Копирование текста из pdf-документа
Содержание:
- Что такое оптимизация на Андроид
- 11 неизвестных, но нужных фишек WhatsApp
- Программы для преобразования текста с фото в Word
- Использование функции печати в Проводнике Windows
- С помощью Microsoft Word 2013-2016
- Темы переводов
- Как в PDF выделить текст цветом
- SmallPDF
- Бесплатная программа для конвертации UniPDF
- Извлечение Текста с PDFMiner
- 3. Как вставить PDF в Word как объект
- Способы редактирования PDF
- Экспорт PDF в JSON
- Программа для создания PDF файлов из JPG
- Способы извлечения картинок и файлов PDF
- Извлечение изображений из PDF
- Как перевести фото в PDF используя Средство просмотра фотографий Windows
- Лучшие конвертеры PDF в Word: ТОП-10 для ПК и онлайн
- Через Adobe Reader или Foxit Reader
- Внедрение файла в документ
Что такое оптимизация на Андроид
11 неизвестных, но нужных фишек WhatsApp
Программы для преобразования текста с фото в Word
Перед переносом текста с фото в Word онлайн использование программ имеет некоторые преимущества. Так, наиболее мощные из них могут работать в оффлайн режиме, обладая при этом куда более широкими и гибкими настройками OCR. Кроме того, подобные приложения позволяют работать с документами Word напрямую, вставляя в них распознанный текст прямо из буфера обмена.
ABBYY Screenshot Reader
Пожалуй, самый удобный инструмент, позволяющий сконвертировать нераспознанный текст с фото в Word-документ, обычный текстовый файл или передать в буфер обмена для дальнейшего использования. Программой поддерживается около 200 естественных, специальных и формальных языков, захват может производиться целого экрана (с отсрочкой и без), окна и выделенной области. Пользоваться ABBYY Screenshot Reader очень просто.
Скачать: https://www.abbyy.com/ru/screenshot-reader/
- Запустите приложение и выберите область сканирования и язык распознавания;
- Укажите в окошке-панели, куда нужно передать распознанный текст;
- Нажмите в правой части кнопку запуска операции;
- Используйте полученный текст по назначению.
Readiris Pro
«Понимает» более 100 языков, умеет работать с PDF, DJVU и внешними сканерами, с разными типами графических файлов, в том числе многостраничными. Поддерживает интеграцию с популярными облачными сервисами, коррекцию перспективы страницы, позволяет настраивать форматирование. Посмотрим для примера, как скопировать текст с фото в Word в этой сложной на первый взгляд программе.
Скачать для Windows: https://www.irislink.com/EN-US/c1729/Readiris-17—the-PDF-and-OCR-solution-for-Windows-.aspx
Вариант A:
- Перетащите на окно изображение, после чего будет автоматически произведено распознавание имеющегося на нём текста;
- В меню «Выходной файл» выберите Microsoft Word DOCX и сохраните документ.
Вариант B:
- Кликните правой кнопкой мыши по изображению и выберите в контекстном меню Readiris → Convert to Word;
- Получите готовый файл в исходном каталоге.
Плюсы:
- Функциональна и удобна.
- Интеграция с облачными сервисами.
- Позволяет конвертировать фото в текст Word через меню Проводника.
Минусы:
Платная, не лучшим образом справляется с изображениями с разноцветным фоном.
Microsoft OneNote
Если у вас установлен офисный пакет Microsoft, то среди приложений должна быть программа OneNote — записная книжка с поддержкой распознавания текста из картинок. Приложение также входит в состав всех версий Windows 10. Хорошо, взглянем, как перенести текст в Word с ее помощью.
- Запустите OneNote и перетащите на ее окно изображение с текстом;
- Выделив изображение, нажмите по нему правой кнопкой мыши и выберите в меню Поиск текста в рисунках → Свой язык;
- Вызовите контекстное меню для картинки повторно и на этот раз выберите в нём опцию «Копировать текст из рисунка»;
- Вставьте из буфера обмена распознанный текст из рисунка в Word или другой редактор.
Плюсы:
- Высокое качество распознавания текста даже на цветном фоне.
- Работа в автономном режиме.
- Бесплатна.
Минусы:
- Не столь удобна, как две предыдущие программы.
- Текст вставляется в Word-документ только через буфер.
- Мало доступных языков (русский есть).
Использование функции печати в Проводнике Windows
В Проводнике Windows можно использовать функцию печати для известных операционной системе графических файлов.
Использовать Проводник для сохранения фотографий в PDF очень просто:
- Откройте любую папку на компьютере, в которой находятся изображения, например, Рабочий стол. Выделите одну или несколько фотографий.
- После клика правой кнопкой мыши по фотографии, картинке или изображению, в контекстном меню Проводника появится пункт «Печать», на который нужно нажать.
- В окне «Печать изображений» выберите виртуальный принтер, другие параметры печати.
- Нажмите на кнопку «Печать».
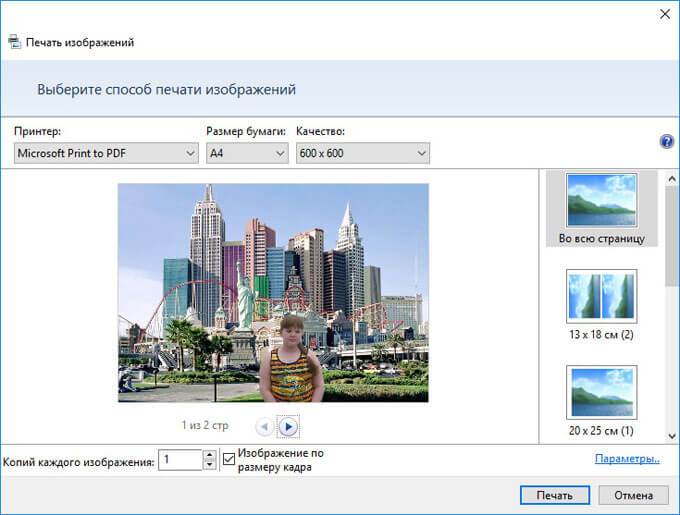
В открывшемся окне выберите название для файла, место для сохранения, нажмите «Сохранить».
