Распознаем текст онлайн с картинок, отсканированных документов бесплатно и без регистрации
Содержание:
- Как это устроено?
- Что еще умеет «Яндекс.почта»
- ВИДЫ ЭП
- Перевод при помощи ABBYY Fine Reader
- OCR по шагам
- Что делать с рукописным вводом?
- ТОП-5 программ для распознавания рукописных текстов
- Newocr.com – поможет скопировать надпись с любой картинки
- ABBYY FineReader
- ABBYY FineReader
- Выбор
- Capture2Text
- Как распознать текст онлайн с помощью Whatfontis.com
- Толщина наливного пола
- Приложения для перевода с фотографий
- Как при помощи онлайн-сервисом можно скопировать текст с изображения
- Преобразование графического файла
- Что нужно для сканирования и распознавания?
- Что такое Гугл Диск и что такое Гугл Документы
Как это устроено?
Представьте, что в алфавите есть только одна буква «А». Сделает ли это задачу преобразования картинки в текст проще? Нет. Дело в том, что у каждой буквы (и любой другой графемы) есть аллографы — различные варианты начертания.
Варианты начертания буквы «а».
Человек легко поймет, что все это буква «А». Для компьютера же есть два способа решения проблемы: распознавать символы целостно (распознавание паттерна) или выделять отдельные черты, из которых состоит символ (выявление признаков).
Распознавание паттерна
В 1960-х годах был создан специальный шрифт OCR-A, который использовался в документах типа банковских чеков. Каждая буква в нем была одинаковой ширины (т.н. шрифт фиксированной ширины или моноширинный шрифт).

Образец шрифта OCR-A
Принтеры для чеков работали с этим шрифтом, и для его распознавания было разработано программное обеспечение. Поскольку шрифт был стандартизирован, его распознавание стало относительно простой задачей. Следующим шагом стало обучение программ OCR распознавать символы еще в нескольких самых распространенных шрифтах (Times, Helvetica, Courier и т.д.).
Выявление признаков
Этот способ еще называют интеллектуальным распознаванием символов (англ. intelligent character recognition, ICR). Представьте, что вы — OCR-программа, которой дали множество разных букв, написанных разными шрифтами. Как вам отобрать из этого множества все буквы «А», если каждая из них немного отличается от другой?

Можно использовать такое правило: если видишь две линии, сходящиеся наверху в центре под углом, а посередине между ними горизонтальная линия, то это буква «А». Это правило поможет распознать все буквы «А» независимо от шрифта. Вместо распознавания паттерна выделяются характерные индивидуальные черты, из которых состоит символ. Большинство современных омнишрифтовых (умеющих распознавать любой шрифт) OCR-программ работают по этому принципу. Чаще всего в них используются классификаторы на основе машинного обучения (т.к. фактически перед нами стоит задача классификации картинок по классам-буквам) в последнее время некоторые OCR-движки перешли на нейронные сети.
Что еще умеет «Яндекс.почта»
В конце июля 2020 г. CNews писал о появлении в «Яндекс.почте» так называемой «карточке контакта». С ее помощью можно связаться с нужным человеком, написать ему письмо, отравив сообщение в мессенджере или просто позвонив. Также карточка контакта позволяет назначать встречу или смотреть переписку, в которой участвовал этот человек.
Чтобы перейти к карточке того или иного пользователя, нужно кликнуть по его аватарке. Карточка поможет не только начать общение, но и вспомнить, чем оно закончилось. В ней отображается последняя реплика человека в мессенджере, а также дата и тема ближайшей встречи. А если кликнуть на кнопку «Письма», можно увидеть всю переписку, в которой участвовал пользователь.
Как и в случае с распознаванием текста, карточка контакта была внедрена в первую очередь в Android-приложение «Яндекс.почты».
- Короткая ссылка
- Распечатать
ВИДЫ ЭП
Перевод при помощи ABBYY Fine Reader
Адоб ФайнРидер – самый простой и эффективный инструмент OCR. Программа является условно бесплатной – то есть пользователю дают пробный период (30 дней), в течение которого он может распознать определённое количество страниц (100 штук).

