Что такое robots.txt [основы для новичков]
Содержание:
- Как проверить robots
- Приоритеты агентов пользователей
- Для чего нужна проверка robots.txt
- Последние материалы из раздела «Автотовары»
- Область применения
- Как проводится проверка robots.txt Яндексом
- Синтаксис robots.txt
- Особенности работы с поисковыми ботами
- Правильный Robots.txt для Bitrix
- Проверка robots.txt в Яндекс и Гугл вебмастере
- Практическая реализация заголовка X-Robots-Tag
- Как осуществляется проверка robots.txt в Google
- Добавить с помощью Yoast SEO
- Немного теории перед подключением роутера
- Читайте также:
- Заключение
Как проверить robots
Файл должен находиться по следующему адресу — https://название домена/robots.txt. Документ должен весить меньше 500 Кб. Такой лимит поддерживается обоими поисковиками. Для проверки роботс, используют панели веб-мастеров Гугл и Яндекс. В специальное окошко вводится код и домен.
В Яндекс.Вебмастере это делается так:
- открыть панель;
- кликнуть по вкладке «Инструменты»;

откроется меню, в котором надо выбрать «Анализ robots.txt»;
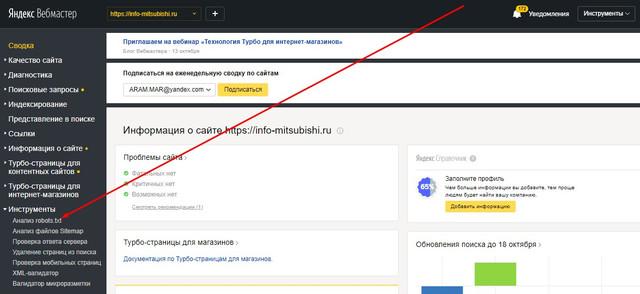
далее ввести код и нажать на кнопку «Проверить».

Эти результаты укажут на отсутствие ошибок и нормальное состояние файла.
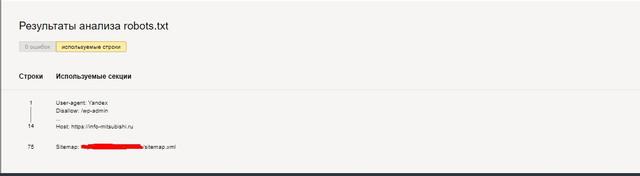
Практически также осуществляется проверка в Google Search Console. Любые синтаксические и логические ошибки подчёркиваются, а их общее количество указывается системой внизу окна редактирования.
Ответы, которые получает поисковый робот при сканировании файла роботс:
- 2хх — удачное сканирование документа;
- 3хх — сигнал к повторной индексации до 5 попыток, дальше засчитывается 404;
- 4хх — положительный ответ к индексированию всей площадки;
- 5хх — сканирование целиком закрыто, ПС оценивается как пауза сервера, поэтому обращения будут регулярными, пока не придёт другой ответ.
Приоритеты агентов пользователей
Для отдельного поискового робота имеет силу только одна группа. Он должен найти ту, в которой наиболее конкретно указан агент пользователя из числа подходящих. Все остальные группы будут пропущены. В обозначении агента пользователя учитывается регистр. Весь неподходящий текст игнорируется. Например, и аналогичны варианту . Порядок групп в файле robots.txt не имеет значения.
Если определенному агенту пользователя соответствует несколько групп, то все относящиеся к нему правила из всех групп объединяются в одну.