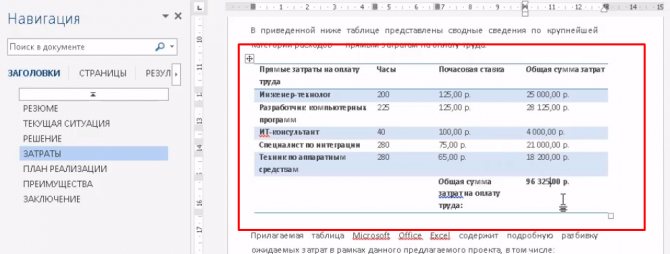
С помощью Microsoft Word 2013-2016
В последних версиях Microsoft Office приложение Word имеет встроенный инструмент для конвертирования pdf. Нужно просто открыть файл в этой программе, а дальше система сделает все сама.
1. Нажимаем на кнопку «ФАЙЛ» в левом верхнем углу окна.
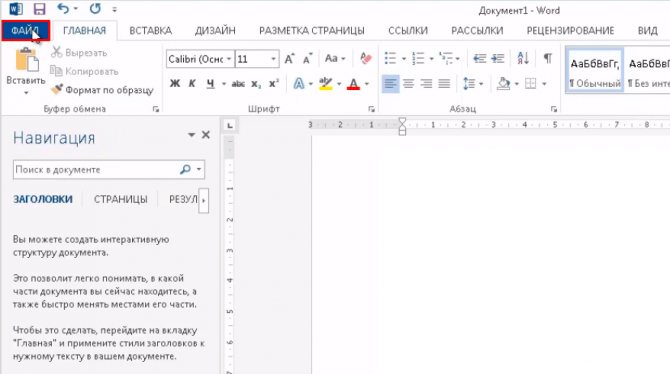
2. Идем по пути Открыть → Компьютер и выбираем папку, где находится наш файл.
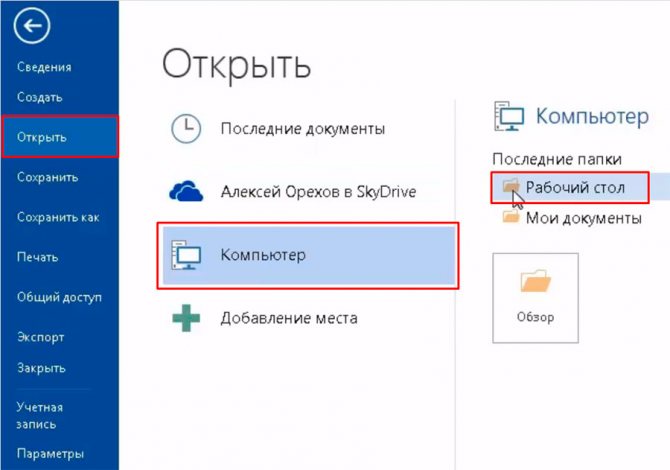
3. Выбираем документ и жмем кнопку «Открыть».
Появится окно с предупреждением, которое можно не читать и сразу жать кнопку «ОК».
Вот и всё! Теперь документ можно редактировать и сохранить в обычном формате doc или docx.
Правда, разрывы страниц расположены не в тех местах, что в исходном файле, но это как-нибудь можно пережить. Главное, все таблицы и списки доступны для редактирования.
Темы переводов
Пожалуйста, о темы переводов.
Технический перевод
Юридический перевод
Финансовый перевод
Перевод рекламных и маркетинговых текстов
Переводы для пищевой промышленности
Сельское хозяйство
Переводы для строительства и недвижимости
Информационные технологии
Электротехника
Геология и горнодобывающая промышленность
Нефть и нефтепереработка
Логистика и перевозки
Машиностроение
Металлургия и металлообработка
Легкая промышленность и текстиль
Физика
Математика
Химия и химическая промышленность
Медицинский перевод
Художественный перевод
История и география
Философия и психология
Поэзия
| Введите код с картинки: |
Как в PDF выделить текст цветом
Для использования заливки следует:
Перейти на вкладку «Инструменты» и выбрать пункт «Добавить комментарий».

Появится панель с инструментами: заливка, подчеркивание, вычеркивание, рисование.

Выделение текста цветом – второй значок слева (в виде маркера). Кликнуть по нему. Значок станет желтым, а справа на панели инструментов отобразится выбор цвета (также непрозрачности) и толщины линии.

После выбора цвета левой кнопкой мышки выделить нужную фразу слева направо или дважды клацнуть по конкретному слову.

Чтобы подчеркнуть или зачеркнуть слово, нужно выделить его и клацнуть по иконке в виде буквы «Т».

Опция доступна в бесплатной версии программы Adobe Acrobat Reader DC.
SmallPDF
Веб-сервис SmallPDF, понравился мне больше, чем предыдущий. Та же самая схема была обработана примерно в 2 раза быстрее и загрузилась обратно в считанные секунды. Структура документа, как и в первом случае, сохранилась неизменной, но искажений в нем стало меньше.
Перейти на Smallpdf
Пользоваться SmallPDF тоже очень просто:

- Загружаем или перетаскиваем на выделенное поле ПДФ-файл. Кстати, сервис поддерживает загрузку документов из Dropbox и Google Drive.
- Нажимаем «Конвертировать».
- Скачиваем результат на компьютер либо сохраняем его в своем Dropbox или Google Drive.
Из недостатков SmallPDF стоит отметить лишь два. Первый – это ограничение бесплатной версии двумя загрузками в час (безлимитное использование по подписке стоит $4-6 в месяц). Второй – сохранение результата только в формате DOCX.
Бесплатная программа для конвертации UniPDF
В закромах англоязычного интернета можно обнаружить надежную качественную программу UniPDF, предназначенную для конвертации различных текстовых форматов.
Выбираем любой сервер из списка.

Ждем пока программа скачается, благо она весит немного, и этот процесс происходит практически моментально.
После загрузки открываем файл и устанавливаем программу. Для этого нажимаем Next → I Agree → Next → Install → Finish. На Рабочем столе или в Пуск → Все программы → UniPDF появится ярлык, через который запускаем приложение.