Разумеется, месяца достаточно, чтобы понять, действительно ли тебе нужен инструмент и насколько хорошо он справляется с возложенными на него задачами.
Стоимость «полной» Adobe FineReader 14 (последней русской версии) в тарифе «Standard» (для домашнего использования) составляет 6 990 рублей. ПО для Mac стоит дешевле – 4 290 рублей. Купить или скачать пробную версию Файн Ридера можно .
После запуска программы на экране появляется такое окно:
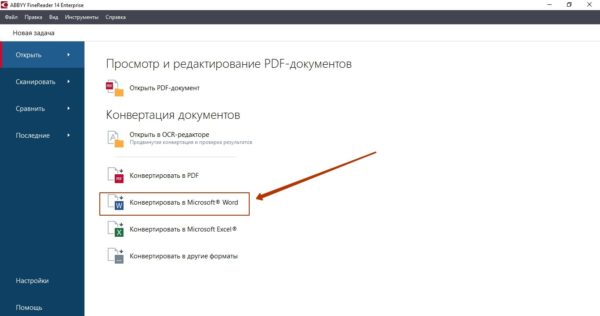
Для конвертации из PDF в Word нужно выбрать вариант «Конвертировать в Microsoft Word». Далее загрузите документ, который хотите преобразовать, через «Проводник». Не забудьте установить язык распознавания в поле слева. Adobe Fine Reader поддерживает почти 200 языков, поэтому нужный вы наверняка найдёте. По умолчанию выбраны русский и английский – это значит, даже если текст состоит вперемешку из слов двух языков, программа выдаст корректный результат.
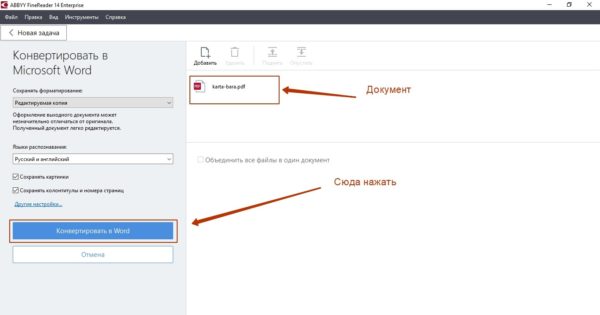
Наконец, нажмите «Конвертировать в Word» и ожидайте завершения процедуры. Я для теста распознавал меню одного из московских кафе, состоящее из 18 страниц. Времени отняло секунд 30. Ниже два документа: что было и что получилось.
Меню в формате PDF
Меню в формате DOCX
Насколько хорошо справилась прога Adobe Fine Reader, решайте сами. На мой взгляд, почти идеально – даже форматирование сохранила.
Функционал проги настолько широк, что она способна распознать текст не только с ПДФ-документа, но и с картинки – а также просканировать сразу несколько доков и скомпилировать их в один вордовский файл.
Из минусов программы – она много весит и сильно тормозит компьютер с небольшим объёмом оперативной памяти.
OCR по шагам
Предобработка
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы. Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Распознавание
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой. Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Постобработка
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Особые случаи
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из: 1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью; 2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией; 3) извлечение изображений размеченных символов на основе этого соотнесения; 4) выбор из размеченных символов подходящих обучающих примеров.Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
Что делать с рукописным вводом?
Человек способен догадаться о смысле предложения, даже если оно написано самым неразборчивым почерком (если речь не идет о рецепте на лекарства, конечно).

Задачу для компьютера иногда упрощают. Например, людей просят писать почтовый индекс в специальном месте на конверте специальным шрифтом. Формы, созданные для дальнейшей обработки компьютером, обычно имеют отдельные поля, которые просят заполнять печатными буквами.
Планшеты и смартфоны, которые поддерживают рукописный ввод, часто используют принцип выявления признаков. При написании буквы «А» экран «чувствует», что сначала пользователь написал одну линию под углом, затем вторую, и, наконец, провел горизонтальную черту между ними. Компьютеру помогает то, что все признаки появляются последовательно, один за другим, в отличие от варианта, когда весь текст уже записан от руки на бумаге.