Пример 1
Предположим, что имеется следующий файл robots.txt:
user-agent: googlebot-news
(group 1)
user-agent: *
(group 2)
user-agent: googlebot
(group 3)
Сведения о том, какую группу выберут разные поисковые роботы, приведены в таблице ниже.
| Соответствие групп роботам | |
|---|---|
| Googlebot News | Выбирается группа 1, в которой конкретнее всего указан подходящий агент пользователя. Остальные игнорируются. |
| Googlebot (веб-поиск) | Выбирается группа 3. |
| Googlebot Images | Выбирается группа 3, поскольку нет отдельной группы с конкретным указанием элемента . |
| Googlebot News (при сканировании изображений) | Выбирается группа 1, поскольку в данном случае изображения будут сканироваться именно роботом Googlebot News. |
| Otherbot (веб-поиск) | Выбирается группа 2. |
| Otherbot (для новостей) | Выбирается группа 2. Даже если имеется запись для схожего робота, она недействительна без точного соответствия. |
Пример 2
Предположим, что имеется следующий файл robots.txt:
user-agent: googlebot-news
disallow: /fish
user-agent: *
disallow: /carrots
user-agent: googlebot-news
disallow: /shrimp
Поисковые роботы объединят группы, относящиеся к одному агенту пользователя, следующим образом:
user-agent: googlebot-news
disallow: /fish
disallow: /shrimp
user-agent: *
disallow: /carrots
Дополнительная информация приведена в Справочном центре.
Для чего нужна проверка robots.txt
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
- На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
- В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
- Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
- Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
- Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
- Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
- Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
- Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
- Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
Рекомендуемые статьи по данной теме:
- Проверка тИЦ сайта: 3 способа
- Внутренняя оптимизация сайта: пошаговый разбор
- Файл htaccess: применение, включение, настройка
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Оставить заявку
Вас также может заинтересовать: Что делать, если упала посещаемость сайта
Последние материалы из раздела «Автотовары»
Область применения
Рабочая мощность насоса Малыш невелика, поэтому он не может использоваться для добычи воды из глубоких артезианских скважин. Зато отлично работает в колодцах и скважинах «на песок», а также может перекачивать воду из рек и озер, содержащую механические примеси.
Какие задачи можно решить с его помощью:
- Подъем воды с глубины до 40 метров;
- Её закачивание в систему водопровода дома и участка;
- Полив садовых насаждений;
- Откачивание воды из бассейнов, затопленных подвалов и погребов;
- Мойка автомобиля, дорожек и площадок, фасадов зданий и т.д.
Как проводится проверка robots.txt Яндексом
После начала проверки анализатор разбирает каждую строку содержимого поля «Текст robots.txt» и анализирует директивы, которые он содержит. Кроме того, вы узнаете, будет ли робот обходить страницы из поля «Список URL».
Составлять файл robots.txt, подходящий для вашего ресурса, можно редактированием правил. Не забывайте, что сам файл ресурса при этом остается неизменным. Для вступления изменений в силу понадобится самостоятельная загрузка новой версии файла на сайт.
При проверке директив разделов, которые предназначены для робота Яндекса (User-agent: Yandex или User-agent:*), анализатор руководствуется правилами использования robots.txt. Остальные разделы проверяются в соответствии с требованиями стандарта. Когда анализатор разбирает файл, то выводит сообщение о найденных ошибках, предупреждает, если в написании правил есть неточности, перечисляет, какие части файла предназначены для робота Яндекса.
Анализатор может посылать сообщения двух типов: ошибки и предупреждения.
Сообщение об ошибке выводится, если какая-либо строка, секция или весь файл не могут быть обработаны анализатором вследствие наличия серьезных синтаксических ошибок, которые допустили при составлении директив.
В предупреждении, как правило, сообщается об отклонении от правил, исправление которого анализатором невозможно, или о наличии потенциальной проблемы (ее может и не оказаться), причина которой – случайная опечатка или неточное составленные правила.
Сообщение об ошибке «Этот URL не принадлежит вашему домену» говорит о том, что в списке URL содержится адрес одного из зеркал вашего ресурса, к примеру, http://example.com вместо http://www.example.com (формально эти URL различны). Нужно, чтобы подлежащие проверке адреса относились к сайту, файл robots.txt которого анализируется.
