по нескольку значений в каждую таблицу.
* для тех, кто незнаком с синтаксисом — просто скопировать полностью код и вставить в левое окошко сервиса
* урок по созданию таблиц в языке SQL далее
/*teachers*/ CREATE TABLE `teachers` ( `id` INT(11) NOT NULL, `name` VARCHAR(25) NOT NULL, `code` INT(11), `zarplata` INT(11), `premia` INT(11), PRIMARY KEY (`id`) ); INSERT INTO teachers VALUES (1, 'Иванов',1,10000,500), (2, 'Петров',1,15000,1000) ,(3, 'Сидоров',1,14000,800), (4,'Боброва',1,11000,800); /*lessons*/ CREATE TABLE `lessons` ( `id` INT(11) NOT NULL, `tid` INT(11), `course` VARCHAR(25), `date` VARCHAR(25), PRIMARY KEY (`id`) ); INSERT INTO lessons VALUES (1,1, 'php','2015-05-04'), (2,1, 'xml','2016-13-12'); /*courses*/ CREATE TABLE `courses` ( `id` INT(11) NOT NULL, `tid` INT(11), `title` VARCHAR(25), `length` INT(11), PRIMARY KEY (`id`) ); INSERT INTO courses VALUES (1,1, 'php',54), (2,1, 'xml',72), (3,2, 'sql',25); |
В результате получим таблицы с данными:
Отправка запроса:
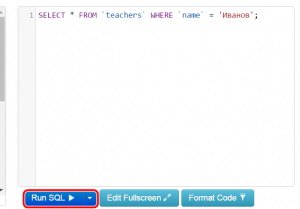
Для того чтобы протестировать работоспособность сервиса, добавьте в правое окошко код запроса.
Пример: при помощи запроса выберите все данные из таблицы teachers, касаемые учителя с фамилией Иванов
SELECT * FROM `teachers` WHERE `name` = 'Иванов'; |
На дальнейших уроках SQL будет использоваться та же схема, поэтому необходимо будет просто копировать схему и вставлять в левое окно сервиса.
Онлайн визуализации схемы базы данных
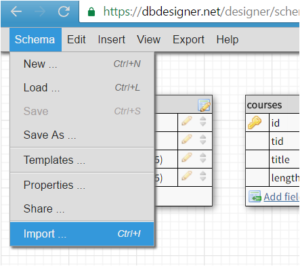
Для онлайн визуализации схемы базы данных можно воспользоваться сервисом https://dbdesigner.net/:
- Создать свой аккаунт (войти в него, если уже есть).
- Щелкнуть по кнопке Go to Application.
- Меню Schema -> Import.
- Скопировать и вставить в появившееся окно код создания и заполнения таблиц базы данных
Далее к уроку 0 Язык sql создание таблиц
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Булевы операторы и простые операторы сравнения
| AND | логическое И. Ставится между двумя условиями (условие1 AND условие2). Чтобы выражение вернуло True, нужно, чтобы истинными были оба условия |
|---|---|
| OR | логическое ИЛИ. Ставится между двумя условиями (условие1 OR условие2). Чтобы выражение вернуло True, достаточно, чтобы истинным было только одно условие |
| NOT | инвертирует условие/логическое_выражение. Накладывается на другое выражение (NOT логическое_выражение) и возвращает True, если логическое_выражение = False и возвращает False, если логическое_выражение = True |
| Условие | Значение |
|---|---|
| = | Равно |
| < | Меньше |
| > | Больше |
| <= | Меньше или равно |
| >= | Больше или равно |
| <> != |
Не равно |
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
PowerShell и SQL Server
- SQL Server & Windows Documentation Using Windows PowerShell (by Kendal Vandyke)
- TSQL Code Smells Finder (by Dave Ballantyne)
- Stairway to SQL PowerShell (by Ben Miller)
- SQL Server Health Check Script with Powershell (by Atul Kapoor)
- Universal SQL Server Installation Scripts (by Prakash Heda)
- Powershell SQL Server Performance Health Check (by Omid Afzalalghom)
- Performance Analysis of Logs (PAL) Tool (by svenhau and mikelag)
- PSCI — Powershell Continuous Integration (by Objectivity Bespoke Software Specialists)
- SQLTranscriptase — SQL Server Documentation in Powershell (by Vijay Bandi)
- SQL Server PowerShell Extensions (SQLPSX) (by Mike Shepard)
- PowerShell dbatools for SQL Server (by Chrissy LeMaire)
- Create a Monitoring Server for SQL Server with PowerShell (by Laerte Junior)
- PowerShell SQLPass articles and video
- PowerShell Blog NetNerds
- QS Config (by Derik Hammer)
- Idera 89 Free SQL Server PowerShell Scripts
- Performance Analysis of Logs (PAL) Tool (by Clint Huffman)
- Powershell SQL Server Library (PSSQLLib) (by Sander Stad)
Ресурсы SQL Server
- Блоги
- SQL Central Blog Scripts
- SQL Central Blog Articles
- SQL Central Blog Stairways