ТОП-5 программ для распознавания рукописных текстов
За время существование компьютеров было создано много программ, которые умеют интерпретировать рукописный ввод. С течением времени они развивались и улучшались. На сегодняшний день есть программы, которые могут с очень высокой точностью распознавать текст, написанный от руки, при этом они поддерживают все самые распостраненные языки в мире.
Выбирать программу нужно исходя из своих потребностей, потому что у них разные функционал и стоимость (бесплатные или платные). Популярных программ много, но не все качественно справляются со своими задачами. Мы выделили ТОП-5 лучших, с помощью которых можно будет решить проблему распознавания рукописного ввода. Давайте рассмотрим каждую подробнее.
Newocr.com – поможет скопировать надпись с любой картинки
Другой качественный ресурс, о котором мы хотим рассказать – это newocr.com. Его возможности позволяют распознать текст с 106 языков, он бесплатен и не требует регистрации. Количество загрузок пользовательских фотографий на ресурс неограниченно, сервис хорошо распознаёт изображение с несколькими слоями. Полученный результат можно скачать на ПК, отредактировать в Гугл Докс, перевести через Google или Bing Переводчик.
Для работы с сервисом выполните следующее:
- Запустите newocr.com;
- В графе «Recognition language» (языки распознавания) выберите языки, на которых написан текст в изображении;
- Нажмите на «Обзор», и укажите сервису путь к нужному изображению;
- Для загрузки картинки на ресурс и её распознавания кликните на кнопку «Upload+OCR»;
- Просмотрите полученный результат. При необходимости с помощью рамки отметьте место в тексте, где расположен нужный для распознавания текст;
-
Для его сохранения на ПК нажмите на кнопку «Download».
ABBYY FineReader
Когда дело доходит до оптического распознавания символов, вряд ли найдется что-то, что даже близко подходит к ABBYY FineReader. ABBYY FineReader позволяет загружать текст со всех видов изображений на одном дыхании.
Несмотря на широкий набор функций, ABBYY FineReader очень прост в использовании. Он может извлекать текст практически из всех популярных форматы изображений, такие как PNG, JPG, BMP и TIFF. И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU. После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 т / д для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, имеющие извлекаемый текст. Вы можете либо извлечь весь текст, либо выбрать только некоторые конкретные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать формат вывода, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
Выводимый текст является полностью редактируемым, и текст даже из самых содержательных документов (например, имеющих несколько столбцов и сложные макеты) извлекается безупречно. Другие функции включают в себя обширная языковая поддержка, многочисленные стили шрифтов / размеры и инструменты коррекции изображения для файлов, полученных из сканеров и камер.
Сказав все это, то, что отличает ABBYY FineReader от остальных программ, это его почти идеальная точность. С новым обновлением Finereader 15, теперь программное обеспечение использует AI для улучшения распознавания символов, AI особенно используется при извлечении текстов из документов, написанных на японском, корейском и китайском языках. Таким образом, если вы хотите получить абсолютно лучшее программное обеспечение для оптического распознавания текста с расширенными функциями, расширенным форматом ввода-вывода и поддержкой обработки, выберите ABBYY FineReader.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 199, доступна 30-дневная бесплатная пробная версия
ABBYY FineReader
ABBYY FineReader — программа для работы с PDF-документами. Утилита дает возможность распознавать отсканированные тексты разных форматов. Всего поддерживается 192 языка для распознавания. При необходимости можно конвертировать документ из одного формата в другой.
Приложение полностью совместимо с операционной системой Windows (32/64 бит). Для загрузки доступна полностью русская версия. Программа работает на Windows 7 и новее, доступна возможность работы на серверных операционных системах. Модель распространения утилиты ABBYY FineReader — платная. Для получения полной версии приложения необходимо купить лицензию. Стоимость электронной версии на 1 год составляет 3190 рублей. Цена бессрочной версии — 6990 рублей. Утилита доступна только для домашнего использования.
Чтобы ознакомиться со всеми функциями программы, можно загрузить бесплатную демо-версию. Срок действия ознакомительной версии — 30 дней. После запуска утилиты откроется главное окно «Новая задача». Здесь доступно несколько основных разделов: открыть, сканировать и сравнить.