Вас также может заинтересовать: Файл htaccess: применение, включение, настройка
Синтаксис robots.txt
Синтаксис файла состоит из обязательных и необязательных директив. Для правильного считывания роботами их нужно прописывать в определённой последовательности: первая директива в каждом разделе — User Agent, далее Disallow, Allow, в конце — главное зеркало и карта сайта.
Несмотря на стандартные правила создания, поисковые боты по-разному считывают информацию из файла. Например, запрет индексации параметров страницы понимает только Yandex, а Googlebot пропустит эту строку.
Важное правило — не допустить ошибки в директивах. Один неверный символ может привести к некорректной индексации.. Чтобы минимизировать риск ошибок, придерживайтесь основных правил составления синтаксиса:
Чтобы минимизировать риск ошибок, придерживайтесь основных правил составления синтаксиса:
- в одной строке прописывается максимум одна директива;
- каждая директива — новая строка;
- в начале строк и между строками не должно быть пробелов;
- в описании параметра не должно быть переносов на другую строку;
- в названии robots.txt и параметрах директив не используются символы верхнего регистра;
- присутствует знак «/» перед каждой директорией. Пример: /products;
- в описании директив могут быть символы только латинского алфавита;
- только один параметр в директивах Allow и Disallow;
- Disallow без описания равнозначно Allow/ — разрешить обход всех страниц;
- Allow без описания то же, что и robots.txt disallow/ — означает запрет индексации всех страниц.
2.1. Основные директивы синтаксиса
- User-agent — обязательная директива, указывается в начальной строке и означает обращение к поисковым ботам. Пример:User-agent: * — для всех поисковиков;
User-agent: Yandex — только Яндекс;
User-agent: Googlebot — только Google. - Disallow — запрет на обход папок, разделов или отдельных страниц сайта. Пример: User-agent: *
Disallow: /page — всем роботам запрещается индексация раздела и всех категорий, которые в него входят. - Allow — индексация всех страниц и их разделов. Пример:User-agent: *
Allow: / — всем роботам разрешается индексация всего сайта. - Noindex — запрет на индексацию части контента на странице. Отличается от Disallow тем, что Noindex используется непосредственно в коде страницы и выглядит так: <meta name=”robots” content=”noindex” />
- Clean-param — запрет на индексацию параметров в адресе страницы. Эта директива видна только Яндекс-боту. Например, с её помощью можно закрыть от индекса UTM-метки:Clean-param: utm_source&utm_medium&utm_campaign /catalog/
- Crawl-Delay — определение минимального периода времени между обходами страниц. Например:User-agent: Yandex
Disallow: /page
Crawl-delay: 2 — после индексации одной страницы пройдёт не менее двух секунд до начала индексации следующей страницы. - Host — указание основного зеркала сайта. Пример:Host: yoursite.com
- Sitemap — расположение карты сайта. Пример:Sitemap: yoursite.com/sitemap
Особенности работы с поисковыми ботами
Чтобы индексация сайта поисковыми роботами происходила быстро и эффективно, необходимо:
Кроме ошибок в robots.txt, медленной скорости загрузки сайта и блокировки в .htaccess, причинами плохой индексации могут быть:
3.1. Высокая нагрузка на сервер при посещениях роботов
Индексация ботами поисковых систем крайне важна для продвижения, однако в некоторых ситуациях она может перегружать сервер, либо под видом роботов сайт могут атаковать хакеры. Чтобы знать цели, с которыми боты обращаются к ресурсу, и отслеживать возможные проблемы, проверяйте логи сервера и динамику серверной нагрузки в панели хостинг-провайдера. Критические значения могут свидетельствовать о проблемах, связанных с активным доступом к сайту поисковых роботов.

Когда роботы перегружают сервер слишком активными запросами к сайту, можно снизить их скорость обхода. Как это сделать, узнайте из справок и .