Жмем кнопку «Добавить» внизу.

Выбираем нужный файл через окошко, щелкаем по нему внутри программы и жмем кнопку «Конвертировать».
Обратите внимание, что в правом углу должна стоять о

Далее, нам предлагают выбрать место на компьютере, куда отправится новый файл. Можно просто нажать «ОК» и тогда он сохранится туда же, где лежит исходный документ.
И ждем окончания процесса, после чего программа предложит открыть результат или показать папку, где он находится.

Программа со своей задачей обычно справляется плюс «вытягивает» картинки, но с форматированием бывают проблемы.
Извлечение Текста с PDFMiner
Наверное, самым известным является пакет PDFMiner. Данный пакет существует, начиная с версии Python 2.4. Его изначальная задача заключалась в извлечение текста из PDF. В целом, PDFMiner может указать вам точное расположение текста на странице, а также родительскую информацию о шрифтах. Для версий Python 2.4 – 2.7, вы можете ссылаться на следующие сайты с дополнительной информацией о PDFMiner:
- Github – https://github.com/euske/pdfminer
- PyPI – https://pypi.python.org/pypi/pdfminer/
- Webpage – https://euske.github.io/pdfminer/
PDFMiner не совместим с Python 3. К счастью, существует вилка для PDFMiner под названием PDFMiner.six, которая работает аналогичным образом. Вы можете найти её здесь: https://github.com/pdfminer/pdfminer.six
Инструкции по установке PDFMiner как минимум можно назвать устаревшими. Вы можете использовать pip для проведения установки:
Shell
python -m pip install pdfminer
| 1 | python-mpip install pdfminer |
Если вам нужно установить PDFMiner в Python 3 (что вы, скорее всего, и пытаетесь сделать), то вам нужно провести установку следующим образом:
Shell
python -m pip install pdfminer.six
| 1 | python-mpip install pdfminer.six |
Документация PDFMiner достаточно скудная. По большей части вам понадобится гугл и StackOverflow, чтобы понять, как использовать PDFMiner эффективнее в случаях, не описанных в данной статье.
3. Как вставить PDF в Word как объект
Вы можете вставить свой PDF в Word как объект. Это означает, что вы можете легко получить доступ к PDF из вашего документа Word. Кроме того, в зависимости от выбранных параметров PDF-файл может обновляться автоматически.
Для этого откройте Word и перейдите на вкладку « Вставка » на ленте. В разделе « Текст » нажмите « Объект» .
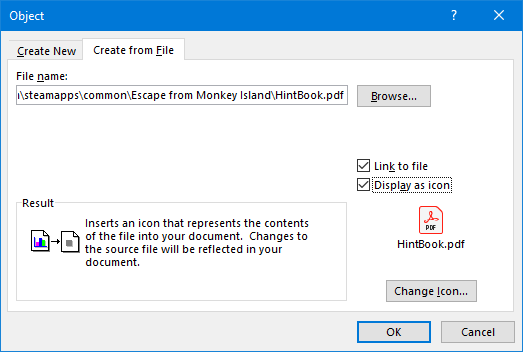
В открывшемся окне перейдите на вкладку « Создать из файла ». Нажмите Обзор … , найдите и выберите свой PDF, затем нажмите Вставить .
На данный момент, вы можете просто нажать кнопку ОК . Это вставит статический захват первой страницы PDF в документ Word. Если дважды щелкнуть этот скан, откроется PDF-файл.
Кроме того, вы можете выбрать ссылку на файл . Хотя при этом по-прежнему вставляется только первая страница PDF, любые изменения, которые происходят в этом PDF, будут автоматически отражаться в документе Word.
Если вы не хотите видеть первую страницу, выберите View as Icon . По умолчанию будет отображаться значок Adobe PDF и название вашего PDF. Вы можете нажать Изменить значок …, если вы хотите отобразить другой значок.
Способы редактирования PDF
В зависимости от расположения изображений в файле, существует несколько способов их копирования.
Способ 1: Использование утилиты Adobe Reader
Если изображение – отдельный фрагмент документа, то процесс извлечения выполнить будет значительно проще, чем при любых других вариантах. В этой программе есть множество полезных функций, позволяющих работать с файлами PDF формата. Давайте воспользуемся инструментом «Копирование».
- Запускаем нужный файл и выбираем необходимое изображение.
- При нажатии картинка выделится как отдельный фрагмент. Вызываем всплывающее меню, используя ПКМ и жмем «Копировать изображение».
- Картинка сохранится в буфере обмена и при необходимости теперь ее можно вставить в любой документ. Давайте рассмотрим на примере программы «Paint».
- Открыв чистый файл, нажимаем на кнопку «Вставить».
- Изображение появится в рабочей области и будет доступно для внесения графических правок.
- В левом верхнем углу экрана находим вкладку «Сохранить как». Здесь же можно будет установить необходимое вам разрешение файла и указать его название.
- Подтверждаем предыдущие действия, нажав «Сохранить».
Этот вариант подходит в том случае, если необходимое вам изображение – отдельный фрагмент текста. Более сложная ситуация возникает тогда, когда все страницы документа являются картинками и необходимо использование специальной функции программы – «Сделать снимок».
- В верней части документа находим вкладку «Редактирование», нажав на которую выскочит меню.
- Выбираем «Сделать снимок».
- Курсором выделяем область в которой находится изображение.
- Появится окно с текстом «Выделенная область скопирована».
- Нажимаем «ОК».
- Картинка теперь находится в буфере обмена и для дальнейшей работы останется только сохранить ее в необходимом редакторе.
Способ 2: Воспользоваться программой PDFMAte
Использование этой утилиты имеет смысл только в том случае, если картинка является отдельной частью документа. Во втором варианте эта программа не задействуется.
- Активировав программу, найдите кнопку «Добавить PDF» и выберите необходимый документ.
- В настройках утилиты перейдите на вкладку «Image» и поставьте галочку напротив надписи «Извлекать только изображение».
- Перейдите в окно «Формат вывода», выберите «Image» и запустите процесс, нажав на кнопку «Создать».