В разделе «Открыть» доступно много инструментов.
- Открыть PDF-документ для просмотра и редактирования файла: с помощью этого инструмента пользователи могут установить защиту на документ, оставлять комментарии на страницы или для отдельных текстовых блоков.
- OCR-редактор: используется для продвинутой конвертации документов, проверки распознания текста, ручной разметки областей распознавания.
- Конвертирование документа из одного формата в другой: PDF, Word, Excel. Пункт «Конвертировать в другие форматы» дает возможность пользователям выбрать нужный формат.
- Раздел «Сканировать» используется для сканирования документов различных форматов: PDF, Word, Excel, графические изображения и т.д. Доступна возможность сканирования в OCR-редактор. Здесь расположена функция распознавания текста. Можно обучить приложение распознавать нестандартные символы и шрифты.
- «Сравнение» — этот раздел используется для сравнение нескольких версий документов. Инструмент помогает быстро найти различия в текстах — найденные отличия выделяются цветом. Воспользоваться инструментом для сравнения файлов можно только в лицензионной версии программы ABBYY FineReader.
Преимущества ABBYY FineReader:
- простой и удобный интерфейс с поддержкой русского языка;
- большой набор инструментов для распознавания текста;
- возможность конвертирования файлов из одного формата в другой;
- функция сравнения текстов для поиска отличий.
Недостатки:
не поддерживается операционная система Windows XP и старше.
Выбор
Как же выбрать наиболее подходящую программу, и какие основные особенности имеет такой софт?
Отличаться он может по разным показателям – точности распознавания, способности работать с тем или иным языком, возможности сохранять исходную структуру текста и т. п.
Такой софт может распространяться платно и бесплатно, и быть реализован как онлайн (в виде особых сервисов), так и в форме предустанавливаемых программ.
Алгоритм работы заключается в том, что для каждой буквы алфавита составляется база вариантов того, как она может выглядеть на фото, выделяются и сохраняются ее основные элементы. Как только такие элементы обнаруживаются на фото, программа распознает соответствующую букву. В зависимости от того, насколько качественно и подробно была составлена такая база, зависит качество распознавания материала в итоге.
Потому важно, чтобы софт был рассчитан на работу именно с русским языком (некоторые программы могут работать с текстом, написанным сразу на двух языках, другие – нет). Кроме того, некоторые утилиты и сервисы способны сохранять даже изначальную структуру текста (таблицы, списки), тип его оформления (отступы и т
п.) и даже шрифт
Кроме того, некоторые утилиты и сервисы способны сохранять даже изначальную структуру текста (таблицы, списки), тип его оформления (отступы и т. п.) и даже шрифт.
В каких же случаях такой софт необходим?
- При создании документов, когда имеется только распечатанный вариант;
- При составлении рефератов, докладов и необходимости процитировать в них большой отрывок текста из книги;
- Для редакторских работ, когда текст имеется лишь в формате фото и т. д.
На самом деле сфера использования софта очень велика, и правильно выбранный, он способен облегчить и ускорить работу с текстом.

<Рис. 1 Распознавание>
Capture2Text
Capture2Text – это бесплатное программное обеспечение для оптического распознавания символов для Windows 10, которое предоставляет вам комбинации клавиш для быстрого распознавания текста на экране. Это также не требует никакой установки.
Используйте сочетание клавиш по умолчанию WinKey + Q активировать процесс распознавания. Затем вы можете использовать мышь, чтобы выбрать часть, которую вы хотите захватить. Нажмите Enter, и тогда выбор будет оптически распознан. Захваченный и преобразованный текст появится во всплывающем окне, а также будет скопирован в буфер обмена.
Capture2Text использует механизм распознавания текста Google и поддерживает более 100 языков. Он использует Google Translate для преобразования захваченного текста на другие языки. Заглянуть внутрь настройки настроить различные параметры, предоставляемые программным обеспечением.