3.2. Проблемы из-за доступа фейковых ботов к сайту
Бывает, что под видом ботов Google к сайту пытаются получить доступ спамеры или хакеры. Если возникла такая проблема, проверьте, действительно ли сайт сканирует поисковый робот Google:
-
В логах сервера хостинг-провайдера скопируйте IP-адрес, с которого был сделан запрос к сайту.
-
Проверьте данный IP с помощью сервиса MyIp.
-
Затем проверьте адрес, указанный в строке IP Reverse DNS (Host).
Полученный IP-адрес должен совпадать с исходным в логах сервера, иначе это говорит о том, что имя бота поддельное. В данном случае сайт действительно сканировал Googlebot Аналогично проверяются и вызвавшие подозрения боты Яндекса.
Узнайте о других причинах плохой индексации из нашего поста «Почему поисковые роботы и Netpeak Spider не сканируют ваш сайт».
Чтобы узнать, как тот или иной поисковый бот сканирует ваш сайт, воспользуйтесь краулером Netpeak Spider, который позволяет имитировать поведение робота. Для анализа необходимо:
-
Открыть настройки «Продвинутые» и выбрать шаблон «По умолчанию: бот» → он предполагает учёт всех инструкций по сканированию и индексации.
-
Перейти на вкладку «User Agent» и из списка ботов выбрать нужного.
- Начать сканирование и по окончании ознакомиться с полученными данными.
3.3. Список ботов поисковых систем
Поисковые системы используют различные типы роботов: для индексации обычных страниц, новостей, изображений, фавиконов и прочих типов контента. Список IP-адресов, которые используют боты поисковиков, постоянно меняется и не разглашается.
3.2.1. Роботы Google
Полный список роботов Google можно посмотреть в справке. Рассмотрим наиболее популярных ботов:
- Googlebot — к ним относятся краулеры двух типов: для десктопных и мобильных версий стандартных сайтов. С июля 2019 года для новых и адаптированных под мобильные устройства сайтов включено приоритетное сканирование мобильных версий, соответственно большинство запросов будут обрабатывать мобильные боты.
-
Googlebot Images — поисковый робот для индексации изображений. При желании можно запретить индексацию всех картинок на сайте с помощью такой директивы в robots.txt:
User-agent: Googlebot-Image
Disallow: / - Googlebot News — бот, добавляющий материалы в Google Новости.
- Googlebot Video — робот, индексирующий видеоконтент.
- Google Favicon — краулер, собирающий фавиконы сайтов.
- APIs-Google — агент пользователя для отправки PUSH-уведомлений. Такие уведомления используются, чтобы веб-разработчики могли быстро получить информацию о каких-либо изменениях на сайтах без излишней нагрузки серверов Google.
- AdsBot Mobile Web Android, AdsBot Mobile Web, AdsBot — краулеры, проверяющие качество рекламы на различных типах устройств.
3.2.2. Роботы Яндекс
У Яндекса тоже обширный список ботов, который можно детально изучить в Яндекс.Помощи. Расскажу о некоторых из них:
- Основной робот, индексирующий страницы, — YandexBot/3.0. Указания боту можно указывать с помощью директив в robots.txt.
- Бот, скачивающий страницы для проверки их доступности, — YandexAccessibilityBot/3.0. Этот краулер игнорирует команды в файле robots.txt.
- Робот, определяющий зеркала проектов, — YandexBot/3.0; MirrorDetector.
- Бот, индексирующий картинки, — YandexImages/3.0.
- Бот, который скачивает фавиконы сайтов. — YandexFavicons/1.0.
- Краулер, индексирующий мультимедийный контент, — YandexMedia/3.0.
- Бот, собирающий материалы для Яндекс.Новостей, — YandexNews/4.0.
- Краулеры Яндекс.Метрики — YandexMetrika/2.0, YandexMetrika/3.0.
Правильный Robots.txt для Bitrix
Код для Robots, который прописан ниже, является базовым, универсальным для любого сайта на битриксе. В то же время, нужно понимать, что у вашего сайта могут быть свои индивидуальные особенности, и этот файл потребуется скорректировать в вашем конкретном случае.
