Как декодировать текст онлайн
Содержание:
- Введение
- Как правильно выбрать метод кодирования
- Изменение кодировки в программе «Notepad ++»
- В Windows 10 пропал курсор мыши, он дёргается или притормаживает: что делать?
- Якорный метод
- Кодировки стандарта ASCII[править]
- Рефлексотерапия
- Как поменять кодировку в «Mozilla Firefox»
- Как зайти на 192.168.1.1?!
- Два способа, как поменять кодировку в Word
- Пример
- 1251 – кодовая страница Windows
- 866 – кодовая страница DOS
- Кодировка UNICODE
- Читайте также
- Важность кодировки
- Сохранение с указанием кодировки
- Навигатор по конфигурации базы 1С 8.3 Промо
- Психотерапевтические способы
- encode заданной строки
- Прием
Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождение, название исследований записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того что в одном файле часть в кодировке CP1251 а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять что такое “кракозябры” или “кости” то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Как правильно выбрать метод кодирования
Зависимость от алкоголя лечится различными способами: к ним принадлежит использование лекарственных препаратов, а также множественные методики психологической коррекции состояния пациента.
Подбор метода осуществляется только врачом-наркологом и зависит исключительно от типа личности, степени внушаемости (то есть, показателя, который характеризует, насколько хорошо человек поддается гипнозу), а также интеллектуальной сохранности когнитивных функций.
Как правило, прекрасно срабатывает эмоционально-стрессовая терапия, но в некоторых случаях лучше помогает 12-шаговая программа. Но учтите, если человек сам не хочет избавиться от зависимости, никакая методика ему не поможет.
Гипноз является одним из наиболее эффективных способов кодирования, причем действовать в данном случае доктор нарколог будет на подсознание больного человека. Делать гипноз можно только трезвому пациенту, который не пил перед сеансом горячительные напитки в течение длительного периода времени.

Справедливости ради надо отметить, что есть пациенты, которым гипноз раз и навсегда помогал избавиться от зависимости, а другим он облегчал состояние только лишь на год или немного больше, потом приходилось кодироваться повторно.
Сейчас активно пропагандируется современный метод – кодировка при помощи лазера, однако это лечение имеет ряд недостатков, самым главным из которых является недолговечность оказываемого им эффекта на организм человека. Даже у тех алкоголиков, которые не входят в запой, придется повторять такое кодирование в течение года несколько раз.
Некоторые наркологи практикуют методику лечения по Бехтереву, но она оказывается эффективной только в тех случаях, где не затронуты когнитивные функции ЦНС (то есть, она помогает еще не полностью деградировавшим личностям).
Некоторые «психотерапевты» предлагают кодироваться по телефону или же по скайпу, однако большинство наркологов скептически относятся к данным методикам. При этом методе для достижения желаемого результата необходимо установление личностного, визуального контакта, а также прохождение специальных тестов, которые «терапия по телефону» или в онлайн-режиме провести не позволит по определению.
Помните, что идеального и универсального метода существовать не может, всегда к решению проблемы надо подходить индивидуально.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого
Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».

Выбираем вкладку «Кодировки»
Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.

Выбираем из списка необходимую кодировку, щелкаем на ней
Шаг 3
Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку
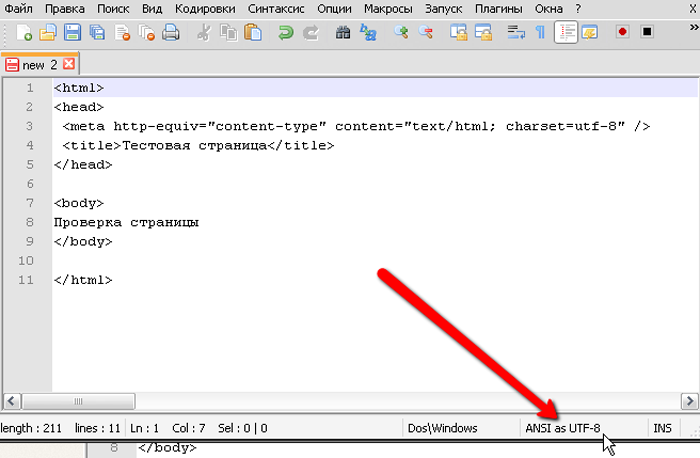
В нижней панели программы можно увидеть измененную кодировку
В Windows 10 пропал курсор мыши, он дёргается или притормаживает: что делать?