- После окончания загрузки вы сможете открыть папку с сохраненными изображениями, которые были копированы из документа.
Способ 3: С помощью PDF Image Extraction Wizard
Эта программа обладает десятками полезных функций, но самое главное, она предназначена в основном для копирования изображений из документов PDF. К сожалению, все версии этой утилиты являются платными.
- Запускаем программу и заполняем необходимые поля.
- В первой графе «PDF file» указывает путь к нужному документу.
- Во втором пункте «Output folder», выбираем папку в которую будут сохраняться изображения.
- В поле «Base name for…» пишем название для картинки.
- Жмем «Next».
- Если документ слишком большой, можно указать интервал на котором находятся нужные изображения. Это значительно ускорит всю процедуру.
- Бывает, что файлы имеют защиту. В таком случае нужно будет ввести пароль.
- В появившемся окне ставим галочку напротив строки «Extract Image» и переходим к следующему шагу.
- В новой открывшейся странице задаем размер картинок и при необходимости используем другие настройки.
- Указываем формат, в котором нужно сохранить изображения и подтверждаем правильность заполнения всех параметров.
- Для запуска процедуры, нажимаем «Start».
- По завершению загрузки будет предложена возможность перейти в папку с сохраненными картинками.
Способ 4: Использование стандартных возможностей компьютера
Помимо установки дополнительных программ есть возможность воспользоваться стандартными инструментами, доступными на любом ПК.
Первый пример, который будем рассматривать – скриншот.
- Открываем PDF файл.
- Находим необходимое изображение и копируем его в буфер обмена, нажав клавишу PrtSc.
- Открываем полученный снимок в любом графическом редакторе и обрезаем ненужные фрагменты.
- Сохраняем полученный результат.
Кроме возможности сделать скриншот, существует инструмент «Ножницы», использовав который можно вырезать из файла необходимый фрагмент.
- В меню «Пуск» находим вкладку «Стандартные» и выбираем инструмент «Ножницы».
- В нужном документе выделяем изображение с помощью курсора.
- Откроется окно с вырезанной картинкой. Ее можно сохранить сразу или копировать для последующей вставки в редактор.
Воспользовавшись способами, описанными в этой статье, вы сможете извлечь изображение из привередливого файла в формате PDF.
Экспорт PDF в JSON
JavaScript Object Notation, или JSON, представляет собой простой формат обмены данными, который легко читать и писать. Python содержит модуль json в своей стандартной библиотеки, который позволяет вам программно читать и писать в JSON. Давайте посмотрим, что мы усвоили из предыдущего раздела и используем это для создания скрипта экспорта, который выдает JSON вместо XML:
json_exporter.py
Python
# json_exporter.py
import json
import os
from miner_text_generator import extract_text_by_page
def export_as_json(pdf_path, json_path):
filename = os.path.splitext(os.path.basename(pdf_path))
data = {‘Filename’: filename}
data = []
counter = 1
for page in extract_text_by_page(pdf_path):
text = page
page = {‘Page_{}’.format(counter): text}
data.append(page)
counter += 1
with open(json_path, ‘w’) as fh:
json.dump(data, fh)
if __name__ == ‘__main__’:
pdf_path = ‘w9.pdf’
json_path = ‘w9.json’
export_as_json(pdf_path, json_path)
|
1 |
# json_exporter.py importjson importos fromminer_text_generator importextract_text_by_page defexport_as_json(pdf_path,json_path) filename=os.path.splitext(os.path.basename(pdf_path)) data={‘Filename’filename} data’Pages’= counter=1 forpage inextract_text_by_page(pdf_path) text=page100 page={‘Page_{}’.format(counter)text} data’Pages’.append(page) counter+=1 withopen(json_path,’w’)asfh json.dump(data,fh) if__name__==’__main__’ pdf_path=’w9.pdf’ json_path=’w9.json’ export_as_json(pdf_path,json_path) |
Здесь мы импортируем различные библиотеки, которые нам могут понадобиться, включая модуль PDFMiner. Далее, мы создаем функцию, которая принимает путь ввода PDF и путь выдачи JSON. JSON – это, фактически, словарь в Python, так что мы создаем несколько простых ключей высшего уровня: Filename и Pages. Ключ Pages сопоставляется с пустым списком. Далее, мы вводим цикл над каждой страницей PDF и извлекаем первые 100 символов каждой страницы. Далее, мы создаем словарь с номером страницы в качестве ключа и 100 символов в качестве значение и добавим в список верхнего уровня Page. Наконец, мы записываем файл при помощи команды модуля json под названием dump.
Содержимое файла должно выглядеть следующим образом:
|
1 |
{‘Filename»w9’, ‘Pages'{‘Page_1»Form W-9(Rev. November 2017)Department of the Treasury Internal Revenue Service Request for Taxp’}, {‘Page_2»Form W-9 (Rev. 11-2017)Page 2 By signing the filled-out form, you: 1. Certify that the TIN you are g’}, {‘Page_3»Form W-9 (Rev. 11-2017)Page 3 Criminal penalty for falsifying information. Willfully falsifying cert’}, {‘Page_4»Form W-9 (Rev. 11-2017)Page 4 The following chart shows types of payments that may be exempt from ba’}, {‘Page_5»Form W-9 (Rev. 11-2017)Page 5 1. Interest, dividend, and barter exchange accounts opened before 1984’}, {‘Page_6»Form W-9 (Rev. 11-2017)Page 6 The IRS does not initiate contacts with taxpayers via emails. Also, th’}} |
И снова мы получили отличную выдачу, которую легко читать. Вы можете улучшить этот пример с метадатой PDF в том числе, если захотите
Обратите внимание на то, что выдача меняется в зависимости от того, что вам нужно пропарсить в каждой странице или документе
Давайте посмотрим, как мы можем проводить экспорт в CSV.
Программа для создания PDF файлов из JPG
Программа не требует установки и готова к работе сразу после скачивания. Для того чтобы начать нажмите на кнопку «Add Files» и добавьте JPG файлы.
После добавления картинок из нужно разместить в правильном порядке. Для этого используйте кнопки «Move Sel Up» и «Move Sel Down» для того, чтобы перемещать выделенное изображение вверх или вниз.