User-agent: * # правила для всех роботов Disallow: /cgi-bin # папка на хостинге Disallow: /bitrix/ # папка с системными файлами битрикса Disallow: *bitrix_*= # GET-запросы битрикса Disallow: /local/ # папка с системными файлами битрикса Disallow: /*index.php$ # дубли страниц index.php Disallow: /auth/ # авторизация Disallow: *auth= # авторизация Disallow: /personal/ # личный кабинет Disallow: *register= # регистрация Disallow: *forgot_password= # забыли пароль Disallow: *change_password= # изменить пароль Disallow: *login= # логин Disallow: *logout= # выход Disallow: */search/ # поиск Disallow: *action= # действия Disallow: *print= # печать Disallow: *?new=Y # новая страница Disallow: *?edit= # редактирование Disallow: *?preview= # предпросмотр Disallow: *backurl= # трекбеки Disallow: *back_url= # трекбеки Disallow: *back_url_admin= # трекбеки Disallow: *captcha # каптча Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: *?FILTER*= # здесь и ниже различные популярные параметры фильтров Disallow: *?ei= Disallow: *?p= Disallow: *?q= Disallow: *?tags= Disallow: *B_ORDER= Disallow: *BRAND= Disallow: *CLEAR_CACHE= Disallow: *ELEMENT_ID= Disallow: *price_from= Disallow: *price_to= Disallow: *PROPERTY_TYPE= Disallow: *PROPERTY_WIDTH= Disallow: *PROPERTY_HEIGHT= Disallow: *PROPERTY_DIA= Disallow: *PROPERTY_OPENING_COUNT= Disallow: *PROPERTY_SELL_TYPE= Disallow: *PROPERTY_MAIN_TYPE= Disallow: *PROPERTY_PRICE= Disallow: *S_LAST= Disallow: *SECTION_ID= Disallow: *SECTION= Disallow: *SHOWALL= Disallow: *SHOW_ALL= Disallow: *SHOWBY= Disallow: *SORT= Disallow: *SPHRASE_ID= Disallow: *TYPE= Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Disallow: *from= # ссылки с метками from Allow: */upload/ # открываем папку с файлами uploads Allow: /bitrix/*.js # здесь и далее открываем для индексации скрипты Allow: /bitrix/*.css Allow: /local/*.js Allow: /local/*.css Allow: /local/*.jpg Allow: /local/*.jpeg Allow: /local/*.png Allow: /local/*.gif # Укажите один или несколько файлов Sitemap Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS # то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал # Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают. Host: www.site.ru
В примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Проверка robots.txt в Яндекс и Гугл вебмастере
Как я уже упоминал, разные поисковые системы некоторые директивы могут интерпритировать по разному. Поэтому имеет смысл проверять написанный вами файл роботс.тхт в панелях для вебмастеров обоих систем. Как проверять?
- Зайти в инструменты проверки Яндекса и Гугла.
-
Убедиться, что в панель вебмастера загружена версия файла с внесенными вами изменениями. В Яндекс вебмастере загрузить измененный файл можно с помощью показанной на скриншоте иконки:
В Гугл Вебмастере нужно нажать кнопку «Отправить» (справа под списком директив роботса), а затем в открывшемся окне выбрать последний вариант нажатием опять же на кнопку «Отправить»:
-
Набрать список адресов страниц своего сайта (по Урлу в строке), которые должны индексироваться, и вставить их скопом (в Яндексе) или по одному (в Гугле) в расположенную снизу форму. После чего нажать на кнопку «Проверить».
Если возникли нестыковки, то выяснить причины, внести изменения в robots.txt, загрузить обновленный файл в панель вебмастеров и повторить проверку. Все ОК?
Тогда составляйте список страниц, которые не должны индексироваться, и проводите их проверку. При необходимости вносите изменения и проверку повторяйте. Естественно, что проверять следует не все страницы сайта, а ярких представителей своего класса (страницы статей, рубрики, служебные страницы, файлы картинок, файлы шаблона, файлы движка и т.д.)