Скачать: Capture2Text (бесплатно)
Как распознать текст онлайн с помощью Whatfontis.com
Англоязычный ресурс whatfontis.com может похвалиться огромной базой коммерческих и бесплатных шрифтов, а также развитым AI для их поиска. Авторы ресурса обещают найти 60 платных и 60 бесплатных шрифтов-аналогов для каждого загруженного пользователем шрифта. Ресурс имеет не только инструментарий для идентификации шрифтов онлайн, но и форум, на котором вы найдёте помощь людей.
При этом функционал ресурса в последнее время был существенно переработан, улучшены возможности для поиска нужного шрифта, ускорен сам процесс поиска, система приобрела ещё более автоматизированный характер.
Выполните следующее:
- Перейдите на whatfontis.com;
-
Кликните на «Browse» для загрузки картинки со шрифтом на ресурс;
Кликните на «Browse» для загрузки изображения со шрифтом на ресурс
- После загрузки картинки сервис предложит вам помочь с идентификацией отдельных букв (достаточно 4-10 букв). Введите их правильные значения под каждой из предложенных букв ниже. Затем нажмите на «Continue»;
- Просмотрите полученные результаты с возможностью сохранения нужно шрифта (кнопка «Download»).Сохраните нужный шрифт с помощью сервиса Whatfontis.com
«IdentiFont» сервис для поиска шрифта
Особенностью сервиса «IdentiFont» является возможность определить шрифт по наводящим вопросам, которые сервис вам задаст. При этом сайт использует англоязычный интерфейс, что существенно ограничивает возможности русскоязычного пользователя.
Данный сайт обладает пятью уникальными инструментами:
- «Fonts by Appearance» (идентификация шрифта по внешнему виду);
- «Fonts by Name» (определение шрифта по названию или части названия);
- «Fonts by Similarity» ( по схожести);
- «Fonts by Picture» (поиск почерка по картинке);
- «Fonts by Designer/Publisher» (по имени создателя или издателя).
Выбрав один из предложенных пяти инструментов вы сможете опознать нужный шрифт онлайн.
Рабочее окно сервиса «IdentiFont»
Англоязычный сервис для определения шрифтов Fontsquirrel.com
Данный сервис по своему функционалу похож на уже упомянутый мной «WhatTheFont», позволяя определить шрифт. При этом он имеет ряд специфических особенностей, в частности, на сайте имеется фоторедактор, позволяющий обрабатывать текст для лучшего распознавания шрифта в режиме онлайн. Кроме того, вы можете добавлять характеристики для загружаемой вами картинки для лучшей идентификации шрифта.
- Для работы с ресурсом перейдите на fontspring.com.
- И нажмите на кнопку «Upload Image» для загрузки картинки с нужным шрифтом на ресурс.
- Разместите нужный вам текст с картинки в центре рамки и нажмите на кнопку «Matcherate It!» внизу (процедура de facto идентична вышеописанному ресурсу «FontSquirrel»).
- Вы получите результат со списком найденных совпадений.
Рабочее окно сервиса «FONTSPRING»
Толщина наливного пола
Приложения для перевода с фотографий
Мобильное приложение, которое умеет переводить текст с фотографий, — отличный помощник в путешествиях. Благодаря ему вы сможете переводить вывески, меню и любую другую информацию, которая попадает в объектив камеры смартфона.
Google Translate
Google Translate — самое популярное приложение для перевода на Android. Среди его возможностей есть и функция распознавания текста с фотографий и любых других изображений.
Главное достоинство Google Translate — моментальный перевод прямо в интерфейсе камеры. Чтобы понять, что написано на вывеске или в меню ресторана, не нужно даже делать снимок — главное, чтобы было подключение к Интернету.
В режиме распознавания через камеру поддерживается 38 языков.
- Запустите Google Translate.
- Нажмите на значок камеры.
- Выберите язык, на который нужно перевести текст.
- Наведите объектив на текст и дождитесь появления перевода на экране прямо поверх изображения.
Вы также можете выбирать изображения из памяти телефона. Для этого приложению нужно дать разрешение на доступ к хранилищу.
Среди других возможностей Google Translate:
- Поддержка 103 языков для перевода.
- Быстрый перевод фрагментов текста из других приложений.
- Режим разговора с озвучиванием перевода.
- Рукописный и голосовой ввод.