После этого нужно выбрать формат, указать название файла, папку для сохранения и нажать на кнопку «Save Output».
В результате вы получите PDF файл с загруженными в программу JPG картинками. При необходимости можно поиграть с остальными настройками, которые доступны в программе. Например, программа позволяет настроить размер листа или добавить отступы по бокам.
Способы извлечения картинок и файлов PDF
Чтобы в итоге получить готовую картинку из PDF-файла, можно пойти несколькими путями – тут всё зависит от особенностей её размещения в документе.
Способ 1: Adobe Reader
В программе Adobe Acrobat Reader есть несколько инструментов, позволяющих извлечь рисунок из документа с расширением PDF. Проще всего использовать «Копирование».
- Откройте PDF и найдите нужное изображение.
- Кликните по нему левой кнопкой, чтобы появилось выделение. Затем – правой кнопкой, чтобы открылось контекстное меню, где нужно нажать «Копировать изображение».
Теперь этот рисунок находится в буфере обмена. Его можно вставить в любой графический редактор и сохранить в нужном формате. В качестве примера возьмём Paint. Для вставки используйте сочетание клавиш Ctrl+V или соответствующую кнопку.
При необходимости отредактируйте картинку. Когда всё будет готово, откройте меню, наведите курсор на «Сохранить как» и выберите подходящий формат для изображения.
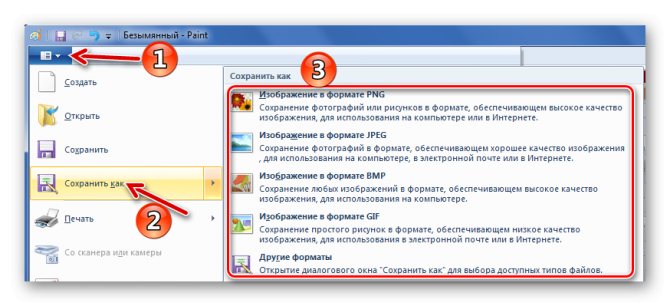
Задайте название рисунка, выберите директорию и нажмите «Сохранить».
Теперь изображение из документа PDF доступно к использованию. При этом его качество не потерялось.
Но как быть, если страницы PDF-файла сделаны из картинок? Для извлечения отдельного рисунка можно воспользоваться встроенным инструментом Adobe Reader для снимка определённой области.
Подробнее: Как сделать PDF из картинок
- Откройте вкладку «Редактирование» и выберите «Сделать снимок».
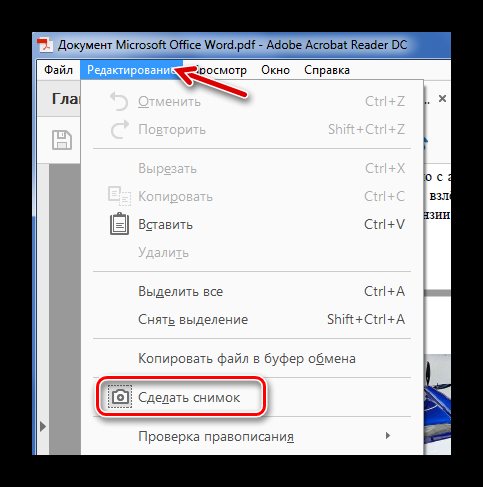
Выделите нужный рисунок.

После этого произойдёт копирование выделенной области в буфер обмена. В подтверждение появится соответствующее сообщение.
Осталось вставить изображение в графический редактор и сохранить на компьютере.
Способ 2: PDFMate
Для извлечения картинок из PDF можно воспользоваться специальными программами. Таковой является PDFMate. Опять-таки, с документом, который сделан из рисунков, такой способ не сработает.
Загрузить программу PDFMate
- Нажмите «Добавить PDF» и выберите документ.
Перейдите в настройки.
Выберите блок «Image» и поставьте маркер напротив пункта «Извлекать только изображения». Нажмите «ОК».
Теперь о в блоке «Формат вывода» и нажмите кнопку «Создать».
По окончанию процедуры статус открытого файла станет «Успешно завершено».
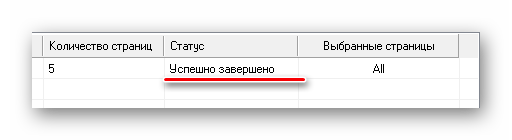
Осталось открыть папку сохранения и просмотреть все извлечённые картинки.
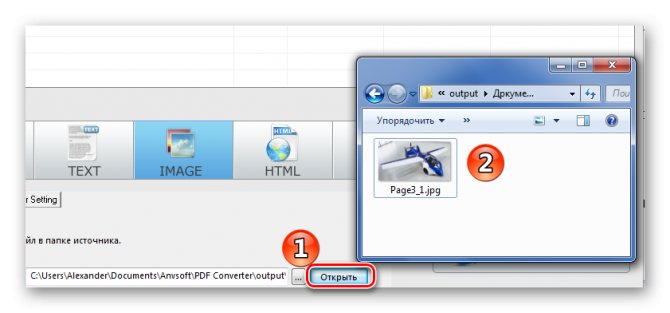
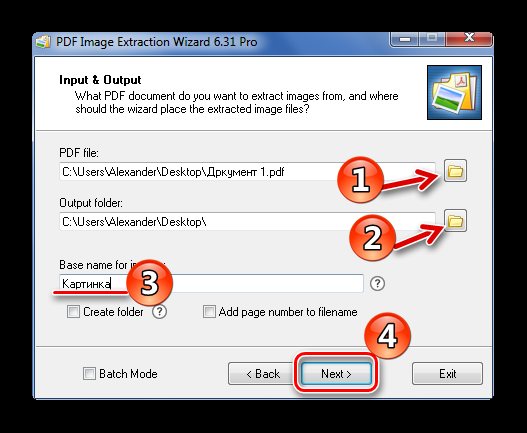
Способ 3: PDF Image Extraction Wizard
Основная функция этой программы – непосредственно извлечение рисунков из PDF. Но минус в том, что она платная.
Загрузить программу PDF Image Extraction Wizard
- В первом поле укажите PDF-файл.