Якорный метод
Впервые этот прием, связанный с выработкой условных рефлексов, был описан Владимиром Михайловичем Бехтеревым в далеком 1895 году. Для установки специальных «якорей» не требуется вводить пациента в гипнотический сон. Достаточно выявить ситуацию, когда человек самостоятельно отказался от спиртного. После этого врач при помощи специальной методики устанавливает своеобразную метку, надежно сохраняемую в подсознании пациента. В дальнейшем этот «якорь» срабатывает, когда происходит повторение похожей ситуации, после чего человек начинает испытывать эмоциональные волнения – негативные или позитивные.
Плюсы «якорной» методики:
-
выработка условного рефлекса может происходить в сочетании с медикаментозным лечением;
-
установка «якорей» не вызывает побочных эффектов и не влияет на физиологические процессы в организме пациента.
Недостатки этой методики кодирования алкоголизма:
-
на формирование нового мышления требуется достаточно много времени;
-
пациент должен активно сотрудничать с лечащим врачом, выполняющим кодирование;
-
из-за достаточно высокой цены таким кодированием не могут воспользоваться люди с низкими доходами.
Кодировки стандарта ASCII[править]
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицыправить
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI | |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | ||
| 3 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ; | < | = | > | ? | ||
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | \ | ^ | _ | ||
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Рефлексотерапия
В организме человека находится огромное количество активных точек, являющихся сосредоточением нервных окончаний и сосудов. Выполняя кодирование алкоголизма, врач оказывает прямое воздействие на эти точки, чтобы стимулировать или блокировать определенные физиологические процессы. Для этого используется иглоукалывание, которое не нарушает целостности кожных покровов.
Преимущества иглоукалывания:
-
кодирование не оказывает какого-то сильного давления на сознание пациента;
-
кодирование алкоголизма по этой методике можно проводить даже в домашних условиях.
Минусы иглоукалывания:
Как поменять кодировку в «Mozilla Firefox»
Для этого пользователю потребуется:
Шаг 1. Запустить браузер и открыть меню, нажав по иконке трех линий левой клавишей мыши в правом верхнем углу страницы.

Нажимаем по иконке из трех линий в правом верхнем углу
Шаг 2. В контекстном меню запустить «Настройки».
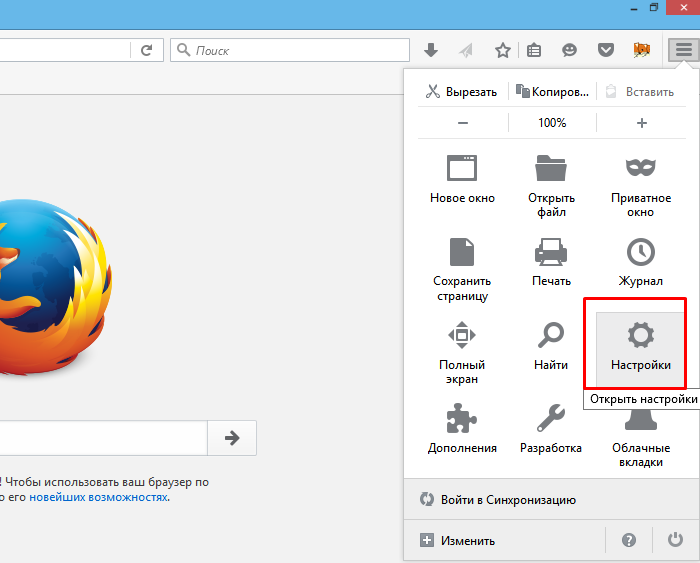
Открываем «Настройки»
Шаг 3. Перейти во вкладку «Содержимое».