- Разговорник для сохранения слов на разных языках.
Google Translate показывает лучшие результаты распознавания и перевода. Он справляется с текстами, которые другие программы не могут обработать корректно.
Переводчик Microsoft
Корпорация Microsoft тоже позаботилась об удобстве пользователей и добавила функцию распознавания текста с фотографий в свой переводчик. Который, кстати, поддерживает более 60 языков.
Для перевода текста с фотографии:
- Запустите Переводчик Microsoft и нажмите на значок камеры.
- Выберите язык оригинала и перевода.
- Наведите камеру на текст и сфотографируйте его.
- Дождитесь завершения обработки.
При желании можно импортировать фото из галереи, предварительно дав приложению разрешение на доступ к памяти смартфона.
Среди других возможностей программы:
- Разговорники и руководство по произношению.
- Встроенный словарь для изучения разных значений слов.
- Режим разговора с синхронным переводом речи.
- Режим многопользовательского общения (до 100 собеседников, разговаривающих на разных языках).
Переводчик от Microsoft не всегда справляется с поставленной задачей, но простую графику с текстом распознаёт без ошибок.
Translate.ru
Translate.ru от PROMT — единственное приложение, которое умеет распознавать и переводить текст с фотографий без подключения к интернету.
Чтобы функция работала, вам нужно предварительно скачать языковой пакет OCR. Выбирать следует тот язык, с которого вы планируете переводить.
Как это сделать:
- Выберите значок камеры в главном окне приложения.
- Нажмите «Ок» при появлении сообщения о том, что пакетов для распознавания текста нет.
- Перейдите на вкладку с доступными для установки пакетами.
- Выберите язык, с которого собираетесь переводить текст.
- Установите пакет (желательно подключение через Wi-FI, так как файл весит 20-30 Мб).
- Вернитесь на главное окно, наведите камеру на изображение с текстом и сделайте фотографию.
- Дождитесь результата распознавания и перевода.
Translate.ru также поддерживает импорт изображений из галереи. Для этого требуется разрешение на доступ приложения к памяти смартфона. Среди других возможностей переводчика:
- Встроенный разговорник для сохранения слов и фраз.
- Голосовой и рукописный ввод.
- Отображение транскрипции и воспроизведение оригинала текста носителем языка.
- Режим диалога для общения собеседников на разных языках.
Translate.ru неплохо справляется с переводом, но незаменимым его можно считать только в одном случае — если вам срочно нужен перевод, а на телефоне нет доступа в Интернет.
Как при помощи онлайн-сервисом можно скопировать текст с изображения
Технология, которая поможет нам перекопировать надпись с картинки, носит название «OCR» («Optical Character Recognition – оптическое распознавание символов). Первый патент на оптическое распознавание текста был выдан в Германии ещё в далёком 1929 году. С тех пор наука шагнула далеко вперёд, и качество распознавания текстов существенно выросло. К примеру, в случае латинских символов качество распознавания может достигать 99% всего текста. В случае же кириллицы этот процент несколько меньше, что поясняется «латинским» акцентом большинства современных сервисов и программ.
Эффективное распознавание текста возможно при наличии чёткого изображения, где все буквы визуально отделены одна от другой. В случае «замыленного» изображения, в котором буквы связаны друг с другом, имеют витиеватый характер, распознавание будет некачественным. В некоторых случаях вы и вовсе получите отсутствие какого-либо результата.
Работа с такими сервисами проста:
- Вы переходите на такой ресурс, и загружаете на него изображение с текстом.
- Указываете язык, на котором написан имеющийся на изображении текст.
- При наличии на ресурсе возможности, выбираете ту часть изображения, на которой расположен нужный текст.
- Затем запускаете процедуру распознавания онлайн, и обычно через пару секунд получаете результат.
Давайте разберём сервисы, позволяющие выделить текст с графического изображения online.
Преобразование графического файла
- Откройте страницу drive.google.com на компьютере.
- Нажмите на нужный файл правой кнопкой мыши.
- Выберите Открыть с помощью Google Документы.
- Графический файл будет преобразован в документ Google. При этом некоторые параметры форматирования могут не сохраниться.