Причины ошибок выявляемых при проверке файла роботс.тхт
- Файл должен находиться в корне сайта, а не в какой-то папке (это не .htaccess, и его действия распространяются на весь сайт, а не на каталог, в котором его поместили), ибо поисковый робот его там искать не будет.
- Название и расширение файла robots.txt должно быть набрано в нижнем регистре (маленькими) латинскими буквами.
- В названии файла должна быть буква S на конце (не robot.txt, как многие пишут)
- Часто в User-agent вместо звездочки (означает, что этот блок robots.txt адресован всем ботам) оставляют пустое поле. Это не правильно и * в этом случае обязательна
User-agent: * Disallow: /
- В одной директиве Disallow или Allow можно прописывать только одно условие на запрет индексации директории или файла. Так нельзя:
Disallow: /feed/ /tag/ /trackback/
Для каждого условия нужно добавить свое Disallow:
Disallow: /feed/ Disallow: /tag/ Disallow: /trackback/
- Довольно часто путают значения для директив и пишут:
User-agent: / Disallow: Yandex
вместо
User-agent: Yandex Disallow: /
- Порядок следования Disallow (Allow) не важен — главное, чтобы была четкая логическая цепь
- Пустая директива Disallow означает то же, что «Allow: /»
- Нет смысла прописывать директиву sitemap под каждым User-agent, если будете указывать путь до карты сайта (читайте об этом ниже), то делайте это один раз, например, в самом конце.
- Директиву Host лучше писать под отдельным «User-agent: Yandex», чтобы не смущать ботов ее не поддерживающих
Практическая реализация заголовка X-Robots-Tag
Заголовок можно добавить в HTTP-ответы с помощью файлов конфигурации в серверном ПО сайта. Например, на серверах Apache такие настройки хранятся в файлах .HTACCESS и HTTPD.CONF. Преимущество использования заголовка в HTTP-ответах состоит в том, что с его помощью можно задать директивы сканирования на уровне всего сайта. А поддержка регулярных выражений обеспечивает дополнительную гибкость.
Например, чтобы добавить заголовок с директивой в HTTP-ответ для PDF-файлов со всего сайта, включите небольшой фрагмент кода в корневой файл .HTACCESS/HTTPD.CONF (Apache) или CONF (NGINX).
Apache:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
NGINX:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}
Заголовки можно использовать для тех файлов, для которых HTML-метатеги robots недоступны, например для изображений. В приведенном ниже примере директива добавляется для файлов изображений (PNG, JPEG, JPG, GIF) на всём сайте:
Apache:
<Files ~ "\.(png|jpe?g|gif)$"> Header set X-Robots-Tag "noindex" </Files>
NGINX:
location ~* \.(png|jpe?g|gif)$ {
add_header X-Robots-Tag "noindex";
}
Как осуществляется проверка robots.txt в Google
Инструмент Google Search Console позволяет вам провести проверку того, содержится ли в файле robots.txt запрет на сканирование роботом Googlebot определенных URL на вашем ресурсе. К примеру, у вас есть изображение, которое вы не хотите видеть в результатах поисковой выдачи Google по картинкам. С помощью инструмента вы узнаете, имеет ли робот Googlebot-Image доступ к этому изображению.
Для этого следует указать интересующий URL. После этого происходит обработка файла robots.txt инструментом проверки, аналогичная проверка роботом Googlebot. Это дает возможность определить, доступен ли этот адрес.
Процедура проверки:
После выбора вашего ресурса в Google Search Console перейдите к инструменту проверки, который выдаст вам содержание файла robots.txt. Выделенный текст – это ошибки в синтаксисе или логические. Их количество указывается под окном редактирования.
В нижней части страницы интерфейса вы увидите специальное окно, в которое нужно ввести URL.