Переходим во вкладку «Содержимое»
Шаг 4. В разделе «Шрифты и цвета» нажать на блок «Дополнительные».

В разделе «Шрифты и цвета» нажимаем по блоку «Дополнительно»
Шаг 5. Перед пользователем отобразится специальная панель, на которой будет указана использующаяся кодировка. Для ее изменения потребуется нажать на название кодировки и выбрать нужную.
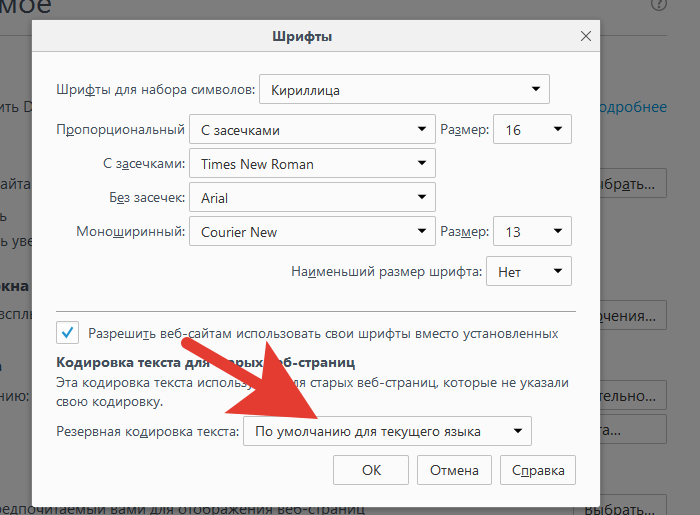
Нажимаем на название кодировки
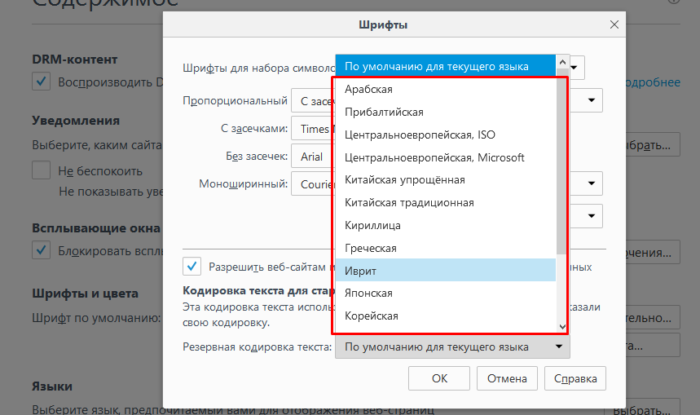
Выбираем подходящую кодировку, нажимаем «ОК»
Как зайти на 192.168.1.1?!
Два способа, как поменять кодировку в Word
Ввиду того, что текстовый редактор “Майкрософт Ворд” является самым популярным на рынке, именно форматы документов, которые присущи ему, можно чаще всего встретить в сети. Они могут отличаться лишь версиями (DOCX или DOC). Но даже с этими форматами программа может быть несовместима или же совместима не полностью.
Случаи некорректного отображения текста
Конечно, когда в программе наотрез отказываются открываться, казалось бы, родные форматы, это поправить очень сложно, а то и практически невозможно. Но, бывают случаи, когда они открываются, а их содержимое невозможно прочесть. Речь сейчас идет о тех случаях, когда вместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, “перевести” которые невозможно.
Эти случаи чаще всего связаны лишь с одним – с неверной кодировкой текста. Точнее, конечно, будет сказать, что кодировка не неверная, а просто другая. Не воспринимающаяся программой.
Интересно еще то, что общего стандарта для кодировки нет. То есть, она может разниться в зависимости от региона.
Так, создав файл, например, в Азии, скорее всего, открыв его в России, вы не сможете его прочитать.
В этой статье речь пойдет непосредственно о том, как поменять кодировку в Word. Кстати, это пригодится не только лишь для исправления вышеописанных “неисправностей”, но и, наоборот, для намеренного неправильного кодирования документа.