- Тип, начертание (полужирный, курсив) и размер шрифта, а также переносы строк обычно сохраняются.
- Списки, таблицы, столбцы, обычные и концевые сноски, скорее всего, не сохранятся.
Поддерживаемые языки
- Ачехский
- Ачоли
- Адангме
- Африкаанс
- Акан
- Албанский
- Алгонкинский
- Амхарский
- Древнегреческий
- Арабский (современный стандартный)
- Арауканский/мапуче
- Армянский
- Ассамский
- Астурийский
- Атабаскский
- Аймара
- Азербайджанский
- Азербайджанский (дореформенная кириллица)
- Балийский
- Бамбара
- Банту
- Башкирский
- Баскский
- Батак
- Белорусский
- Бемба
- Бенгальский
- Бикольский
- Бислама
- Боснийский
- Бретонский
- Болгарский
- Бирманский
- Каталанский
- Себуанский
- Чеченский
- Чероки
- Китайский (мандаринский, Гонконг)
- Китайский (упрощенный, мандаринский)
- Китайский (традиционный, мандаринский)
- Чоктавский
- Чувашский
- Кри
- Крикский
- Крымско-татарский
- Хорватский
- Чешский
- Дакота
- Датский
- Дивехи
- Дуала
- Нидерландский
- Дзонг-кэ
- Эфик
- Английский (США)
- Английский (Великобритания)
- Эсперанто
- Эстонский
- Эве
- Фарерский
- Фиджийский
- Филиппинский
- Финский
- Фон
- Французский (Канада)
- Французский (Европа)
- Фула
- Га
- Галисийский
- Ганда
- Гайо
- Грузинский
- Немецкий
- Кирибати
- Готский
- Греческий
- Гуарани
- Гуджарати
- Гаитянский креольский
- Хауса
- Гавайский
- Иврит
- Гереро
- Хилигайнон
Хинди - Венгерский
- Ибанский
- Исландский
- Игбо
- Илоканский
- Индонезийский
- Ирландский
- Итальянский
- Японский
- Яванский
- Кабильский
- Качинский
- Гренландский
- Камба
- Каннада
- Канури
- Каракалпакский
- Казахский
- Кхаси
- Кхмерский
- Кикуйю
- Киньярванда
- Киргизский
- Коми
- Конго
- Корейский
- Косяэ
- Куаньяма
- Лаосский
- Латынь
- Латышский
- Лингала
- Литовский
- Нижненемецкий
- Лози
- Луба-катанга
- Луо
- Македонский
- Мадурский
- Малагасийский
- Малайский
- Малаялам
- Мальтийский
- Мандинго
- Мэнский
- Маори
- Маратхи
- Маршалльский
- Менде
- Среднеанглийский
- Средневерхненемецкий
- Минангкабау
- Могаукский
- Монго
- Монгольский
- Науатль
- Навахо
- Ндонга
- Непальский
- Ниуэ
- Северный ндебеле
- Северный сото
- Норвежский (букмол)
- Ньянджа
- Ньянколе
- Тонга (Ньяса)
- Нзима
- Окситанский
- Оджибве
- Древнеанглийский
- Старофранцузский
- Древневерхненемецкий
- Древнескандинавский
- Старопровансальский
- Ория
- Осетинский
- Пампанга
- Пангасинанский
- Папьяменто
- Пушту
- Персидский
- Польский
- Португальский (Бразилия)
- Португальский (Европа)
- Панджаби (гурмукхи)
- Кечуа
- Румынский
- Романшский
- Цыганский
- Рунди
- Русский
- Русский (дореформенный)
- Якутский
- Самоанский
- Санго
- Санскрит
- Шотландский
- Шотландский (гэльский)
- Сербский (кириллица)
- Сербский (латиница)
- Шона
- Сингальский
- Словацкий
- Словенский
- Сонгай
- Южный сото
- Испанский (Европа)
- Испанский (Латинская Америка)
- Сунданский
- Суахили
- Свати
- Шведский
- Таитянский
- Таджикский
- Тамильский
- Татарский
- Телугу
- Темне
- Тайский
- Тибетский
- Тигринья
- Тонганский
- Тсонга
- Тсвана
- Турецкий
- Туркменский
- Удмуртский
- Урду
- Узбекский
- Узбекский (дореформенная кириллица)
- Венда
- Вьетнамский
- Водский
- Валлийский
- Фризский (западный диалект)
- Волоф
- Коса
- Идиш
- Йоруба
- Сапотекский
- Зулу
Что нужно для сканирования и распознавания?