Справа появится меню, из которого необходимо выбрать робота.
Нажмите на кнопку «Проверить».
Если в результате проверки выводится сообщение с текстом «доступен», это значит, что роботам Google разрешено посещать указанную страницу. Статус «недоступен» говорит о том, что доступ к ней роботам закрыт.
Если нужно, вы можете изменить меню и провести новую проверку
Внимание! Автоматического внесения изменений в файл robots.txt на вашем ресурсе не произойдет. Скопируйте изменения и внесите их в файл robots.txt на вашем веб-сервере
На что нужно обратить внимание:
- Сохранения сделанных в редакторе изменений на веб-сервере не происходит. Понадобится копирование полученного кода и вставки его в файл robots.txt.
- Получить результаты проверки файла robots.txt инструментом могут только агенты пользователя Google и роботы, относящиеся к Google (к примеру, робот Googlebot). При этом гарантии того, что интерпретация содержания вашего файла роботами других поисковых систем будет аналогичной, нет.
Вас также может заинтересовать: Шпаргалка по настройке 301 редиректа
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
 Yoast SEO редактор файлов
Yoast SEO редактор файлов
Если robots есть, то отобразится на странице, если нет есть кнопка “создать”, нажимаем на нее.
 Кнопка создания robots
Кнопка создания robots
Выйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Немного теории перед подключением роутера
Маршрутизатор (он же роутер) – это прибор, имеющий отдельную флэш-память, в которой размещена индивидуальная операционная система. По этой причине при подключении он не будет отображён компьютером в диспетчере устройств.
Беспроводные вай-фай маршрутизаторы от Ростелеком могут функционировать благодаря наличию основного устройства (например, домашнего компьютера). При этом используется специальная SIM-карта от Ростелеком, по которой в соответствии с выбранным и оплаченным тарифом будет передаваться определённый объём интернет-трафика.
Маршрутизатор начинает функционировать только после подключения к питанию (аккумулятору, электросети). Первичная настройка при подключении WiFi роутера Ростелеком к принимающему устройству осуществляется при помощи кабеля. Прежде всего, потребуется убедиться в стабильной работе интернета. Далее можно заняться настройкой беспроводного подключения.
Подключённый к питанию маршрутизатор сразу же начинает осуществлять раздачу собственного сигнала. Даже при отсутствии сетевого кабельного соединения на панели устройства светится вай-фай индикатор. Наименование включённого оборудования отображается в перечне доступных сетей на расположенных в пределах квартиры (дома) мобильных или планшетах.
Однако неправильная настройка или неверное подключение вай-фай роутера Ростелеком могут воспрепятствовать нормальной работе интернета.
Читайте также:
Заключение
Итак, в данной статье мы рассмотрели вопрос, что собой представляет файл robots txt, выяснили, что этот файл является очень важным для сайта. Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Из статьи стало понятно, что новичкам, на первых порах, лучше использовать готовый и правильный robots txt, но надо не забыть заменить в нем в директории Host домен на свой, а также прописать адрес своего блога в картах сайта. Скачать мой файл robots txt можно здесь. Теперь, после исправления, можете использовать файл на своем блоге.
Отдельно по файлу robots txt есть сайт Вы можете зайти на него и узнать более подробную информацию. Надеюсь, у Вас всё получится и блог будет хорошо индексироваться. Удачи Вам!
P.S. Для правильного продвижения блога надо правильно писать о оптимизировать статьи на блоге, тогда на нём будет высокая посещаемость и рейтинги. В этом Вам помогут мои инфопродукты, в которые вложен мой трёхлетний опыт. Можете получить следующие продукты:
- пошаговый алгоритм написания мощных статей для блога;
- платная книга Как написать статью для блога;
- интеллект карта Пошаговый алгоритм создания блога (сайта) для новичков;
- платный видео-курс «Как написать и оптимизировать статью для блога. Продвижение блога статьями«.
Просмотров: 12070