Определение
Перед рассказом о том, как поменять кодировку в Word, стоит дать определение этому понятию. Сейчас мы попробуем это сделать простым языком, чтобы даже далекий от этой тематики человек все понял.
Зайдем издалека. В “вордовском” файле содержится не текст, как многими принято считать, а лишь набор чисел. Именно они преобразовываются во всем понятные символы программой. Именно для этих целей применяется кодировка.
Кодировка – схема нумерации, числовое значение в которой соответствует конкретному символу. К слову, кодировка может в себя вмещать не только лишь цифровой набор, но и буквы, и специальные знаки. А ввиду того, что в каждом языке используются разные символы, то и кодировка в разных странах отличается.
Как поменять кодировку в Word. Способ первый
После того, как этому явлению было дано определение, можно переходить непосредственно к тому, как поменять кодировку в Word. Первый способ можно осуществить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных символов, это означает, что программа неверно определила кодировку текста и, соответственно, не способна его декодировать. Все, что нужно сделать для корректного отображения каждого символа, – это указать подходящую кодировку для отображения текста.
Говоря о том, как поменять кодировку в Word при открытии файла, вам необходимо сделать следующее:
- Нажать на вкладку “Файл” (в ранних версиях это кнопка “MS Office”).
- Перейти в категорию “Параметры”.
- Нажать по пункту “Дополнительно”.
- В открывшемся меню пролистать окно до пункта “Общие”.
- Поставить отметку рядом с “Подтверждать преобразование формата файла при открытии”.
- Нажать”ОК”.
Итак, полдела сделано. Скоро вы узнаете, как поменять кодировку текста в Word. Теперь, когда вы будете открывать файлы в программе “Ворд”, будет появляться окно. В нем вы сможете поменять кодировку открывающегося текста.
Выполните следующие действия:
- Откройте двойным кликом файл, который необходимо перекодировать.
- Кликните по пункту “Кодированный текст”, что находится в разделе “Преобразование файла”.
- В появившемся окне установите переключатель на пункт “Другая”.
- В выпадающем списке, что расположен рядом, определите нужную кодировку.
- Нажмите “ОК”.
Если вы выбрали верную кодировку, то после всего проделанного откроется документ с понятным для восприятия языком. В момент, когда вы выбираете кодировку, вы можете посмотреть, как будет выглядеть будущий файл, в окне “Образец”. Кстати, если вы думаете, как поменять кодировку в Word на MAC, для этого нужно выбрать из выпадающего списка соответствующий пункт.
Способ второй: во время сохранения документа
Суть второго способа довольно проста: открыть файл с некорректной кодировкой и сохранить его в подходящей. Делается это следующим образом:
- Нажмите “Файл”.
- Выберите “Сохранить как”.
- В выпадающем списке, что находится в разделе “Тип файла”, выберите “Обычный текст”.
- Кликните по “Сохранить”.
- В окне преобразования файла выберите предпочитаемую кодировку и нажмите “ОК”.
Теперь вы знаете два способа, как можно поменять кодировку текста в Word. Надеемся, что эта статья помогла вам в решении вопроса.
Пример
Давайте посмотрим, маленький полностью рабочий пример. Будет использоваться шрифт Calligrapher, который Вы можете скачать на сайте — http://www.abstractfonts.com/ (сайт, предлагает большое количество бесплатных TrueType шрифтов). Ссылка для загрузки шрифта — http://www.abstractfonts.com/download/52. Первым шагом является генерация AFM-файла:ttf2pt1 -a calligra.ttf calligra
которая дает calligra.afm (и calligra.t1a, который можно удалить). Затем мы создаем файл определения:
require('font/makefont/makefont.php');
MakeFont('calligra.ttf','calligra.afm');
|
Вызов функции даст следующие сообщения:
Warning: character Euro is missing
Warning: character eth is missing
Font file compressed (calligra.z)
Font definition file generated (calligra.php)
Символ Euro отсутствует, так как слишком старый. Другие символы также отсутствуют, однако они нам не понадобятся.