1) Сканер
Для перевода печатных документов в текстовый вид, вам для начала нужен сканер и соответственно, «родные» программы и драйверы, которые с ним шли. При помощи них можно будет сканировать документ и сохранить его для дальнейшей обработки.
Можно воспользоваться и другими аналогами, но софт, который шел со сканером в комплекте, обычно работает быстрее и имеет больше опций.
В зависимости от того, какой у вас сканер — скорость работы может существенно различаться. Есть сканеры, которые могут получить картинку с листа за 10 сек., есть которые будут получать за 30 сек. Если сканируете книгу на 200-300 листов — думаю, не трудно подсчитать во сколько раз будет разница во времени?
2) Программа для распознавания
В нашей статье я буду показывать вам работу в одной из лучших программ для сканирования и распознавания абсолютно любых документов — ABBYY FineReader. Т.к. программа платная, то сразу дам ссылку и на другую — ее бесплатный аналог Cunei Form. Правда, я бы не стал их сравнивать, ввиду того, что FineReader выигрывает по всем параметрам, рекомендую все же попробовать именно ее.

ABBYY FineReader 11
Одна из лучших программ в своем роде. Она предназначена для того, чтобы распознать текст на картинке. Встроено множество опций и функций. Может разобрать кучу шрифтов, поддерживает даже рукописные варианты (правда, лично не пробовал, думаю, хорошо вряд ли будет распознавать рукописный вариант, если только у вас не идеальный каллиграфический почерк). Более подробно о работе с ней будет рассказано ниже. Здесь же отметим, что в статье будет рассказано о работе в программе 11 версии.
Как правило, разные версии ABBYY FineReader не сильно отличаются друг от друга. Вы без труда сделаете то же самое и в другой. Главные отличия могут быть в удобстве, быстроте работы программы и ее возможностях. Например, более ранние версии отказываются открывать документ PDF и DJVU…
3) Документы для сканирования
Да, вот так вот, решил вынести документы отдельной графой. В большинстве случаев сканируют какие-нибудь учебники, газеты, статьи, журналы и пр. Т.е. те книги и ту литературу которая пользуется спросом. Я это к чему веду? Из личного опыта могу сказать, что многое, что вы захотите сканировать — возможно уже есть в сети! Сколько раз лично я экономил время, когда находил ту или иную книгу уже сканированную в сети. Мне оставалось только скопировать текст в документ и продолжить с ним работу.
Из этого простой совет — прежде чем что-то сканировать, проверьте, может уже кто-то отсканировал и вам не нужно терять свое время.
Что такое Гугл Диск и что такое Гугл Документы
Если говорить по-русски, то Google Drive – это Гугл Диск, облако от Гугла. Попробую кратко объяснить, что это такое. Пользователь должен быть зарегистрирован в Гугле. Проще говоря, у пользователя должна быть своя почта в Google. Также можно зарегистрироваться со своей старой почтой, не заводя новую.
Каждый пользователь, который зарегистрирован в Гугле, сразу бесплатно получает доступ к его многочисленным сервисам. Одним из таких сервисов является бесплатное место в облаке (в Гугл Диске) размером 15 Гигабайт.
Другим полезным сервисом, который бесплатно предоставляется пользователю, зарегистрированному в Гугле, являются Гугл Документы (Google Docs). Это текстовый редактор, который работает в режиме онлайн, его не нужно устанавливать на свой компьютер. Он работает в браузере. И при этом документ из Гугл Документов будет доступен с любого устройства, потому что все хранится в облаке.
Гугл Документы очень похожи по функционалу на текстовый редактор Word, но который необходимо устанавливать на свой компьютер. Единственный недостаток Гугл Документов в том, что для работы с ним требуется интернет.