- Во втором – папку для сохранения картинок.
- В третьем – имя для изображений.
- Нажмите кнопку «Next».
Для ускорения процесса можно указать промежуток страниц, где находятся рисунки.Если документ защищён, введите пароль.Нажмите «Next».
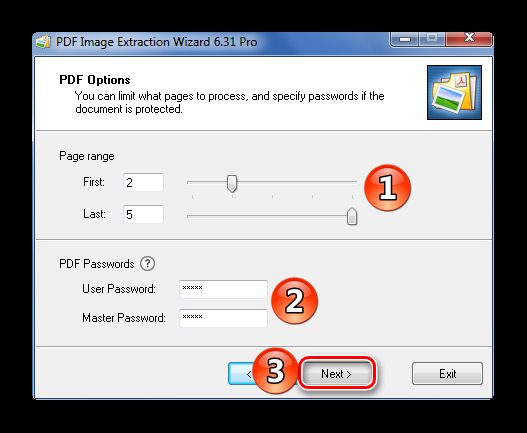
О и нажмите «Next».
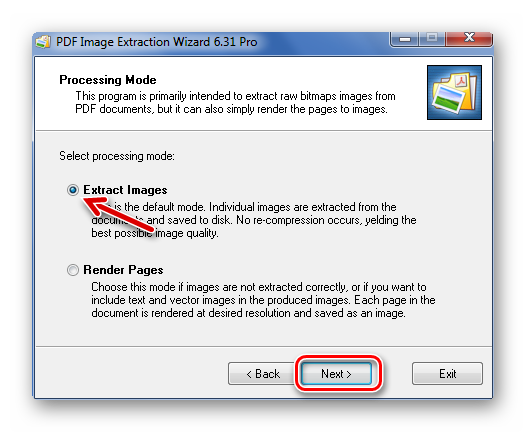
В следующем окне можно задать параметры самих изображений. Здесь можно объединить все изображения, развернуть или перевернуть, настроить извлечение только маленьких или больших рисунков, а также пропуск дубликатов.
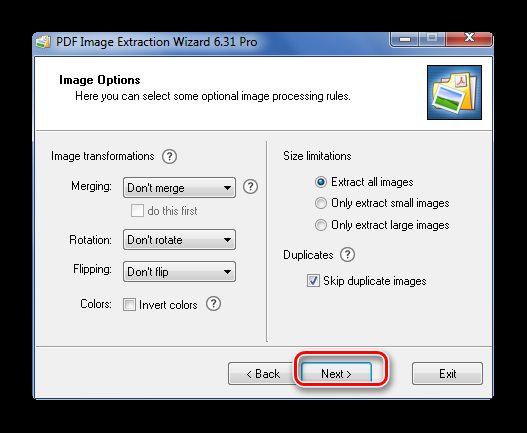
Теперь укажите формат картинок.
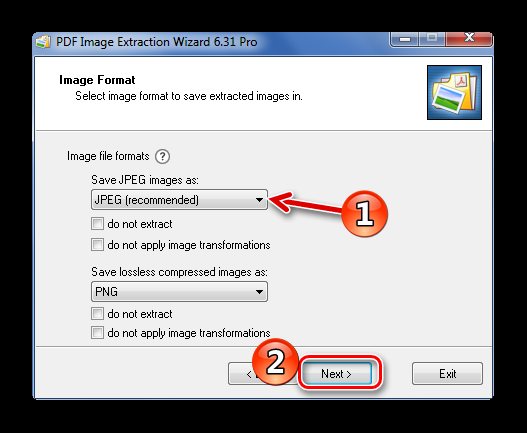
Осталось нажать «Start».
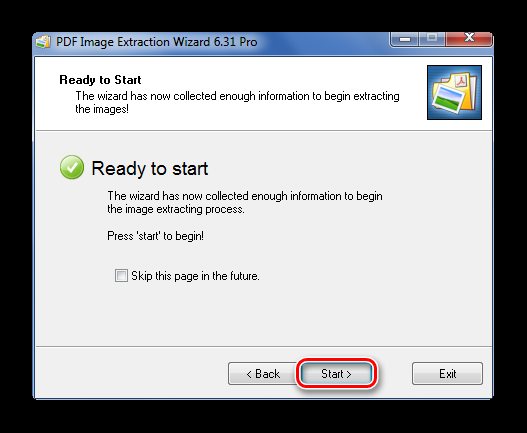
Когда все изображения извлекутся, появится окно с надписью «Finished!». Там же будет ссылка для перехода в папку с этими рисунками.
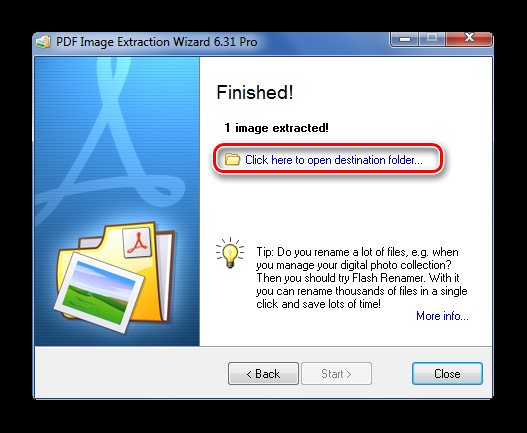
Способ 4: Создание скриншота или инструмент «Ножницы»
Для извлечения картинки из PDF могут быть полезны и стандартные средства Windows.
Начнём со скриншота.
- Откройте PDF-файл в любой программе, где это возможно.
Подробнее: Как открыть PDF
Пролистайте документ до нужного места и нажмите кнопку PrtSc на клавиатуре.Весь снимок экрана будет в буфере обмена. Вставьте его в графический редактор и обрежьте лишнее, чтобы остался только нужный рисунок.
Сохраните результат
С помощью «Ножниц» можно сразу выделить нужный участок в PDF.
- Найдите картинку в документе.
- В списке приложений откройте папку «Стандартные» и запустите «Ножницы».
С помощью курсора выделите изображение.

После этого в отдельном окне появится Ваш рисунок. Его можно сразу сохранить.