Теперь можно скопировать два файла в директорию и написать сценарий:
require('fpdf.php');
$pdf=new FPDF();
$pdf->AddFont('Calligrapher','','calligra.php');
$pdf->AddPage();
$pdf->SetFont('Calligrapher','',35);
$pdf->Cell(,10,'Enjoy new fonts with FPDF!');
$pdf->Output();
|
Вот что должно получиться в итоге:

1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 | 169 | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | эт, коммерческое эт, «собака» |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| левая открывающая квадратная скобка | |
| правая закрывающая квадратная скобка | |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| двоеточие | |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
| . | точка |
| слэш, косая черта, знак дроби | |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:
Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE typedef wchar_t TCHAR;#else typedef char TCHAR;#endif
_T(«строка»)tchar.hПредставление данных и архитектура ЭВМ
Читайте также
Важность кодировки
Поскольку кодирование и декодирование входной строки зависит от формата, мы должны быть осторожны при этих операциях. Если мы используем неправильный формат, это приведет к неправильному выводу и может вызвать ошибки.
Первое декодирование неверно, так как оно пытается декодировать входную строку, которая закодирована в формате UTF-8. Второй правильный, поскольку форматы кодирования и декодирования совпадают.
a = 'This is a bit möre cömplex sentence.'
print('Original string:', a)
# Encoding in UTF-8
encoded_bytes = a.encode('utf-8', 'replace')
# Trying to decode via ASCII, which is incorrect
decoded_incorrect = encoded_bytes.decode('ascii', 'replace')
decoded_correct = encoded_bytes.decode('utf-8', 'replace')
print('Incorrectly Decoded string:', decoded_incorrect)
print('Correctly Decoded string:', decoded_correct)
Вывод
Original string: This is a bit möre cömplex sentence. Incorrectly Decoded string: This is a bit m��re c��mplex sentence. Correctly Decoded string: This is a bit möre cömplex sentence.
Сохранение с указанием кодировки
У пользователя может возникнуть ситуация, когда он специально указывает определённую кодировку. Например, такое требование ему предъявляет получатель документа. В этом случае нужно будет сохранить документ как обычный текст через меню «Файл». Смысл в том, что для заданных форматов в Ворде есть привязанные глобальными системными настройками кодировки, а для «Обычного текста» такой связи не установлено. Поэтому Ворд предложит самостоятельно выбрать для него кодировку, показав уже знакомое нам окно преобразования документа. Выбирайте для него нужную вам кодировку, сохраняйте, и можно отправлять или передавать этот документ. Как вы понимаете, конечному получателю нужно будет сменить в своём текстовом редакторе кодировку на такую же, чтобы прочитать ваш текст.
Вопрос смены кодировки в Вордовских документах перед рядовыми пользователями встаёт не так уж часто. Как правило, текстовый процессор может сам автоматически определить требуемый для корректного отображения набор символов и показать текст в читаемом виде. Но из любого правила есть исключения, так что нужно и полезно уметь сделать это самому, благо, реализован процесс в Word достаточно просто.
То, что мы рассмотрели, действительно и для других программ из пакета Office. В них также могут возникнуть проблемы из-за, скажем, несовместимости форматов сохранённых файлов. Здесь пользователю придётся выполнить всё те же действия, так что эта статья может помочь не только работающим в Ворде. Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
Напоследок нужно сказать, что не всегда стоит обвинять кодировку. Возможно, всё гораздо проще. Дело в том, что многие пользователи в погоне за «красивостями» забывают о стандартизации. Если такой автор выберет установленный у него шрифт, наберёт с его помощью документ и сохранит, у него текст будет отображаться корректно. Но когда этот документ попадёт к человеку, у которого такой шрифт не установлен, то на экране окажется нечитаемый набор символов. Это очень похоже на «слетевшую» кодировку, так что легко ошибиться. Поэтому перед тем как пытаться раскодировать текст в Word, сначала попробуйте просто сменить шрифт.