- MSSQLTips
- BRENT OZAR scripts, videos and articles
- Simple-talk Articles
- SQLSentry Blog
- Glenn Berry’s SQL Server Performance
- Kenneth Fisher SQLStudies Blog
- Best SQL Server Perfomance Blog
- Weblogs SQLTeam Blogs
- SQLMag
- SQLShack
- SQLPass
- Vertabelo Blog
- Midnightdba Blog
- Madeiradata Blog
- SQL Server Performance Articles
- SQL and more with KRUTI Blog
- SQL Authority
- TECHNET SQL Server Blog
- SQL Server Database Engine Blog
- SQL Server BI Blog
- Andy Yun SQLBeck Blog
- Curated SQL
- Blog do Ezequiel
- SQLHA Blog
- SQLSecurity Blog
- SQL.ru SQL Server (Русский)
- Безопасность (огромное спасибо Troy Hunt)
- SQL injection
- sqlmap – Инструмент для мониторинга SQL injection тестовых атак для работающего сайта
- Drupal 7 SQL injection flaw of 2014
- Ethical Hacking: SQL Injection – Подробрный курс по SQL Injection (Платно)
- Exploit databases and breach coverage
- seclists.org – Подборка уязвимостей с разных ресурсов
- Exploit Database – Солидная подборка уязвимостей баз данных
- PunkSPIDER – Большой список уязвимостей всех типов для веб ресурсов
- Data Loss DB – Хороший список уязвимостей для баз данных
- Information is Beautiful: World’s Biggest Data Breaches – Интересная географическая визуализация произошедших уязвимостей
- SQL injection
- Бесплатные видео
- IDERA Resource Center
- MSSQLTips SQL Server Webcasts and Videos
- SQL Server Videos
- TECHNET How do I Videos
- Veeam Learn Microsoft SQL Server
- MidnightDBA ITBookWorm Video
- SQL Server Hangouts (by Boris Hristov, Cathrine Wilhelmsen)
- Youtube russianVC (Русский)
- Бесплатные подкасты (на английском)
- SQL Server Radio (by Guy Glantser and Matan Yungman)
- SQL Data Partners (by Carlos L Chacon, César Oviedo and Adrian Miranda)
- Away from the Keyboard (by Cecil Phillip and Richie Rump)
- RunAs Radio (by Richard Campbell and Greg Hughes)
- People Talking Tech (by Denny Cherry)
- NET Rocks! (by Richard Campbell and Carl Franklin)
- SQL Down Under Podcast (by Greg Low)
- Free sql server video tutorials for beginners (by PRAGIM Technologies)
- Курсы
- Бесплатные
- Codecademy Learn SQL (Бесплатно)
- Codecademy SQL: Table Transformation (Бесплатно)
- Codecademy SQL: Analyzing Business Metrics (Бесплатно)
- MVA SQL Server Courses (Бесплатно)
- Платные
- Lynda Courses (Платно)
- Veeam Free Courses (Платно)
- SQLSkills Trainings (Платно)
- Brent Ozar Team Trainings (Платно)
- Pluralsight Courses (Платно)
- Бесплатные
- Обратная Совместимость
- 2016 Backwards Compatibility
- 2014 Backwards Compatibility
- 2012 Backwards Compatibility
- 2008 R2 Backwards Compatibility
- 2008 Backwards Compatibility
- 2005 Backwards Compatibility
- Другое
- SQL Server Management Studio
- Лучшее решение для бэкапов и управления индексами Ola Maintenance Solution
- SQL Server First Responder Kit
- SQL# CLR functions (by Sql Quantum Leap)
- SSIS Performance Benchmarks
- Statistic Parser (by Richie Rump)
- Using Excel to parse Set Statistics IO output (by Vicky Harp)
- SQL Generator (by Richie Rump)
- Columnstore Indexes Scripts Library (by Niko Neugebauer)
- Stackoverflow SQL Server
- DBA Stackexchange SQL Server
- BIMLScript Learn resource
- SQL Server Connection Strings
- SQL Injection Cheat Sheet (by Ferruh Mavituna)
- RSS Most Recent SQL Server KBs
- Stackoverflow SQL Anti Patterns
- SQL Server Latch Classes Library (by Paul S. Randal)
- Azure Speed (by Blair Chen)
- SQLFiddle
- Practical skills of SQL language (Русский)
История
SQL был первоначально разработан в IBM по Дональд Д. Чемберлин и Рэймонд Бойс , узнав о реляционной модели от Кодд в начале 1970 — х годов. Эта версия, первоначально называвшаяся SEQUEL ( Structured English Query Language ), была разработана для управления и извлечения данных, хранящихся в оригинальной квазиреляционной системе управления базами данных IBM , System R , которую группа из исследовательской лаборатории IBM в Сан-Хосе разработала в 1970-х .