Или скопировать в буфер для дальнейшей вставки и редактирования в графическом редакторе.
Подробнее: Программы для создания скриншотов
Таким образом, вытащить картинки из PDF-файла не составит труда, даже если он сделан из изображений и защищён. Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Извлечение изображений из PDF
К сожалению, не существует пакетов Python, которые выполняют извлечение изображений из PDF. Наиболее близкий проект, который я нашел – это minecart, который может делать это, но он работает только на Python 2.7. У меня не вышло его запустить при работе с примером PDF, который у меня был. Однако есть способ, который позволяет извлекать JPG из PDF. Вот пример кода:
Python
# Извлечение jpg из pdf. Быстро и дерзко:
import sys
pdf = file(sys.argv, «rb»).read()
startmark = «\xff\xd8»
startfix = 0
endmark = «\xff\xd9»
endfix = 2
i = 0
njpg = 0
while True:
istream = pdf.find(«stream», i)
if istream < 0:
break
istart = pdf.find(startmark, istream, istream+20)
if istart < 0:
i = istream+20
continue
iend = pdf.find(«endstream», istart)
if iend < 0:
raise Exception(«Didn’t find end of stream!»)
iend = pdf.find(endmark, iend-20)
if iend < 0:
raise Exception(«Didn’t find end of JPG!»)
istart += startfix
iend += endfix
print(«JPG %d from %d to %d» % (njpg, istart, iend))
jpg = pdf
jpgfile = file(«jpg%d.jpg» % njpg, «wb»)
jpgfile.write(jpg)
jpgfile.close()
njpg += 1
i = iend
|
1 |
# Извлечение jpg из pdf. Быстро и дерзко: importsys pdf=file(sys.argv1,»rb»).read() startmark=»\xff\xd8″ startfix= endmark=»\xff\xd9″ endfix=2 i= njpg= whileTrue istream=pdf.find(«stream»,i) ifistream< break istart=pdf.find(startmark,istream,istream+20) ifistart< i=istream+20 continue iend=pdf.find(«endstream»,istart) ifiend< raiseException(«Didn’t find end of stream!») iend=pdf.find(endmark,iend-20) ifiend< raiseException(«Didn’t find end of JPG!») istart+=startfix iend+=endfix print(«JPG %d from %d to %d»%(njpg,istart,iend)) jpg=pdfistartiend jpgfile=file(«jpg%d.jpg»%njpg,»wb») jpgfile.write(jpg) jpgfile.close() njpg+=1 i=iend |
Это также работает для тех файлов PDF, которые я использую. В StackOverflow есть вариации этого кода, некоторые из которых используют PyPDF2 различными способами. Однако в моем случае они не помогли.
Я рекомендую использовать инструмент Poppler для извлечения изображений. Poppler включает в себя инструмент под названием pdfimages, который вы можете использовать с модулем Python под названием subprocess. Вот как использовать его без Python:
Shell
pdfimages -all reportlab-sample.pdf images/prefix-jpg
| 1 | pdfimages-all reportlab-sample.pdfimagesprefix-jpg |
Убедитесь в том, что папка с изображениями (или папку любой другой выдачи, которую вы хотите создать) уже создана, так как pdfimages не сделает это за вас.
Давайте напишем скрипт Python, который выполняет эту команду, и убедимся, что папка выдачи также существует:
image_exporter.py
Python
# image_exporter.py
import os
import subprocess
def image_exporter(pdf_path, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cmd = [‘pdfimages’, ‘-all’, pdf_path,
‘{}/prefix’.format(output_dir)]
subprocess.call(cmd)
print(‘Images extracted:’)
print(os.listdir(output_dir))
if __name__ == ‘__main__’:
pdf_path = ‘reportlab-sample.pdf’
image_exporter(pdf_path, output_dir=’images’)
|
1 |
# image_exporter.py importos importsubprocess defimage_exporter(pdf_path,output_dir) ifnotos.path.exists(output_dir) os.makedirs(output_dir) cmd=’pdfimages’,’-all’,pdf_path, ‘{}/prefix’.format(output_dir) subprocess.call(cmd) print(‘Images extracted:’) print(os.listdir(output_dir)) if__name__==’__main__’ pdf_path=’reportlab-sample.pdf’ image_exporter(pdf_path,output_dir=’images’) |
В этом примере мы импортировали модули subprocess и os. Если папка выдачи не существует, мы попытаемся создать её. Далее мы используем метод вызова subprocess для запуска pdfimages. Мы используем вызов, так как он будет ожидать pdfimages, пока тот закончит работу. Вы можете использовать Popen вместо этого, но это фактически запускает процесс в фоновом режиме. Наконец, мы выводим список папки выдачи для подтверждения того, что изображения были добавлены в неё.
Есть статьи, которые ссылаются на библиотеку под названием Wand, которую вы тоже можете попробовать. Это оболочка ImageMagick
Также обратите внимание на то, что существует связка Python с Poppler под названием pypoppler, однако я не нашел примеров того, что этот пакет выполняет извлечение изображений
Как перевести фото в PDF используя Средство просмотра фотографий Windows
Просмотр фотографий Windows — встроенное средство просмотра фотографий в операционной системе Windows до появления Windows 10. Пользователи могут вернуть прежнее Средство просмотра фотографий Windows на свой компьютер в операционной системе Windows 10. Подробнее об этом читайте здесь.
Для сохранения изображения в PDF формате будет использован виртуальный принтер. На своем компьютере я использую Microsoft Print to PDF. В другой операционной системе Windows (Windows 8.1, Windows 8, Windows 7, Windows Vista, Windows XP) воспользуйтесь сторонним виртуальным принтером, например, doPDF, CutePDF Writer, Bullzip PDF Printer .
В приложении Просмотр Фотографий Windows проделайте последовательные действия:
- Откройте фотографию в программе Просмотр фотографий Windows.
- В меню «Печать» нажмите на «Печать».
- В окне «Печать изображений» нужно выбрать способ печати: принтер (в Windows 10 я выбрал виртуальный принтер Microsoft Print to PDF), размер, качество, количество копий, другие параметры.
- Нажмите на кнопку «Печать».