Навигатор по конфигурации базы 1С 8.3 Промо
Универсальная внешняя обработка для просмотра метаданных конфигураций баз 1С 8.3.
Отображает свойства и реквизиты объектов конфигурации, их количество, основные права доступа и т.д.
Отображаемые характеристики объектов: свойства, реквизиты, стандартные рекизиты, реквизиты табличных частей, предопределенные данные, регистраторы для регистров, движения для документов, команды, чужие команды, подписки на события, подсистемы.
Отображает структуру хранения объектов базы данных, для регистров доступен сервис «Управление итогами».
Платформа 8.3, управляемые формы. Версия 1.1.0.71 от 01.12.2020
3 стартмани
Психотерапевтические способы
Если пациенту по каким-либо причинам не подходит медикаментозное кодирование, ему на помощь придут психотерапевтические способы кодировки от алкоголизма. Здесь основная задача психотерапевта – создать доверительные отношения с пациентом, чтобы создать нужную установку на отказ от спиртного и жизнь без пагубной привычки.
Метод Довженко
По мнению многих экспертов лучший способ кодирования алкоголизма – метод А. Р. Довженко. Уникальность метода в том, что все время общения со специалистом алкоголик находится в сознании. Действие метода основано не на отвращении к алкоголю, а на принятии установки о том, что алкоголь портит жизнь и самому пациенту, и его близким.
Методика заключается в поэтапном воздействии на сознание больного. Сначала это индивидуальные беседы с врачом, в ходе которых помимо прочего выясняется степень внушаемости человека. Затем проводятся групповые занятия, где специалист настраивает больных на успешный результат терапии и закрепляет в сознании плюсы трезвого образа жизни.
Наибольший эффект данный способ дает при наличии у алкоголика искреннего желания завязать с вредным пристрастием.
Гипноз по Рожнову
Еще один эффективный метод кодирования алкоголизма – эмоционально-стрессовая гипнотерапия по авторской методике В. Е. Рожнова. Способ предусматривает занятия в небольших группах (не более 15 участников) и основан на эмоциональном внушении, включающем одновременно приказ, осуждение и поддержку. В данном случае очень важна личность врача и его умение воздействовать на разных людей, управляя только своим голосом. Немалое значение играют и взаимоотношения, складывающиеся внутри группы.
Продолжительность одного сеанса 1,5 – 2 часа. Для получения стойкого результата в зависимости от сложности ситуации может потребоваться от 10 до 12 встреч. Точное количество сеансов определяет специалист.
encode заданной строки
Мы используем метод для входной строки, который есть у каждого строкового объекта.
Формат:
input_string.encode(encoding, errors)
Это кодирует с использованием , где определяют поведение, которому надо следовать, если по какой-либо случайности кодирование строки не выполняется.
приведет к последовательности .
inp_string = 'Hello' bytes_encoded = inp_string.encode() print(type(bytes_encoded))
Как и ожидалось, в результате получается объект :
<class 'bytes'>
Тип кодирования, которому надо следовать, отображается параметром . Существуют различные типы схем кодирования символов, из которых в Python по умолчанию используется схема UTF-8.
Рассмотрим параметр на примере.
a = 'This is a simple sentence.'
print('Original string:', a)
# Decodes to utf-8 by default
a_utf = a.encode()
print('Encoded string:', a_utf)
Вывод
Original string: This is a simple sentence. Encoded string: b'This is a simple sentence.'
Как вы можете заметить, мы закодировали входную строку в формате UTF-8. Хотя особой разницы нет, вы можете заметить, что строка имеет префикс . Это означает, что строка преобразуется в поток байтов.
На самом деле это представляется только как исходная строка для удобства чтения с префиксом , чтобы обозначить, что это не строка, а последовательность байтов.