Первой попыткой Чемберлина и Бойса создать язык реляционных баз данных был Square, но его было трудно использовать из-за обозначения индекса. После перехода в исследовательскую лабораторию Сан-Хосе в 1973 году они начали работу над SEQUEL. Акроним SEQUEL было изменено на SQL , потому что «ПРОДОЛЖЕНИЕ» был торговой маркой в британской Hawker Siddeley компании Dynamics Engineering Limited.
После тестирования SQL на тестовых сайтах заказчиков для определения полезности и практичности системы IBM начала разрабатывать коммерческие продукты на основе своего прототипа System R, включая System / 38 , SQL / DS и DB2 , которые были коммерчески доступны в 1979, 1981 и 1983 г. соответственно.
В конце 1970 — х годов, Relational Software, Inc. (теперь Oracle Corporation ) увидел потенциал концепций , описанных Коддом, Чемберлин и Бойс и разработали свои собственные SQL на основе СУБД с устремлениями его продажи в ВМС США , Центрального разведывательного управления Agency и другие правительственные агентства США . В июне 1979 года компания Relational Software, Inc. представила первую коммерчески доступную реализацию SQL, Oracle V2 (Version2) для компьютеров VAX .
К 1986 году группы стандартов ANSI и ISO официально приняли стандартное определение языка «Database Language SQL». Новые версии стандарта были опубликованы в 1989, 1992, 1996, 1999, 2003, 2006, 2008, 2011 и, совсем недавно, в 2016 году.
Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
SELECT – оператор выборки данных
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | ManagerID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 | NULL |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 | 1003 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 | 1000 |
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 | 1000 |
| (No column name) | (No column name) | (No column name) |
|---|---|---|
| 825 | 2015-04-11 12:12:36.0406743 | 1 |
- Целое / Целое = Целое (т.е. в данном случае происходит целочисленное деление)
- Вещественное / Целое = Вещественное
- Целое / Вещественное = Вещественное
| ID | (No column name) | (No column name) | (No column name) | (No column name) |
|---|---|---|---|---|
| 1000 | 10 | 10 | 10 | 10.000000 |
| 1001 | 10 | 10.01 | 10.01 | 10.010000 |
| 1002 | 10 | 10.02 | 10.02 | 10.020000 |
| 1003 | 10 | 10.03 | 10.03 | 10.030000 |
| ID | Name |
|---|---|
| 1003 | Андреев А.А. |
| 1000 | Иванов И.И. |
| 1001 | Петров П.П. |
| 1002 | Сидоров С.С. |
Как ускорить работу компьютера (ноутбука) Windows 7
Уровни работы с данными
- Слой доступа к данным, который удобно использовать из языков программирования;
- Слой хранения. Это отдельный слой, потому что обычно хранить данные удобно другими способами, чем использовать: эффективно по памяти, выравнивать, складывать на диск. Это к вопросу о schemaless: схема, которая удобна для хранения, не удобна для доступа.
- «Железо» — слой, где лежат данные, причем там они организованы еще третьим способом, потому что дисками управляет операционная система, и общаются они только через драйвер. В этот уровень мы не будем сильно вникать.
Для слоя доступатребования
- Универсальность, чтобы возможно было с помощью любой технологии запрашивать данные.