Откроется окно «Сохранение результата печати», в котором присвойте имя файлу, выберите папку для сохранения PDF, нажмите на «Сохранить».
Лучшие конвертеры PDF в Word: ТОП-10 для ПК и онлайн
Вот список ТОП-5 решений, которые нужно установить на компьютер для того, чтобы использовать. Это десктоп версии приложений.
№1. WPS to Word Converter
Это один из самых популярных инструментов в MS Office. Он может легко изменить значение в редактируемые DOC без регистрации, необходимой для немедленного преобразования.
Всего два шага и можно начинать:
- Запустите софт и добавьте file, который вы хотите видоизменить.
- Нажмите «Convert», чтобы продолжить.
Для экономии времени он обеспечивает пакетное видоизменение, включая и .rtf. Вы можете свободно видоизменить менее 5 страниц с помощью этого инструмента. Но если исходник больше 5 страниц, то может потребоваться ввести лицензионный ключ для использования полной версии софта.
№2. Unipdf
Это преобразователь не только в .docx, но также и в изображение, текст и HTML. Это абсолютно свободное ПО, вне зависимости от того, сколько страниц будет использоваться. Нужно просто добавить дистрибутив в программу, и редактируемый ВОРД станет доступен.
Здесь есть два формата для видоизменения в текст: «.rtf» и «.doc», так что вы можете просто указать нужный перед работой. Что касается параметров изображения, то включены почти все известные – JPG, BMP, GIF и PNG и т.д. Вы должны установить вид изображения, а затем начать преобразование. По умолчанию указан JPG.
№3. Nitro PDF Converter
Существует две вариации этого софта: настольное приложение для Windows и онлайн-версия. Только вебсайт может быть доступен для постоянного использования бесплатно. Десктопное ПО предоставит для тестирования 14 дней. Nitro может поменять в Doc, Excel или PowerPoint.
Если вы используете вебсайт, то вам понадобится реальный адрес электронной почты, потому что конвертированные доки будут отправлены прямо в письме. Но если используется настольное приложение, то оно станет действовать точно так же, как и другие продукты, а именно – сохранять дистрибутивы в память устройства.
Это полноценный инструмент для преобразования без ограничений. Совместимо с Windows, MacOS, iOS, Android. Отлично подходит для “Portable Document Format” с большим количеством изображений. Поддерживает несколько типов расширений. Имеет защиту для созданных доков. С помощью этого свободного компилятора в ВОРД можно создавать, видоизменять, редактировать и даже подписывать итоговые продукты.
Особенность этого ПО заключается в способности конвертировать в ВОРД или другие файлы, в то же время будучи удобным, но и не слишком сложным решением. Разработчикам удалось создать профессиональное многофункциональное приложение, которое конвертирует в Excel, EPUB, PPT, Pages, HTML, RTF и прочие текстовые параметры, не влияя на простой пользовательский интерфейс. Наряду с простотой дизайна программы здесь также позволительно аннотировать дистрибутивы, добавлять текст, экспортировать данные, создавать формы, интегрировать шифрование паролей и ограничения на основе доступов юзеров.
№5. TalkHelper Converter
Еще один интересный app для Windows, которые рекомендуют многие авторитетные издательства. Здесь реализовано множество опций, которые позволяют выполнить работу быстро и без сложностей.
В данном релизе представлено ограниченное количество OCR (систем для распознавания текста), что выгодно выделяет это ПО на фоне многих других.
Через Adobe Reader или Foxit Reader
Если у вас старая версия MS Word, но зато есть программа Adobe Acrobat Reader или Foxit Reader (в одной из них обычно и открываются все pdf файлы), тогда конвертировать можно с помощью нее.
1. Открываем файл в Adobe Reader или Foxit Reader и копируем нужный фрагмент документа.
Обычно достаточно просто открыть файл и он сразу же запустится в одной из этих программ (вверху будет написано, в какой именно).
Для копирования всего текста в Adobe Reader нажимаем вверху на «Редактирование» и выбираем «Копировать файл в буфер обмена».
В Foxit Reader для переноса всего текста нужно нажать на «Главная» вверху, щелкнуть по иконке буфера обмена и выбрать «Выделить все». Затем опять щелкнуть по иконке и выбирать «Копировать».
2. Создаем документ в Ворде. Для этого щелкаем на свободном любом месте Рабочего стола правой кнопкой мыши и выбираем пункт Создать → Документ Microsoft Office Word.
А можно просто открыть программу через Пуск → Все программы → Microsoft Office → Microsoft Office Word.
3. Вставляем в документ тот фрагмент, который мы скопировали из pdf файла. Для этого щелкаем правой кнопкой мыши по листу и в контекстном меню выбираем пункт «Вставить».
В итоге получаем тот же текст, но с возможностью редактирования. Правда, часто он добавляется с немного измененным форматированием и без изображений.
Минусы
- Если документ большой, вставка происходит очень медленно или Ворд просто намертво виснет. А, бывает, даже небольшой текст не вставляется. Выход: выделять/копировать/вставлять по частям.
- Не копируются изображения. Выход: делать их скриншоты, нажав на клавишу клавиатуры Print Screen, после чего вставлять в Ворд (правая кнопка – Вставить). Но придется еще обрезать и менять размер полученной картинки.
- Иногда форматирование страдает очень сильно: шрифты, размер букв, цвета и т. д. Выход: править текст вручную.
Резюме: с обычным текстом такой вариант вполне допустим, но если в документе есть еще и таблицы, списки, изображения, лучше конвертировать другими способами.
Внедрение файла в документ
Вставка файла как объекта (Вставка – Объект) позволяет добавить, точнее, внедрить файл пдф в документ ворда в неизменном виде. Но будет отображаться только первая страница pdf-документа и для просмотра остальных страниц он будет доступен только при двойном клике на нем. После этого внедренный файл откроется во внешней программе-просмотрщике таких файлов, который установлен на вашем компьютере по умолчанию.
Минусы: Видна только первая страница, для просмотра нужна внешняя программа. Если вы отправляете такой документ кому-то, то адресат должен догадаться, что это не одна страница и по ней нужно кликнуть для просмотра всего содержимого.