Прием
Косплеер в роли Аски на выставке Marseilles Japan Expo 2011
Аска участвовала в различных опросах лучших аниме-пилотов и женских аниме-персонажей, оказавшись популярной как среди женской, так и среди мужской аудитории. В 1996 году она заняла третье место среди «самых популярных женских персонажей на данный момент» в обзоре Гран-при аниме от Animage mangazine, после Рей Аянами и Хикару Шидо из Magic Knight Rayearth . В 1997 и 1998 годах на Гран-при аниме ей также удалось остаться в десятке лучших женских персонажей; в 1997 году она заняла четвертое место, а в 1998 году — шестое. В ежемесячных опросах популярности Animage Аска также заняла третье место в августе 1996 года и седьмое в июле 1998 года. Ее популярность возросла после выхода второго фильма Rebuild of Evangelion ; в августе и сентябре 2009 года она вышла на первое место и оставалась самым популярным женским персонажем Neon Genesis Evangelion в рейтинге популярности журнала Newtype , а в октябре она заняла десятое место. В опросе Newtype, проведенном в марте 2010 года, она была признана третьим по популярности женским аниме-персонажем 1990-х годов сразу после Рей Аянами и Усаги Цукино из Pretty Guardian Sailor Moon . В 2017 году она заняла 16-е место среди персонажей аниме, с которыми читатели аниме предпочли бы умереть, чем выйти замуж.
Ее строчка «Ты дурак?» стала широко использоваться среди хардкорных фанатов с момента ее первого появления в 8-м эпизоде. Ценив ее за «хорошую дозу комического облегчения» Евангелиону , аниме-критик Пит Харкофф назвал ее «надоедливой соплей». Рафаэль Си из THEM Anime Reviews, который нашел характеристику Neon Genesis Evangelion «немного клише или временами просто раздражающей», презирал Аску за ее высокомерное отношение. Редактор Anime News Network Линзи Ловеридж заняла свое седьмое место среди «худших неудачников» в истории аниме. Критик IGN Рэмси Айслер назвал ее 13-м величайшим персонажем аниме всех времен за реалистичность ее персонажей, сказав: «Она трагический персонаж и полная крушение поезда, но именно это делает ее такой привлекательной, потому что мы просто не можем помогите, но наблюдайте, как разворачивается эта прекрасная катастрофа «. CBR включил ее в число лучших женщин-пилотов аниме, назвав ее «лучшим классическим цундэрэ в аниме сёнэн» и «одним из самых захватывающих персонажей аниме».
По словам критика Джея Телотта, Аска «является первым заслуживающим доверия многонациональным персонажем в истории японской SFTV». Crunchyroll также похвалил ее реализм и оригинальность, а Чарапедия написала: «Описание ее психологии реалистично и без принуждения, в отличие от многих других аниме-персонажей. Ее добрая и детская сторона — настоящая причина обаяния Аски». Бой Аски против евангелионов массового производства в «Конец Евангелиона» был особенно хорошо принят критиками, которые считали, что это был ее решающий момент, поскольку в остальном она остается статичной на протяжении большей части фильма. Также похвалили Тиффани Грант за роль актрисы озвучивания Аски на английском языке. Майк Крэндол из Anime News Network заявил, что Грант был «ее старым пылким я в роли Аски». Терон Мартин написала, что изображение Аски в Evangelion: 2.0 You Can (Not) Advance «отличается от начального», заявив, что она даже более антисоциальна, чем в оригинальном аниме. Мартин также написал, что, несмотря на то, что она кажется «наиболее социально адаптированным пилотом Евы в сериале», Аска из Evangelion 2.0 «не претендует на то, чтобы кому-то понравиться», и что она «кажется, в такой же степени мотивирована тем, что сделает свою будущую карьеру. в Nerv, как и она из-за своей личной гордости ». Эрик Суррелл также прокомментировал роль Аски в Evangelion: 2.0 You Can (Not) Advance, заявив, что «прибытие и внезапное увольнение Аски было шокирующим и депрессивным, особенно учитывая, насколько она была неотъемлемой частью оригинального Evangelion ». Саймон Абрамс из Slant Magazine , рецензирующий Evangelion: 2.0 You Can (Not) Advance , негативно оценил новые отношения Синдзи и Аски, «что прискорбно, потому что эта связь должна иметь возможность расти в свое время».