- Оптимальность этого запроса. Метод доступа должен быть такой, чтобы хорошо и удобно доставать данные из базы.
- Параллелизм, потому что сейчас все масштабируются, разные серверы одновременно обращаются к базу за одними и теми же данными. Надо сделать так, чтобы максимально использовать преимущества параллелизма и быстрее обрабатывать данные таким способом.
Для слоя храненияизначального параллелизманадежноДля «железа»доступ к даннымSQLSQL не нуженSQL опять возвращаетсяВся математика оптимизации завязана вокруг реляционной алгебрыВ слое храненияДля «железа»
Примеры:Examples:
В следующих примерах используется база данных AdventureWorksPDW2012AdventureWorksPDW2012.The following examples use the AdventureWorksPDW2012AdventureWorksPDW2012 database.
В этом разделе приведены три примера кода.This section shows three code examples. В ходе выполнения первого примера кода возвращаются все строки (предложение WHERE не указано), а также все столбцы (используется ) таблицы .This first code example returns all rows (no WHERE clause is specified) and all columns (using the ) from the table.
В этом примере для достижения такого же результата используется присвоение псевдонима таблице.This next example using table aliasing to achieve the same result.
В ходе выполнения данного примера кода возвращаются все строки (предложение WHERE не задано) и подмножества столбцов (, , ) таблицы базы данных .This example returns all rows (no WHERE clause is specified) and a subset of the columns (, , ) from the table in the database. Заголовок третьего столбца переименовывается в .The third column heading is renamed to .
Этот пример возвращает только строки для , имеющие , не равное NULL, и , равное «M» (состоит в браке).This example returns only the rows for that have an that is not NULL and a of ‘M’ (married).
В.C. Совместное использование DISTINCT и SELECTUsing DISTINCT with SELECT
В следующем примере используется для создания списка всех уникальных должностей в таблице .The following example uses to generate a list of all unique titles in the table.
Г.D. Использование GROUP BYUsing GROUP BY
В следующем примере вычисляется общий объем всех продаж за каждый день.The following example finds the total amount for all sales on each day.
Так как в запросе используется предложение , то выводится только одна строка, содержащая общий объем продаж по каждому дню.Because of the clause, only one row containing the sum of all sales is returned for each day.
Д.E. Использование GROUP BY с несколькими группамиUsing GROUP BY with multiple groups
В следующем примере вычисляются значения средней цены и суммы продаж через Интернет за каждый день, сгруппированные по дате заказа и ключу продвижения.The following example finds the average price and the sum of Internet sales for each day, grouped by order date and the promotion key.
Е.F. Использование GROUP BY и WHEREUsing GROUP BY and WHERE
В следующем примере после извлечения строк, содержащих даты заказов позднее 1 августа 2002 г., происходит их разделение на группы.The following example puts the results into groups after retrieving only the rows with order dates later than August 1, 2002.
Ж.G. Использование GROUP BY с выражениемUsing GROUP BY with an expression
В следующем примере производится группировка с помощью выражения.The following example groups by an expression. Группировку можно производить только с помощью выражения, не содержащего агрегатных функций.You can group by an expression if the expression does not include aggregate functions.
З.H. Использование GROUP BY с ORDER BYUsing GROUP BY with ORDER BY
В следующем примере вычисляется сумма продаж за день и выполняется поиск заказов по определенному дню.The following example finds the sum of sales per day, and orders by the day.
И.I. Использование предложения HAVINGUsing the HAVING clause
Для ограничения результатов поиска в этом запросе используется предложение .This query uses the clause to restrict results.
SQL syntax used
User’s queries are executed by SQL server that brings some limitations to the
syntax of SQL statements. Now we use Microsoft SQL Server 2019 (15.0) on the rating stages,
and MariaDB-10.4 (compatible with MySQL 8), PostgreSQL 12.3, and Oracle Database 11g on the learn stage in addition. That is why You should follow
the syntax of these realizations when building queries. It should be noted that SQL syntax,
implemented in Microsoft SQL Server, is close to that of SQL-92 standard. But there are some
distinctions, among them is absence of NATURAL JOIN of tables. Supplied help on SQL Data Manipulation Language is held in accordance
with SQL-92 standard and contains information necessary for solving the exercises. In the same place it is possible to find features of used realization (SQL Server 2005).








